一种面部、身体运动参数的联合生成方法及相关设备与流程
本发明涉及语音驱动,尤其涉及的是一种面部、身体运动参数的联合生成方法及相关设备。
背景技术:
1、随着语音识别、语音合成、自然语言处理和人工智能等技术的发展,人与计算机之间语音方式的交流成为可能。语音驱动的人机交互方式为人机交互提供了一种新途径,能有效提高人机交互的便捷性和易用性。目前,语音驱动领域中采用的数据驱动方法是通过设计不同的网络模型来生成面部表情和身体动作。由于不同的网络模型之间信息交互较少,导致生成的面部表情和身体动作的真实度以及自然性受限。
2、因此,现有技术还有待改进和发展。
技术实现思路
1、本发明要解决的技术问题在于,针对现有技术的上述缺陷,提供一种面部、身体运动参数的联合生成方法及相关设备,旨在解决现有的语音驱动方法通过设计不同的网络模型来生成面部表情和身体动作,由于不同的网络模型之间信息交互较少,导致生成的面部表情和身体动作的真实度和自然性受限的问题。
2、本发明解决问题所采用的技术方案如下:
3、第一方面,本发明实施例提供一种面部、身体运动参数的联合生成方法,所述方法包括:
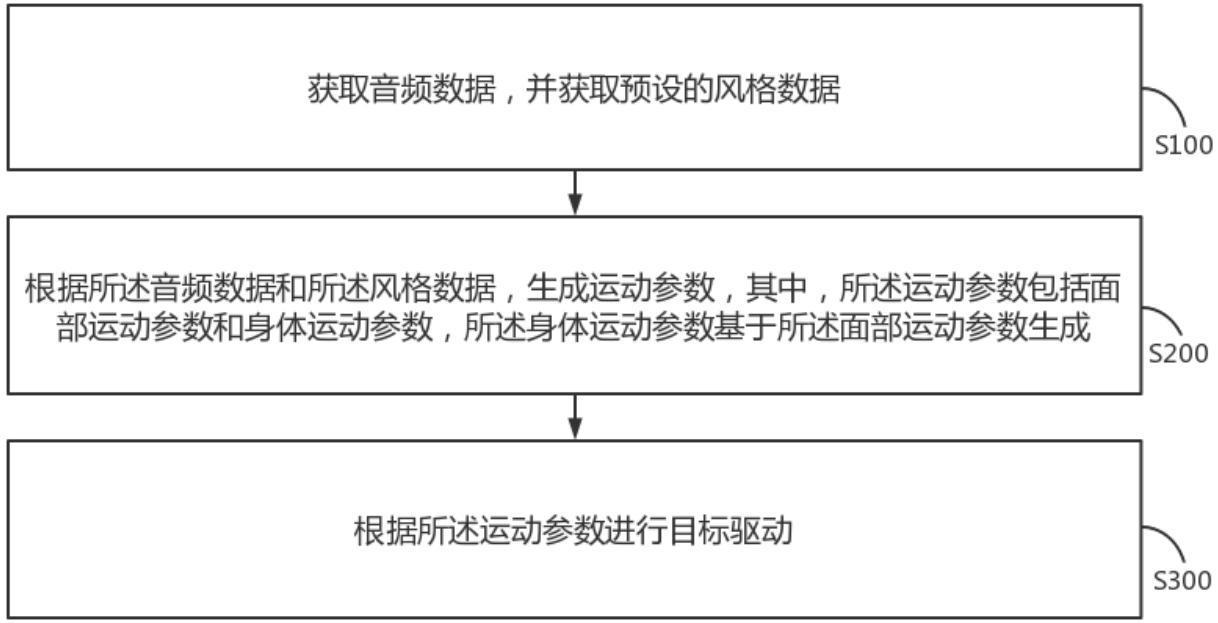
4、获取音频数据,并获取预设的风格数据;
5、根据所述音频数据和所述风格数据,生成运动参数,其中,所述运动参数包括面部运动参数和身体运动参数,所述身体运动参数基于所述面部运动参数生成;
6、根据所述运动参数进行目标驱动。
7、在一种实施方式中,所述根据所述音频数据和所述风格数据,生成运动参数包括:
8、根据所述音频数据确定音频特征信息,并根据所述风格数据确定风格特征信息;
9、将所述音频特征信息和所述风格特征信息输入生成模型,得到所述运动参数,其中,所述生成模型用于:
10、根据所述音频特征信息和所述风格特征信息,确定所述面部运动参数;
11、根据所述音频特征信息、所述风格特征信息以及所述面部运动参数,确定所述身体运动参数。
12、在一种实施方式中,所述根据所述音频数据确定音频特征信息,包括:
13、对所述音频数据进行特征提取,得到若干音频特征数据,其中,当所述音频特征数据的数量大于一时,各所述音频特征数据分别对应不同的特征类型;
14、根据若干所述音频特征数据,确定所述音频特征信息。
15、在一种实施方式中,所述根据所述风格数据确定风格特征信息,包括:
16、对所述风格数据进行编码,得到风格编码数据;
17、对所述风格编码数据进行特征提取,得到所述风格特征信息。
18、在一种实施方式中,所述生成模型为扩散模型,所述面部运动参数为面部噪声数据,所述身体运动参数为身体噪声数据,所述扩散模型用于:
19、根据所述音频特征信息和所述风格特征信息对预设噪声数据进行降噪,得到所述面部噪声数据;
20、根据所述音频特征信息、所述风格特征信息以及所述面部噪声数据对所述预设噪声数据进行降噪,得到所述身体噪声数据。
21、在一种实施方式中,所述扩散模型为逐扩散时间步降噪,所述扩散模型还用于:
22、判断扩散时间步的步数是否达到预设步数;
23、当所述扩散时间步的步数未达到所述预设步数时,将所述面部噪声数据和所述身体噪声数据作为所述预设噪声数据,继续执行所述根据所述音频特征信息和所述风格特征信息对预设噪声数据进行降噪,得到所述面部噪声数据的步骤,直至所述扩散时间步的步数达到所述预设步数。
24、在一种实施方式中,所述方法还包括:
25、当所述音频特征信息大于预设的序列长度时,根据所述序列长度将所述音频特征信息分为若干子序列,其中,任意相邻的两个所述子序列之间具有重叠区域;
26、针对每一所述子序列,将所述子序列作为所述音频特征信息,执行所述将所述音频特征信息和所述风格特征信息输入生成模型的步骤,直至得到所述子序列对应的所述运动参数;
27、通过各所述重叠区域对各所述子序列的所述运动参数进行拼接,得到所述音频数据对应的所述运动参数。
28、在一种实施方式中,针对非首位的每一所述子序列,所述子序列与前一所述子序列的所述重叠区域为复制区域,所述复制区域对应的所述运动参数基于前一所述子序列中对应区域的所述运动参数确定。
29、在一种实施方式中,所述子序列中除所述复制区域之外的区域为生成区域;所述生成区域对应的所述运动参数基于所述扩散模型生成,所述生成区域对应的所述预设噪声数据的确定方法包括:
30、根据前一所述子序列的所述运动参数,确定第一运动参数和第二运动参数的加权融合数据,其中,所述第一运动参数为前一所述子序列中所述复制区域对应的所述运动参数,所述第二运动参数为前一所述子序列中所述生成区域对应的所述运动参数;
31、根据所述加权融合数据,确定所述生成区域对应的所述预设噪声数据。
32、在一种实施方式中,针对末位的所述子序列,当所述子序列小于所述序列长度时,根据所述子序列的长度调整所述扩散模型的位置编码数量。
33、在一种实施方式中,所述根据所述运动参数进行目标驱动,包括:
34、将所述运动参数输入三维渲染器;
35、通过所述三维渲染器将所述运动参数重定向至虚拟目标,以实现对所述虚拟目标进行驱动。
36、在一种实施方式中,所述根据所述运动参数进行目标驱动,包括:
37、将所述运动参数输入神经网络生成器;
38、通过所述神经网络生成器将所述运动参数投影至图像像素坐标系,得到若干帧驱动图像;
39、根据各帧所述驱动图像对虚拟目标进行驱动。
40、第二方面,本发明实施例还提供一种面部、身体运动参数的联合生成装置,所述装置包括:
41、获取模块,用于获取音频数据和风格数据;
42、生成模块,用于根据所述音频数据和所述风格数据,生成运动参数,其中,所述运动参数包括面部运动参数和身体运动参数,所述身体运动参数基于所述面部运动参数生成;
43、驱动模块,用于根据所述运动参数进行目标驱动。
44、第三方面,本发明实施例还提供一种终端,所述终端包括有存储器和一个以上处理器;所述存储器存储有一个以上的程序;所述程序包含用于执行如上述任一所述的面部、身体运动参数的联合生成方法的指令;所述处理器用于执行所述程序。
45、第四方面,本发明实施例还提供一种计算机可读存储介质,其上存储有多条指令,所述指令适用于由处理器加载并执行,以实现上述任一所述的面部、身体运动参数的联合生成方法的步骤。
46、本发明的有益效果:本发明实施例通过获取音频数据,并获取预设的风格数据;根据音频数据和风格数据,生成运动参数,其中,运动参数包括面部运动参数和身体运动参数,身体运动参数基于面部运动参数生成;根据运动参数进行目标驱动。本发明可以根据音频数据和风格数据联合生成面部运动参数和身体运动参数,并在生成身体运动参数时会参考面部运动参数,从而使得音频驱动面部表情和身体动作的效果能够达到更高的同步性,更接近面部、身体的真实运动状态。
- 还没有人留言评论。精彩留言会获得点赞!