一种基于强化学习的隐患实体标注方法与流程
本发明属于石油工程,尤其是涉及一种基于强化学习的隐患实体标注方法。
背景技术:
1、在海洋油气生产领域,隐患文本的处理和分析一直是一个重要而复杂的任务。随着全球能源需求的不断增长,海洋油气生产已成为满足能源需求的重要来源之一。然而,由于海洋环境的复杂性和生产过程的高风险性,隐患在海洋油气生产中时有发生,其可能导致严重的环境事故和人员伤亡,对生产企业和环境造成巨大的损失。
2、当前,海洋油气生产企业面临的一个主要挑战是如何及时准确地识别和提取隐患信息。隐患信息通常包含在大量的技术报告、巡检记录、事故报告和维修日志等文本数据中。这些文本数据通常存在着大量的噪音和非结构化信息,使得隐患信息的提取变得更加困难。
3、现阶段,为了提取隐患文本中的隐患实体,大致通过关键词匹配法、基于规则的语法解析法及基于机器学习的方法实现。关键词匹配法通过事先定义一组与隐患相关的关键词或短语,并在文本中进行匹配来提取隐患实体。可以使用基于规则的匹配算法或正则表达式等进行实现。基于规则的语法解析法基于自然语言处理技术,使用语法规则和解析器来分析文本的语法结构,从中提取隐患实体。可以利用词性标注、句法分析等技术辅助实现。基于机器学习的方法通过对已标注的隐患文本样本进行训练,建立模型来识别和提取隐患实体。
4、上述关键词匹配法,依赖于人工定义的关键词列表,可能无法覆盖所有可能的隐患实体,导致提取的结果不完整或不准确。此外,对于复杂的文本语境和变化多样的表达方式,关键词匹配可能无法有效捕捉隐患实体,难以处理词形变化、近义词、缩写词等语言变体,限制了提取的准确性和泛化能力,导致漏提或误提。上述基于规则的语法解析法需要事先定义和编码一组复杂的语法规则,对领域知识和语言结构的要求较高,构建和维护规则的成本较高,此外难以应对领域专业术语、新词汇和复杂的语言变体,可能导致提取的漏洞和误提。上述基于机器学习的方法实现需要大量标注样本数据进行训练,收集和标注数据的成本较高。对于领域特定的隐患实体,需要有足够的样本数据进行训练,否则模型可能泛化能力较差。
技术实现思路
1、本发明要解决的问题是提供一种基于强化学习的隐患实体标注方法,该方法不需要大量人工标注数据,可以直接在未标注的数据上训练;不依赖于事先定义的规则或标注样本,对新领域和新隐患类型具有较好的适应性,能够逐步学习和优化标注实体的策略,适应不同的隐患文本特点,根据实际情况进行实体标注,逐步学习和识别未知实体。
2、本发明提供一种基于强化学习的隐患实体标注方法,包括以下步骤,
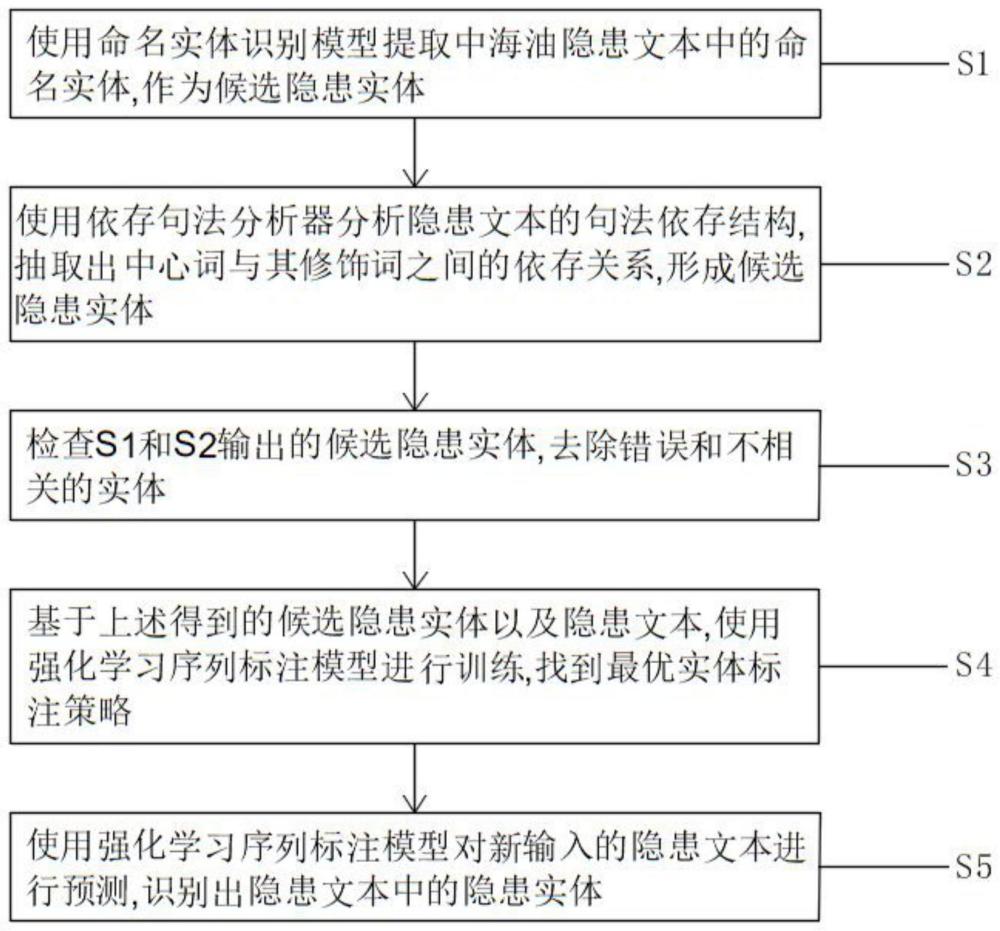
3、s1:使用命名实体识别模型提取a隐患文本中的命名实体,作为候选隐患实体;
4、s2:使用依存句法分析器分析隐患文本的句法依存结构,抽取出中心词与其修饰词之间的依存关系,形成候选隐患实体;
5、s3:检查所述s1和所述s2输出的候选隐患实体,去除错误和不相关的实体;
6、s4:基于上述得到的候选隐患实体以及隐患文本,使用强化学习序列标注模型进行训练,找到最优实体标注策略;
7、s5:使用所述强化学习序列标注模型对新输入的隐患文本进行预测,识别出隐患文本中的隐患实体。
8、进一步的,所述s1包括以下步骤,
9、s11:对a隐患文本数据集构建一个实体字典,使得模型能够识别出a专属实体;
10、s12:使用bert模型作为命名实体识别模型,使用a隐患文本以及所述实体字典对bert模型进行fine-tuning,得到一个适用于a隐患文本的命名实体标注模型;
11、s13:使用训练好的bert模型对a隐患文本进行命名实体识别,提取出a隐患文本中的候选实体并将错误的以及不相关的实体筛选出去。
12、进一步的,所述s2包括以下步骤,
13、s21:使用ltp依存句法分析器对a隐患文本进行依存句法分析,解析出各个词之间的依存关系,并以树状图的形式表示句子的依存结构;
14、s22:在依存关系树状图中选取中心词为实体的候选词,再找出与这个候选词直接依存关系的修饰词,形成候选隐患实体。
15、进一步的,在所述s2中,得到的候选隐患实体与s1识别的命名实体一同输入到强化学习序列标注模型中,用于实体边界的精确识别和非命名实体的抽取。
16、进一步的,所述s4包括以下步骤,
17、s41:将上述输出的候选隐患实体作为强化学习模型的输入状态,隐患文本作为环境;
18、s42:定义动作空间;
19、s43:定义状态转移;
20、s44:定义奖励函数;
21、s45:模型初始化后,通过和环境的动态交互进行训练,在每个时步,模型根据当前状态选择一个标注动作,环境返回下一状态和奖励,模型根据奖励更新策略,学习选择最优动作。
22、进一步的,在所述s42中,所述定义动作空间为每个实体选择与其它实体合并或保持独立,动作空间为实体间形成的所有组合。
23、进一步的,在所述s44中,所述定义奖励函数为当模型转移到正确的状态时给予模型最大奖励,其他状态给予较小奖励,不转移给予负向奖励。
24、进一步的,本发明还提供一种装置,运行上述的数据处理方法。
25、进一步的,本发明还提供一种设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的算法,所述处理器执行所述计算机程序时实现所述的数据处理方法。
26、进一步的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机算法,所述计算机算法被处理器执行时实现所述的数据处理方法。
27、本发明具有的优点和积极效果是:
28、本发明设计的基于强化学习的隐患实体标注方法,不需要大量人工标注数据,可以直接在未标注的数据上训练;不依赖于事先定义的规则或标注样本,因此对于新领域和新隐患类型具有较好的适应性,能够逐步学习和优化标注实体的策略,适应不同的隐患文本特点,根据实际情况进行实体标注,逐步学习和识别未知实体。
技术特征:
1.一种基于强化学习的隐患实体标注方法,其特征在于:包括以下步骤,
2.根据权利要求1所述的一种基于强化学习的隐患实体标注方法,其特征在于:所述s1包括以下步骤,
3.根据权利要求1或2所述的一种基于强化学习的隐患实体标注方法,其特征在于:所述s2包括以下步骤,
4.根据权利要求3所述的一种基于强化学习的隐患实体标注方法,其特征在于:在所述s2中,得到的候选隐患实体与s1识别的命名实体一同输入到强化学习序列标注模型中,用于实体边界的精确识别和非命名实体的抽取。
5.根据权利要求1或2所述的一种基于强化学习的隐患实体标注方法,其特征在于:所述s4包括以下步骤,
6.根据权利要求5所述的一种基于强化学习的隐患实体标注方法,其特征在于:在所述s42中,所述定义动作空间为每个实体选择与其它实体合并或保持独立,动作空间为实体间形成的所有组合。
7.根据权利要求5所述的一种基于强化学习的隐患实体标注方法,其特征在于:在所述s44中,所述定义奖励函数为当模型转移到正确的状态时给予模型最大奖励,其他状态给予较小奖励,不转移给予负向奖励。
8.一种装置,其特征在于:运行如权利要求1至7任意一项所述的数据处理方法。
9.一种设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的算法,其特征在于:所述处理器执行所述计算机程序时实现如权利要求1至7任意一项所述的数据处理方法。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机算法,其特征在于,所述计算机算法被处理器执行时实现如权利要求1至7任意一项所述的数据处理方法。
技术总结
本发明提供一种基于强化学习的隐患实体标注方法,包括以下步骤,使用命名实体识别提取出隐患文本中的实体;使用依存句法器分析隐患文本获取隐患实体;对依存句法器输出的隐患实体进行人工筛选,去除错误的隐患实体;将命名实体识别提取出的实体和依存句法器提取的隐患实体输入到强化学习序列标注模型中进行训练;使用训练好的强化学习序列标注模型对隐患文本进行预测得到隐患实体。本发明不需大量人工标注数据,可直接在未标注的数据上训练;不依赖于事先定义的规则或标注样本,因此对于新领域和新隐患类型具有较好的适应性,能够逐步学习和优化标注实体的策略,适应不同的隐患文本特点,根据实际情况进行实体标注,逐步学习和识别未知实体。
技术研发人员:毛邓添,睢星飞,王海琛,王磊,徐志鹏,何睿,陈军,曾令旗,贺鹏艺,李晓亮
受保护的技术使用者:中海油安全技术服务有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!