一种基于半监督对比学习的旋转设备小样本故障诊断方法与流程
本发明属于滚动轴承故障诊断,具体涉及一种基于半监督对比学习的旋转设备小样本故障诊断方法。
背景技术:
1、在现代工业生产中,大型旋转设备扮演者重要的角色。然而,随着这些设备的复杂性不断增加,机械故障诊断对于工业设备的重要性也日益突出。在实际运行中,准确检测机械故障能够降低经济损失和事故发生的概率。随着人工智能技术的迅猛发展,许多算法开始应用于机械故障诊断领域。人工智能的诊断方法与传统方法有所不同,传统方法更依赖于专家知识和经验,而基于深度学习的智能诊断方法在近年来迅速发展,与传统的机器学习方法(如支持向量机、k均值和决策树)相比,深度学习方法具备更强大的特征提取能力,无需进行人工特征工程,降低了建模的难度,并提高了故障诊断的性能。一些常见的深度学习方法包括自动编码器、卷积神经网络和递归神经网络等,在有足够标记样本的情况下已经广泛应用于机械故障诊断,并取得了良好的性能,然而,在实际设备运行过程中,所采集的数据大多是健康数据,而各类故障数据的数量往往远少于健康数据。此外,故障样本往往没有标签或者只有很少的标签,这种情况非常常见。因此,仅有少量标记的故障数据可用于模型训练,导致模型难以学习到有效的判别特征信息。
2、近年来,针对小样本情况下的故障诊断问题取得了一些进展,比如度量学习和对比学习被广泛应用于小样本任务。其中,原型网络(prototypica lnetworks)作为基于度量的机器学习方法,通过学习每类样本的特征原型并计算这些原型与测试样本之间的距离来完成分类任务。通过计算样本距离,模型可以快速将未知样本与正确的类别进行匹配。在原型学习步骤中,特征提取和距离计算对于学习不同类的原型具有重要意义。除此以外,基于对比学习的训练策略,可以在不生成新数据的情况下实现数据增强,通过样本差异性引导模型训练,在较小的数据量下模型也能够达到良好的泛化性能。半监督学习确实是解决数据稀缺问题的另一种有效途径。在小样本问题中,虽然标记数据非常有限,但存在大量的无标签数据可用,而半监督学习方法可以充分利用这些无标签数据来增强模型的泛化能力和性能,半监督学习和原型网络的结合是用于故障诊断的一个新思路,利用伪标签学习来解决支撑数据太少导致原型精度不够的问题。
技术实现思路
1、本发明要解决的技术问题是提供一种基于半监督对比学习的旋转设备小样本故障诊断方法,解决旋转机械设备故障数据稀缺导致的模型过拟合和诊断精度不够的问题。
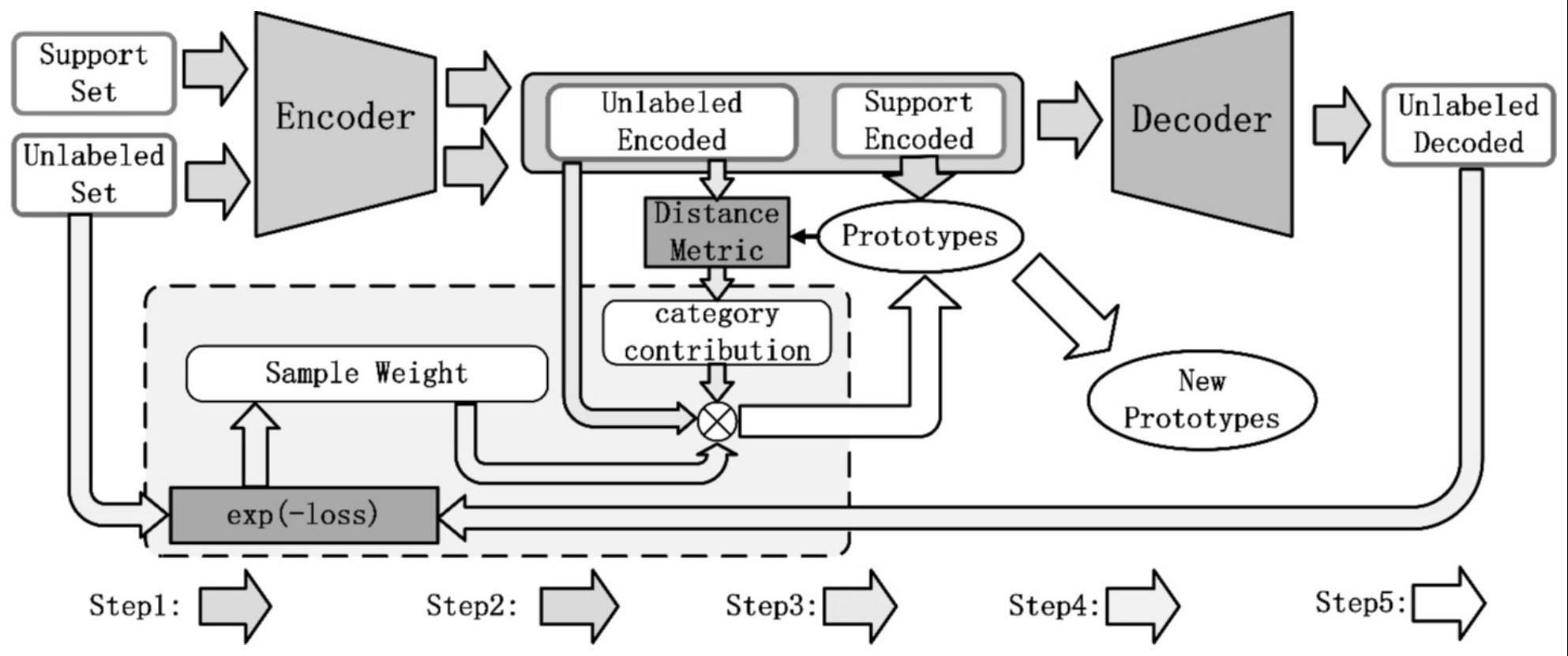
2、为解决上述技术问题,本发明的实施例提供一种基于半监督对比学习的旋转设备小样本故障诊断方法,包括如下步骤:
3、s1、构建两阶段训练数据集:
4、s1.1、构建基于对比学习的正负样本对,记为预训练数据集;
5、s1.2、构建基于小样本学习的任务数据集;
6、s2、利用预训练数据集预训练改进的自动编码器,将s1.2构建的任务数据输入预训练后的自动编码器和原型网络中得到初始化原型;
7、s3、使用预训练后的自动编码器对标记数据计算类别原型,对无标签样本计算类别贡献度和样本权重,联合无标签样本的类别贡献度和样本权重优化各类故障的类别原型。
8、其中,步骤s1.1中,将相同标签数据构建成正样本对,不同标签数据构建成负样本对。
9、进一步,步骤s1.1的具体步骤为:
10、首先收集所有标记样本dlabeled,标签y∈{0,1,2,…n},将其中任意两个标记样本组成一个样本对xij={xi,xj},如果yi≠yj,则此样本对为负样本对,样本对标签为yij=0;否则为正样本对,标签为yij=1。
11、其中,步骤s1.2的具体步骤为:
12、以任务为基础单元,每个任务数据集包含支撑集ds、查询集dq和无标记集du三部分,先从标记数据中随机采样出nc×ns个样本作为支撑集ds,其中,nc为类的数目,ns为支撑集每个类别中的样本个数;然后从剩下的数据中随机采样nc×ns个样本作为查询集dq,其余的无标签数据作为无标记集du。
13、其中,步骤s2中,改进的自动编码器包括编码器、卷积注意力机制模块cbam和解码器,其中,
14、所述编码器对预训练数据集进行降维,获得低维度的故障信息,即嵌入特征;
15、所述卷积注意力机制模块cbam用于加强特征筛选能力;
16、所述解码器包括三层反卷积模块,对嵌入特征进行数据重构;
17、卷积注意力机制模块cbam由一个串联通道注意力模块和空间注意力模块串联组成,依次沿通道和空间两个维度计算注意力图,然后将注意力图乘以输入特征图进行自适应特征筛选;结合卷积注意力机制模块cbam的编码器和解码器的计算过程如下:
18、
19、
20、其中,xs∈rc×w为输入的原始样本;f(·)为编码映射函数;fcb(·)为一个卷积模块,由卷积层、批量归一化层和relu激活函数组成;xe为编码器输出;g(·)为解码映射函数;为反卷积模块,由反卷积层、批量归一化层和激活函数组成;
21、自编码器重构误差lossrc计算如下:
22、
23、进一步,步骤s2中,对比学习训练框架为:首先将步骤s1-1中构建的样本对xij={xi,xj}同时输入至mdae中,得到一对嵌入特征{zi,zj},编码器输出原始嵌入特征,具体计算过程如下:
24、{zi,zj}=f({xi,xj});
25、在得到基本的嵌入特征对后,使用欧式距离度量函数d(zi,zj)计算两潜在特征的差异性,对于正样本对,目的是最小化正样本对的差异性,即特征的欧氏距离;正样本对的损失函数losspositive表示为:
26、losspositive(xij)={d(f(xi),f(xj))}2,xij={xi,xj};
27、对于负样本对,对比训练的目标是最小化特征相似性,即最大化欧式距离;负样本对的损失函数lossnegative表示为:
28、lossnegative(xij)={max(0,1-d(f(xi),f(xj)))}2,xij={xi,xj};
29、因此,最后的对比学习预训练的损失函数losscontrastive如下:
30、
31、其中,n+为正样本对的数目,n-为负样本对的数目。
32、其中,步骤s3中,改进的自动编码器作为编码映射函数,原型网络用于计算类别原型,并利用距离度量函数d(·)进行故障诊断;
33、s3.1、类别原型的计算过程如下:
34、
35、其中,f(·)表示编码映射函数,c表示一种故障类别,表示支撑集中类别为c的样本数目;
36、s3.2、利用类别原型计算所提供的样本xs属于故障类别c的概率,计算过程如下:
37、
38、s3.3、原型网络的分类损失函数由查询集数据计算,并通过最小化负对数概率进行学习,损失函数计算过程如下:
39、
40、用于原型网络中编程器参数的优化。
41、s3.4、类别原型的优化:
42、s3.4.1、计算样本伪标签作为无标签样本对各个故障类别的样本贡献度,计算过程如下所示:
43、
44、其中,xu为无标签样本,d(·)表示欧式距离度量函数;
45、s3.4.2、通过自动编码器的重构误差得到样本权重w,计算过程如下所示:
46、lossrc=mse(xu,decoder(encoder(xu)));
47、
48、s3.4.3、将样本贡献度和样本权重联合计算得到无标签样本xu,i对各类别原型的贡献度计算过程如下所示:
49、
50、s3.4.4、重新利用支撑集样本和无标签样本优化类别原型,计算过程如下:
51、
52、本发明还提供一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现上述的基于半监督对比学习的旋转设备小样本故障诊断方法。
53、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的基于半监督对比学习的旋转设备小样本故障诊断方法。
54、本发明的上述技术方案的有益效果如下:
55、本发明提供一种基于半监督对比学习的旋转设备小样本故障诊断方法,针对旋转机械设备故障数据稀缺情况下,基于样本对和小样本学习进行训练数据构造,并将改进自动编码器作为特征提取函数,使用对比学习的训练模式,使得编码器学习到故障数据的判别特征信息,加强模型的特征提取能力,并避免小样本数据导致的模型过拟合问题。通过对比学习预训练之后的自动编码器用于原型的编码映射函数,编码器将输入高维数据压缩至较低维向量,然后计算出初始化原型,并利用无标签样本与原型距离来计算类别贡献度,样本的重构误差来估计样本权重,最后对原型进行微调精化,得到更加精确的原型。最后在多种小样本实验中证明了本发明的有效性和优越性,仅使用少量标记样本进行离线训练,就可以实现高精度的在线故障分类。
- 还没有人留言评论。精彩留言会获得点赞!