纵向联邦学习数据处理方法及纵向联邦学习系统
本发明属于信息安全技术邻域,具体涉及一种纵向联邦学习数据处理方法及纵向联邦学习系统。
背景技术:
1、数据是现代社会中推动机器学习发展的关键资源。随着越来越多数据保护法规如gdpr的颁布,数据隐私保护的问题越来越受到众多社会组织关注。这些社会组织通常拥有大量敏感和个人化的信息,如银行,医院和学校等等。鉴于这些实体处理的大量敏感和个性化数据,确保数据隐私已成为一个不断升级的问题。
2、联邦学习,用以解决机器学习中的数据隐私泄露问题。联邦学习通过将数据和模型保留在客户的本地设备上,实现了去中心化的数据存储和模型训练。这样就可以在保护数据隐私和安全的前提下,实现模型的合作共享和协同学习。根据数据划分方式的不同,联邦学习又可以被分为横向和纵向的联邦学习。一般而言,横向联邦学习(hfl)适用于一些同组织下的协同学习场景。然而,现实世界中不同的组织协同学习场景也很常见,这种时候便需要使用纵向联邦学习方案(vfl)。考虑如下一个现实场景:来自不同机构的银行需要一起训练一个机器学习模型,以预测是否能向某个来访用户借贷。这些银行的数据通常都拥有不同的特征空间,但存在许多相同的样本空间。纵向联邦学习就是为这样的场景应用而设计的。
3、不过,尽管数据仍然保留在本地,许多新的研究表明各参与方之间传输的中间参数仍然会泄露部分隐私信息。尤其是在基于树模型的纵向联邦学习中,梯度、数据桶和划分信息等更是不能直接传输给其他参与方,因为这些信息通常都包含了参与方私人的敏感数据。为了解决这样的隐私问题,最近的研究提出了一些隐私保护的纵向联邦学习框架。有些研究基于同态加密技术设计隐私保护方案,达到了纵向联邦学习中的数据保护需求。然而,同态加密需要大量的计算开销,这对资源有限的参与方来说是个不小的挑战。另一些研究则利用差分隐私技术对数据隐私进行保护。不过,差分隐私会不可避免地引入噪声,模型也因此而无法在准确率测试时达到最好的效果。此外,还有一些基于多方安全计算的纵向联邦学习场景的方案。由于在该类方案中,参与方都是直接参与到计算和通信中,故需要消耗大量的本地资源,这样同样给参与方带来了巨大的开销。
4、加密手段是对纵向联邦学习传播过程中的一些数据进行隐私保护的最广泛使用的手段。纵向联邦学习的特性和安全需求也使得许多密码技术都可以得到有效应用,如同态加密,函数加密和秘密共享等。但是很多采用了加密手段的方案又均涉及模型训练精度问题,例如限制隐私保护纵向联邦学习方案发展的主要瓶颈便是模型的精度以及计算和通信开销,尤其是对资源有限的参与方而言,开销过大会显著降低运行效率。此外,当前某些方案还潜在有隐私泄露的风险。具体说来,现有技术的缺陷和不足展现为以下节点:
5、1.不能提供充分的隐私保证。在纵向联邦学习场景中,中间参数的传输都有可能导致隐私的泄露。当前许多工作针对这个问题提出了隐私保护的纵向联邦学习方案,然而效果不理想。
6、2.不能确保训练得到高准确率的学习模型。准确率是评价方案设计的重要指标,直接决定了方案是否能得到落地应用。当前许多纵向联邦学习的方案使用差分隐私技术进行隐私保护,然而差分隐私技术不可避免的会往模型中加入噪声,会对最后训练得到的模型产生准确度损失的影响。
7、3.联邦学习效率较低,时间和通信开销较大。尤其对于资源有限的参与方来说,通常需要花费较大的开销,很可能引起联邦学习无法正常进行。目前,许多工作都考虑了如何提供纵向联邦学习效率,然而这些方案都不能很好的降低参与方的开销。
技术实现思路
1、本发明要解决的技术问题是提供一种应用于纵向联邦学习中,实现兼顾隐私保护、模型训练精度高及高学习效率的纵向联邦学习数据处理方法及纵向联邦学习系统。
2、本发明的内容包括一种纵向联邦学习数据处理方法,应用于纵向联邦学习系统中,所述纵向联邦学习系统包括由至少两个服务器构成的非共谋服务器组及多个参与方设备,所述多个参与方设备包括主动方设备及多个被动方设备,所述方法包括:
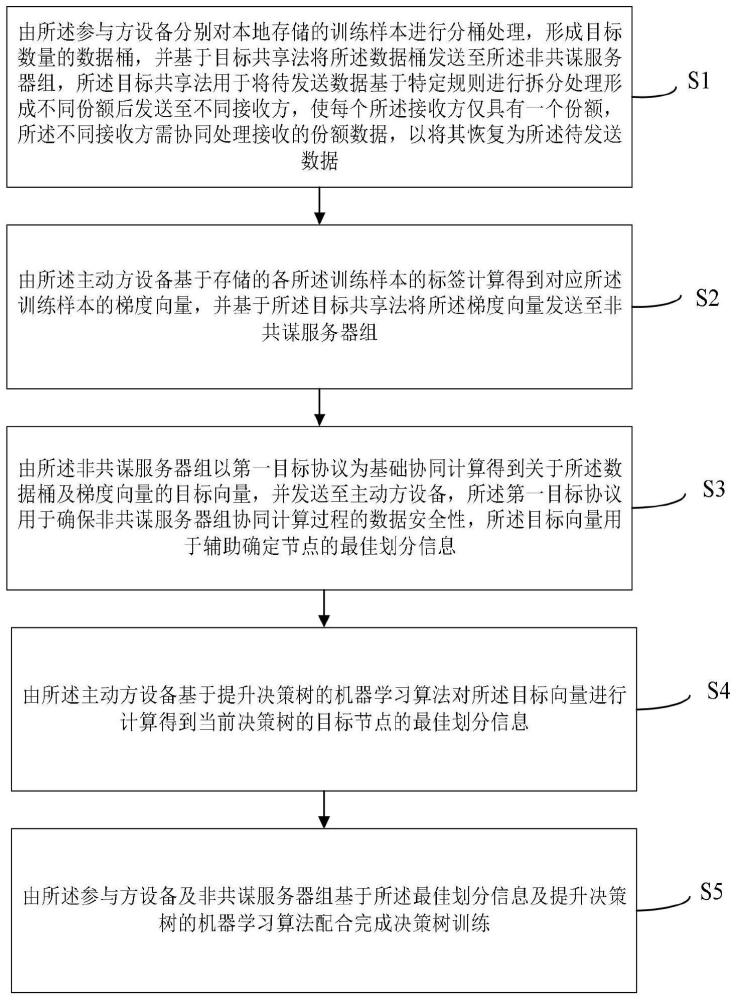
3、由所述参与方设备分别对本地存储的训练样本进行分桶处理,形成目标数量的数据桶,并基于目标共享法将所述数据桶发送至所述非共谋服务器组,所述目标共享法用于将待发送数据基于特定规则进行拆分处理形成不同份额后发送至不同接收方,使每个所述接收方仅具有一个份额,所述不同接收方需协同处理接收的份额数据,以将其恢复为所述待发送数据;
4、由所述主动方设备基于存储的各所述训练样本的标签计算得到对应所述训练样本的梯度向量,并基于所述目标共享法将所述梯度向量发送至非共谋服务器组;
5、由所述非共谋服务器组以第一目标协议为基础协同计算得到关于所述数据桶及梯度向量的目标向量,并发送至主动方设备,所述第一目标协议用于确保非共谋服务器组协同计算过程的数据安全性,所述目标向量用于辅助确定节点的最佳划分信息;
6、由所述主动方设备基于提升决策树的机器学习算法对所述目标向量进行计算得到当前决策树的目标节点的最佳划分信息;
7、由所述参与方设备及非共谋服务器组基于所述最佳划分信息及提升决策树的机器学习算法配合完成决策树训练。
8、在一实施例中,由所述参与方设备对本地存储的训练样本进行分桶处理,包括:
9、初始化第一数值作为所述参与方设备的第f个特征的固定阈值数量;
10、基于所述固定阈值数量将所述训练样本划分为目标数量的数据桶,所述目标数量的数值为所述第一数值。
11、在一实施例中,所述非共谋服务器组包括第一服务器及第二服务器,所述基于目标共享法将所述数据桶发送至所述非共谋服务器组,包括:
12、基于每个所述数据桶分别构建布尔数据桶矩阵;
13、基于加法秘密共享法对每个所述布尔数据桶矩阵进行计算,以分别得到对应每个所述布尔数据桶矩阵的第一数据桶份额及第二数据桶份额;
14、将每个所述布尔数据桶矩阵的第一份额及第二份额均分别发送至所述第一服务器及第二服务器。
15、在一实施例中,所述基于所述目标共享法将所述梯度向量发送至非共谋服务器组,包括:
16、基于加法秘密共享法对每个所述梯度向量进行计算,以分别得到对应每个所述梯度向量的第一共享份额及第二共享份额;
17、将每个所述梯度向量的第一共享份额及第二共享份额分别发送至所述第一服务器及第二服务器。
18、在一实施例中,所述由所述非共谋服务器组以第一目标协议为基础协同计算得到关于所述数据桶及梯度向量的目标向量,并发送至主动方设备,包括:
19、所述第一服务器与第二服务器分别获得所述主动方设备基于加法秘密共享法发送的对应各节点的样本独热编码份额;
20、所述第一服务器与第二服务器分别基于自身的样本独热编码份额及各布尔数据桶矩阵的份额协同计算当前树的各节点的独特桶矩阵,并得到各自的独特桶矩阵份额;
21、所述第一服务器与第二服务器基于mux协议对各自的梯度向量份额及各个所述独特桶矩阵份额进行处理,以分别得到不同的所述独特桶矩阵和梯度向量的乘积向量的共享份额;
22、所述第一服务器与第二服务器分别将自身存储的所有所述共享份额汇总求和得到所述乘积向量的份额,并分别发送至所述主动方设备。
23、在一实施例中,所述由所述参与方设备及非共谋服务器组基于所述最佳划分信息及提升决策树的机器学习算法配合完成决策树训练,包括:
24、所述主动方设备将最佳划分信息中的最佳阈值及特征索引发送至目标参与方设备,同时将所述特征索引基于加法秘密共享法发送至非共谋服务器组,所述目标参与方设备为被动方设备;
25、所述目标参与方设备将匹配索引特征的阈值基于加法秘密共享法发送至非共谋服务器组;
26、所述非共谋服务器组基于获得的特征索引份额及阈值份额协同建立所述新节点,并基于已建立的节点的信息建立阈值共享份额查询树;
27、由所述参与方设备及非共谋服务器组基于提升决策树的机器学习算法配合进行迭代计算,并在到达叶节点时由所述主动方设备确定叶节点权重,直至当前决策树的深度满足阈值,训练完成。
28、在一实施例中,所述方法还包括:
29、由所述第一服务器与第二服务器分别获得用户端基于所述加法秘密共享法对待查询样本的每个特征值计算的第三份额及第四份额;
30、由所述第一服务器与第二服务器分别基于各个所述第三份额及第四份额在构建的阈值共享份额查询树中查询确定出对应各所述特征值的阈值份额;
31、由所述第一服务器与第二服务器基于第二目标协议,分别计算各个所述第三份额、第四份额和对应同一所述特征值的阈值份额的比对结果的共享份额,并发送至主动方设备,所述第二目标协议基于加法秘密共享法及mill协议生成,用于根据输入的不同类型份额数据计算输出其比对结果的份额;
32、由所述主动方设备基于获得的共享份额确定答复数据,并发送至所述用户端。
33、在一实施例中,所述由所述主动方设备基于获得的共享份额确定答复数据,并发送至所述用户端,包括:
34、对获得的共享份额基于加法秘密共享法进行恢复,得到所述比对结果;
35、基于所述比对结果确定是否更新已建立的决策树的根节点;
36、当更新后的或未更新的所述根节点满足预置条件时,计算当前所有所述决策树的权重之和,并将所述权重之和作为答复数据发送至所述用户端。
37、本发明另一实施例同时提供一种纵向联邦学习系统,包括由至少两个服务器构成的非共谋服务器组及多个参与方设备,所述多个参与方设备包括主动方设备及多个被动方设备,其中:
38、所述参与方设备用于分别对本地存储的训练样本进行分桶处理,形成目标数量的数据桶,并基于目标共享法将所述数据桶发送至所述非共谋服务器组,所述目标共享法用于将待发送数据基于特定规则进行拆分处理形成不同份额后发送至不同接收方,使每个所述接收方仅具有一个份额,所述不同接收方需协同处理接收的份额数据,以将其恢复为所述待发送数据;
39、所述主动方设备用于根据存储的各所述训练样本的标签计算得到对应训练样本的梯度向量,并基于所述目标共享法将所述梯度向量发送至非共谋服务器组;
40、所述非共谋服务器组用于以第一目标协议为基础协同计算得到关于所述数据桶及梯度向量的目标向量,并发送至主动方设备,所述第一目标协议用于确保非共谋服务器组协同计算过程的数据安全性,所述目标向量用于辅助确定节点的最佳划分信息;
41、所述主动方设备还用于根据提升决策树的机器学习算法对所述目标向量进行计算,以得到当前决策树的目标节点的最佳划分信息;
42、所述参与方设备及非共谋服务器组还用于根据所述最佳划分信息及提升决策树的机器学习算法配合完成决策树训练。
43、在一实施例中,所述非共谋服务器组包括第一服务器及第二服务器,所述目标共享法为加法共享法;
44、所述第一服务器与第二服务器用于:
45、分别获得用户端基于所述加法共享法对待查询样本的每个特征值计算的第三份额及第四份额;
46、分别基于各个所述第三份额及第四份额在构建的阈值共享份额查询树中查询确定出对应各所述特征值的阈值份额;
47、基于第二目标协议,分别计算各个所述第三份额、第四份额和对应同一所述特征值的阈值份额的比对结果的共享份额,并发送至主动方设备,所述第二目标协议基于加法秘密共享法及mill协议生成,用于根据输入的不同类型份额数据计算输出其比对结果的份额;
48、所述主动方设备还用于根据获得的共享份额确定答复数据,并发送至所述用户端。
49、本发明的有益效果是通过引入非共谋服务器组及用于实现数据传输安全的目标共享法,使得本技术的纵向联邦学习数据处理方法能够在保证已有训练精度的情况下,兼顾隐私数据保护、降低参与方设备的通信开销,使得纵向联邦学习系统能够在基于现有学习方法的基础上提升学习效率,实现在模型训练精度不变的情况下,针对原始数据、梯度信息、数据桶信息、划分信息和模型参数实现计算以及数据交互时的严格保护,同时将学习过程中数据交互的工作重心交由非共谋的服务器组实施,进而极大降低参与方设备的通信开销,节省了通信时长,进而提升了学习效率。
- 还没有人留言评论。精彩留言会获得点赞!