多模态后融合的长尾类别检测方法和系统与流程
本技术涉及长尾检测,特别是涉及一种多模态后融合的长尾类别检测方法和系统。
背景技术:
1、智能驾驶技术是未来汽车产业的重要发展方向之一,智能驾驶汽车必须准确的检测出常见类和稀有类的物体才能安全行驶,而目前常见的基于激光雷达的三维目标检测方法在稀有类别上表现不佳,一方面是因为稀有类别的目标数量较少,训练难度大,另一方面是因为激光雷达传感器无法获得颜色,纹理等特征,因此对于救护车,警车等稀有类别难以准确分类。
2、在当前研究中,“长尾”类别检测效果较好的是论文《towards long-tailed 3ddetection》提出的方法,该方法采用单目图像做三维检测,将检测结果和激光雷达检测结果做后融合得到“长尾”类别的检测结果,其缺点是单目图像三维检测的模型训练难度大,检测精度较低,会影响最终融合的检测结果。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够减小模型训练难度、提高长尾检测精度的多模态后融合的长尾类别检测方法和系统。
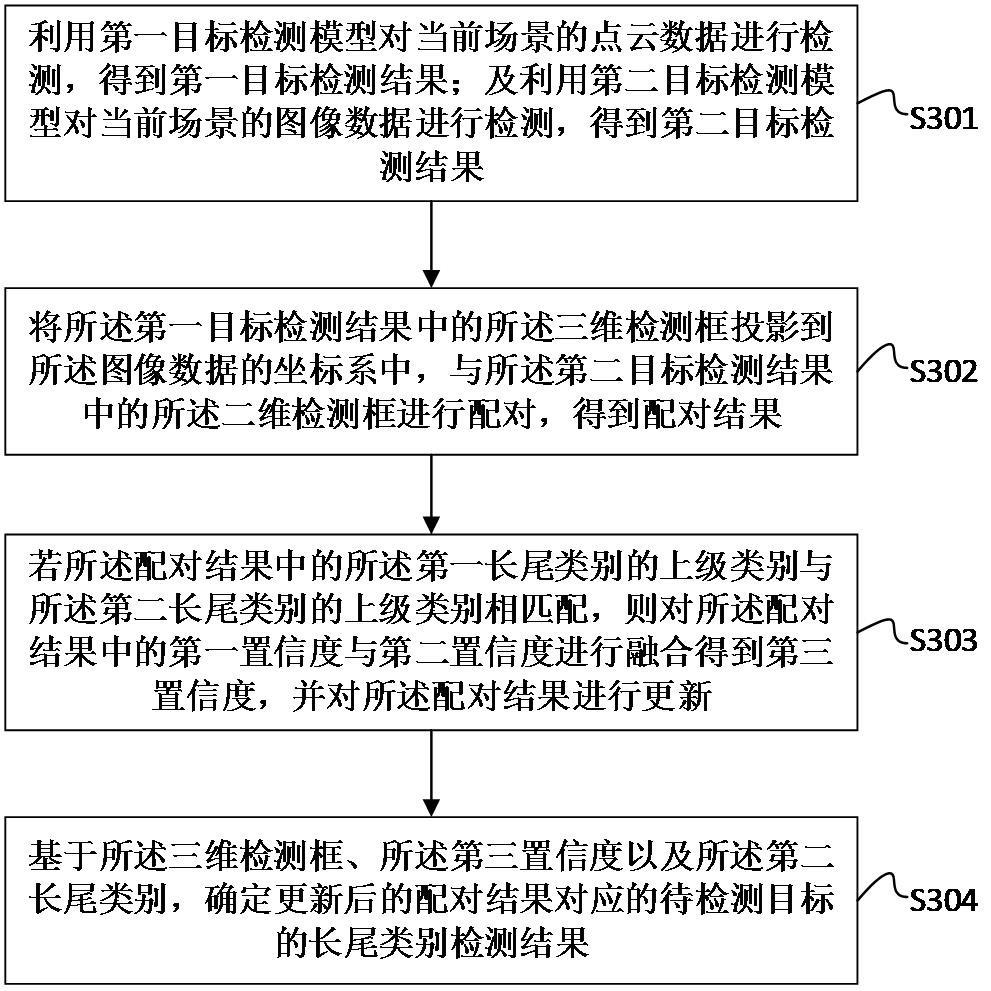
2、第一方面,本技术提供了一种多模态后融合的长尾类别检测方法,所述方法包括:
3、利用第一目标检测模型对当前场景的点云数据进行检测,得到第一目标检测结果;及利用第二目标检测模型对当前场景的图像数据进行检测,得到第二目标检测结果;其中,所述第一目标检测结果包括三维检测框、第一置信度和第一长尾类别;所述第二目标检测结果包括二维检测框、第二置信度和第二长尾类别;
4、将所述第一目标检测结果中的所述三维检测框投影到所述图像数据的坐标系中,与所述第二目标检测结果中的所述二维检测框进行配对,得到配对结果;
5、若所述配对结果中的所述第一长尾类别的上级类别与所述第二长尾类别的上级类别相匹配,则对所述配对结果中的第一置信度与第二置信度进行融合得到第三置信度,并对所述配对结果进行更新;
6、基于所述三维检测框、所述第三置信度以及所述第二长尾类别,确定更新后的配对结果对应的待检测目标的长尾类别检测结果。
7、在其中一个实施例中,所述利用第一目标检测模型对当前场景的点云数据进行检测,得到第一目标检测结果包括:
8、基于设定的点云采集设备的坐标系区间,对当前场景的初始点云数据进行过滤,得到所述当前场景的点云数据;
9、对所述当前场景的点云数据进行体素化,生成所述当前场景的点云数据对应的多个体素特征;
10、将所述多个体素特征进行融合,得到所述当前场景的点云数据的特征张量;
11、将所述特征张量输入所述第一目标检测模型,得到所述第一目标检测结果。
12、在其中一个实施例中,所述利用第二目标检测模型对当前场景的图像数据进行检测,得到第二目标检测结果包括:
13、获取点云采集设备所采集点云的至少一个三维标注框,在对应场景的图像数据的坐标系上进行投影,得到所述对应场景的图像数据上的二维标注框,所述三维标注框为基于点云数据的人为标注框;
14、将所述对应场景的图像数据和所述二维标注框输入所述第二目标检测模型进行训练,得到训练完备的所述第二目标检测模型;
15、将所述当前场景的图像数据输入训练完备的所述第二目标检测模型,得到所述第二目标检测结果。
16、在其中一个实施例中,所述将所述第一目标检测结果中的所述三维检测框投影到所述图像数据的坐标系中,与所述第二目标检测结果中的所述二维检测框进行配对,得到配对结果包括:
17、基于点云采集设备和图像采集设备的外部参数以及所述图像采集设备的内部参数,将所述第一目标检测结果中的所述三维检测框投影到所述图像数据的坐标系中,得到在所述图像数据上的二维投影框;
18、基于设定的重合率阈值,将所述二维投影框与所述第二目标检测结果中的所述二维检测框进行配对计算,得到所述配对结果。
19、在其中一个实施例中,所述对所述配对结果中的第一置信度与第二置信度进行融合得到第三置信度包括:
20、基于设定的不同长尾类别的置信度参数的初始标定值,利用以下公式,得到所述配对结果的第三置信度:
21、fusionave[i]=ave(calibration1[c]×score2[i],score3[i]),
22、其中,fusionave[i]表示所述第三置信度,calibration1[c]表示长尾类别的置信度参数,score2[i]表示所述第二置信度,score3[i]表示第一置信度,ave()为平均值函数;
23、基于所述第三置信度,对所述配对结果对应的长尾类别的置信度参数进行迭代标定,得到标定后的置信度参数;
24、若针对同一待检测目标,存在多个所述第一长尾类别的上级类别与所述第二长尾类别的上级类别相匹配的配对结果,则保留最新的配对结果对所述长尾类别的置信度参数进行迭代标定,得到所述标定后的置信度参数;
25、利用所述标定后的置信度参数计算得到所述第三置信度,若针对同一待检测目标,存在多个所述第一长尾类别的上级类别与所述第二长尾类别的上级类别相匹配的配对结果,则保留所述第三置信度最高的配对结果。
26、在其中一个实施例中,所述对所述配对结果中的第一置信度与第二置信度进行融合得到第三置信度还包括:
27、基于设定的不同长尾类别的置信度参数的初始标定值,利用以下公式,得到所述配对结果的第三置信度:
28、fusionnum[i]=max(calibration2[c]×score2[i],score3[i]),
29、其中,fusionnum[i]表示所述第三置信度,calibration2[c]表示长尾类别的置信度参数,score2[i]表示所述第二置信度,score3[i]表示所述第一置信度,max()为最大功能值函数;
30、基于所述第三置信度,对所述配对结果对应的长尾类别的置信度参数进行迭代标定,得到标定后的置信度参数;
31、若针对同一待检测目标,存在多个所述第一长尾类别的上级类别与所述第二长尾类别的上级类别相匹配的配对结果,则保留最新的配对结果对所述长尾类别的置信度参数进行迭代标定,得到所述标定后的置信度参数;
32、利用所述标定后的置信度参数计算得到所述第三置信度,若针对同一待检测目标,存在多个所述第一长尾类别的上级类别与所述第二长尾类别的上级类别相匹配的配对结果,则保留所述第三置信度最高的配对结果。
33、在其中一个实施例中,所述对所述配对结果中的第一置信度与第二置信度进行融合得到第三置信度还包括:
34、基于设定的不同长尾类别的置信度参数的初始标定值,利用以下公式(1),得到所述配对结果的第三置信度:
35、fusionbayes[i]=bayes(calibration3[c]×score2[i],score3[i]) (1),
36、其中,fusionbayes[i]表示所述第三置信度,calibration3[c]表示长尾类别的置信度参数,score2[i]表示所述第二置信度,score3[i]表示所述第一置信度,bayes()为贝叶斯函数,其中贝叶斯函数的计算方法如以下公式(2):
37、,
38、其中,x1表示calibration3[c]×score2[i]的值,x2表示score3[i]的值,{p[c],0≤c<c}表示不同长尾类别出现的概率,c为不同长尾类别的类别索引,c为长尾类别总数;
39、基于所述第三置信度,对所述配对结果对应的长尾类别的置信度参数进行迭代标定,得到标定后的置信度参数;
40、若针对同一待检测目标,存在多个所述第一长尾类别的上级类别与所述第二长尾类别的上级类别相匹配的配对结果,则保留最新的配对结果对所述长尾类别的置信度参数进行迭代标定,得到所述标定后的置信度参数;
41、利用所述标定后的置信度参数计算得到所述第三置信度,若针对同一待检测目标,存在多个所述第一长尾类别的上级类别与所述第二长尾类别的上级类别相匹配的配对结果,则保留所述第三置信度最高的配对结果。
42、在其中一个实施例中,基于所述三维检测框、所述第三置信度以及所述第二长尾类别,确定更新后的配对结果对应的待检测目标的长尾类别检测结果还包括:
43、将所述第一目标检测结果中未进行配对的三维检测框所对应的第一置信度乘以保留系数,并舍弃所述第二目标检测结果中未进行匹配的二维检测框;
44、基于乘以保留系数的所述未进行配对的三维检测框以及所述更新后的配对结果,输出所述长尾类别检测结果。
45、第二方面,本技术还提供了一种多模态后融合的长尾类别检测系统,所述系统包括:
46、点云目标检测模块,用于利用第一目标检测模型对当前场景的点云数据进行检测,得到第一目标检测结果,其中,所述第一目标检测结果包括三维检测框、第一置信度和第一长尾类别;
47、图像目标检测模块,用于利用第二目标检测模型对当前场景的图像数据进行检测,得到第二目标检测结果;其中,所述第二目标检测结果包括二维检测框、第二置信度和第二长尾类别;
48、空间融合配对模块,用于将所述第一目标检测结果中的所述三维检测框投影到所述图像数据的坐标系中,与所述第二目标检测结果中的所述二维检测框进行配对,得到配对结果;
49、置信度融合模块,用于若所述配对结果中的所述第一长尾类别的上级类别与所述第二长尾类别的上级类别相匹配,则对所述配对结果中的第一置信度与第二置信度进行融合得到第三置信度,并对所述配对结果进行更新;
50、长尾类别确定模块,用于基于所述三维检测框、所述第三置信度以及所述第二长尾类别,确定更新后的配对结果对应的待检测目标的长尾类别检测结果。
51、在其中一个实施例中,所述系统还包括后处理模块,用于将所述第一目标检测结果中未进行配对的三维检测框所对应的第一置信度乘以保留系数,并舍弃所述第二目标检测结果中未进行匹配的二维检测框。
52、上述多模态后融合的长尾类别检测方法和系统,通过利用第一目标检测模型对当前场景的点云数据进行检测,得到第一目标检测结果;及利用第二目标检测模型对当前场景的图像数据进行检测,得到第二目标检测结果;其中,所述第一目标检测结果包括三维检测框、第一置信度和第一长尾类别;所述第二目标检测结果包括二维检测框、第二置信度和第二长尾类别;将所述第一目标检测结果中的所述三维检测框投影到所述图像数据的坐标系中,与所述第二目标检测结果中的所述二维检测框进行配对,得到配对结果;若所述配对结果中的所述第一长尾类别的上级类别与所述第二长尾类别的上级类别相匹配,则对所述配对结果中的第一置信度与第二置信度进行融合得到第三置信度,并对所述配对结果进行更新;基于所述三维检测框、所述第三置信度以及所述第二长尾类别,确定更新后的配对结果对应的待检测目标的长尾类别检测结果,实现多模态的长尾类别检测,解决了现有技术中长尾类别模型训练难度大、长尾检测精度低的问题,提高了融合输出的长尾类别检测结果的精度。
- 还没有人留言评论。精彩留言会获得点赞!