一种基于可提示的分割模型的视频目标跟踪方法
本发明涉及视频目标跟踪,具体是涉及一种基于可提示的分割模型的视频目标跟踪方法。
背景技术:
1、视频目标跟踪是计算机视觉领域的热点问题之一,因为它在许多行业和领域得到了广泛的研究和应用,如智能视频监控、自动驾驶等。视频目标跟踪任务旨在通过视频第一帧图像及其指定目标初始边界框在视频中跟踪该目标。视频目标跟踪任务主要的技术难点在于目标的连续变化和任意性、其他物体对所跟踪目标的遮挡、跟踪目标的快速移动等方面,这造成跟踪目标在每一帧的外观变化较大且容易受到周围环境外观的影响。
2、现有的一种视频目标跟踪范式如图1a所示,首先采用孪生网络作为图像编码器,对搜索帧和模板帧进行特征提取,然后将提取到的特征进行搜索帧和模板帧的特征交互,最后将交互得到的特征送入边界框预测头得到预测结果。这种范式有两大问题:
3、(1)模板帧和搜索帧之间的交互是图像级的而并不是对象级的,这不可避免地引入模板帧中的部分背景噪声,使得模型误以为这部分背景噪声也是要跟踪的目标。对于视频跟踪任务而言,因为后续每一帧的跟踪都会和该模板图像进行比较,所以模板图像所包含的信息是至关重要的。因此该范式下,模板图像中的细节背景信息会被误以为是所跟踪目标必不可少的一部分,从而在跟踪的时候很容易出现错误跟踪的情况。
4、(2)边界框预测头不具备自优化的能力。这种跟踪范式都是通过预测头直接得到边界框,通过神经网络优化的方式调整预测头的参数,这种方式并不能使得预测头了解其本身的输入输出关系,从而无法了解其输出的边界框质量如何以及如何调整本身参数。
5、还有一种视频目标跟踪范式如图1b所示,利用视觉transformer(vit),首先将搜索帧和模板帧映射为一个个的小图像块,将图像块编码后,将搜索帧图像块和模板帧图像块拼接在一起然后送入一系列视觉transformer编码块进行特征提取与特征交互。这种范式的缺点同样包括模板帧和搜索帧之间的交互是图像级的而并不是对象级的、边界框预测头不具备自优化的能力。
技术实现思路
1、针对上述问题,本发明为了解决以上视频目标跟踪范式面临的问题,提供一种基于可提示的分割模型的视频目标跟踪方法。该方法能够在复杂环境中的实际场景中保证较高的跟踪准确性和快速性,智能、快速、准确地的进行选定目标的跟踪。
2、为了实现上述目的,本发明提供一种基于可提示的分割模型的视频目标跟踪方法,包括以下步骤:
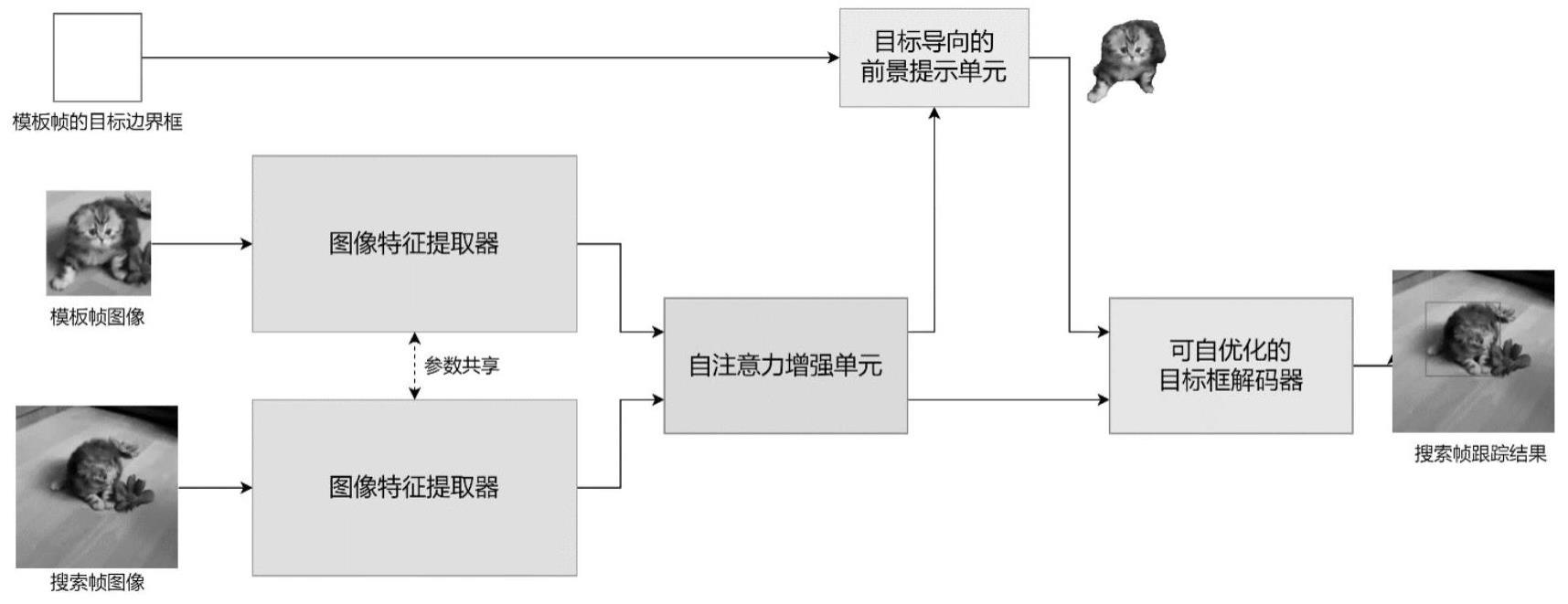
3、s1、构建视频单目标跟踪编码器-特征增强-解码器范式;
4、s2、构建一种基于可提示的分割模型的编码器;
5、s3、构建模板和搜索区域特征的自注意力增强单元;
6、s4、构建目标导向的前景提示单元;
7、s5、构建一种可自优化的目标框解码器;
8、s6、在所述视频单目标跟踪编码器-特征增强-解码器范式下,构建包含基于可提示的分割模型的编码器、模板和搜索区域特征的自注意力增强单元、目标导向的前景提示单元、可自优化的目标框解码器的单目标跟踪模型,并在服务器上对所述单目标跟踪模型进行训练,通过降低网络损失函数的总体损失值,优化网络参数,直至网络收敛;
9、s7、利用训练好的网络模型对待跟踪的视频序列中指定的单个目标进行跟踪。
10、优选的,所述步骤s1具体包括以下步骤:
11、s11、基于可提示的分割模型的图像编码器,结合自然语言处理领域中常用的工具-适配器建立一个图像特征提取器,将输入的搜索帧和模板帧分别用该图像特征提取器提取特征得到搜索帧特征xs和模板帧特征xt;
12、s12、将所述搜索帧特征xs和模板帧特征xt使用模板和搜索区域特征的自注意力增强单元进行高效融合,得到增强的搜索帧特征fs和增强的模板帧特征ft;
13、s13、在目标导向的前景提示单元中,利用增强的模板帧特征ft,通过可提示的分割模型进行分割,得到视频目标跟踪任务的待跟踪目标物的分割掩膜,利用所述分割掩膜,得到目标物体的特征fobj;
14、s14、将所述目标物体的特征fobj和增强的搜索帧特征fs输入到可自优化的目标框解码器中,得到跟踪结果,跟踪结果包括所跟踪目标的目标分类得分图p、局部偏移图o、归一化尺寸图s。
15、优选的,所述步骤s2具体包括以下步骤:
16、s21、对基于可提示的分割模型的图像编码器中视觉transformer的绝对位置编码和相对位置编码重新训练以匹配256×256和384×384的图像分辨率;
17、s22、使用适配器搭配可提示的分割模型中的图像编码器作为图像特征提取器,将输入的搜索帧和模板帧分别用该图像特征提取器提取特征得到搜索帧特征和模板帧特征即:
18、
19、
20、其中,patchembed(·)的作用是将图像块映射到隐藏空间,为绝对位置编码,ln(·)为层归一化,msa(·)为多头注意力机制,adapter(·)为适配器,num_block表示图像特征提取器中单元块的个数。
21、优选的,所述适配器由一个全连接下采样层、一个激活层、一个全连接上采样层以及残差连接组成。
22、优选的,所述模板和搜索区域特征的自注意力增强单元由2个自注意力单元组成,每个自注意力单元由多头注意力层(msa)、层归一化(ln)、多层感知机(mlp)、残差连接组成。
23、优选的,所述步骤s3具体包括以下步骤:
24、s31、将步骤s22中得到的所述搜索帧特征和模板帧特征拼接为并加入绝对位置编码然后送入2个自注意力单元进行处理;
25、s32、将拼接特征送入模板和搜索区域特征的自注意力增强单元,将得到的结果进行切分,得到增强的搜索帧特征和增强的模板帧特征
26、优选的,所述步骤s4具体实施过程如下:将模板帧的目标框作为提示,利用可提示的分割模型中的提示编码器提取特征根据目标框提示的特征和增强的模板帧特征利用可提示的分割模型中的掩膜解码器获取目标物体的分割掩膜mt,然后利用掩膜的筛选能力,对增强的模板帧特征进行作用,并通过平均池化得到目标物体特征向量
27、优选的,所述步骤s5具体包括以下步骤:
28、s51、对所述目标物体特征向量和增强的搜索帧特征求余弦相似度,得到目标物体与搜索图像的相似度图
29、s=fobj·fs
30、相似度图s中每个元素s(c,i,j)(0<i<h,0<j<w)表示目标物体特征向量与搜索帧每个图像块的相似程度,s(c,i,j)数值越大代表相似性越高,即该位置可认为是视频目标跟踪任务中的前景点;反之,s(c,i,j)数值越小代表相似性越低,即该位置可认为是视频目标跟踪任务中的背景点,选取s(c,i,j)最大值对应在图像上的点和最小值对应在图像上的点作为一对正负位置点对,记作pmaxmin=(pmax,pmin);
31、s52、将正负位置点对pmaxmin作为提示,对增强的搜索帧特征进行解码,输出目标导向的搜索帧特征即为:
32、
33、s53、利用所述目标导向的搜索帧特征通过全卷积网络得到目标的目标分类得分图局部偏移图归一化尺寸图其中分类图中得分最高的对应目标物体的中心点。根据目标分类得分图、局部偏移图、归一化尺寸图可以得到初步的目标物体边界框bbox0;
34、s54、利用所述初步的目标物体边界框bbox0作为提示,将所述目标导向的搜索帧特征输入到可提示的分割模型的掩膜解码器,输出最终的搜索帧特征
35、s55、利用所述最终的搜索帧特征通过全卷积网络得到目标的目标分类得分图局部偏移图归一化尺寸图根据目标分类得分图、局部偏移图、归一化尺寸图得到最终的目标物体边界框bbox,达到自优化的效果。
36、优先的,所述步骤s6具体包括以下步骤:
37、s61、利用服务器进行图像裁剪和数据增强:裁剪的方式为:以目标所在区域为中心裁剪出一个矩形图像,该矩形图像的长宽分别为目标矩形框长宽的2倍。矩形框超出原视频边界的部分用像素平均值进行填充,最后将该矩形图像缩放到256×256或384×384,以此构成模板帧图像;以目标所在区域为中心裁剪出一个矩形图像,该矩形图像的长宽分别为目标矩形框长宽的4倍,矩形框超出原视频边界的部分用像素平均值进行填充,最后将该矩形图像缩放到256×256或384×384,以此构成搜索帧图像,对模板帧和搜索帧进行数据增强,包括随机反转、随机灰度化、中心点位置抖动、边界框尺寸抖动等操作;
38、s62、利用服务器执行步骤s2,即基于可提示的分割模型的编码器,对搜索帧图像和模板帧图像都进行特征提取;然后执行步骤s3,通过模板和搜索区域特征的自注意力增强单元对模板帧图像特征和搜索帧图像特征进行特征交互与增强;之后执行步骤s4获得目标导向的前景提示;最后执行步骤s5,通过一种可自优化的目标框解码器获得所跟踪目标的目标分类得分图、局部偏移图、归一化尺寸图,进而可以获得目标物体边界框;
39、s63、利用服务器训练网络模型,采用端到端的方式进行训练,损失函数的总体表达式为:
40、
41、其中,lcls表示分类的焦点损失;liou和l1都用于监督边界框回归,分别表示广义交并比损失和l1损失,λiou和分别表示广义交并比损失和l1损失的权重,分别设值为:λiou=2,
42、s64、在服务器上对所述单目标跟踪模型进行训练,通过降低网络损失函数的总体损失值,优化网络参数,直至网络收敛,获取局部最优的网络参数。
43、优选的,所述步骤s7具体包括以下步骤:
44、s71、对于给定的视频,初始化视频的第一帧作为视频目标跟踪的模板帧,且给定模板帧的边界框。根据该边界框,对模板帧以预设的尺寸变化划分出一块区域作为模板帧图像,视频目标跟踪网络从第二帧开始进行跟踪;
45、s72、对于第二帧及以后的每一帧,以上一帧目标框的中心点为基准,以预设的尺寸和距离划分出一块区域作为搜索帧图像,将模板帧图像和搜索帧图像输入到网络模型,输出当前帧的跟踪结果。
46、与现有技术相比,本发明的有益效果是:
47、本发明提供的一种基于可提示的分割模型的视频目标跟踪方法,通过利用可提示的分割模型获得跟踪目标的对象级特征,将搜索帧的交互范围从图像级的模板帧扩充到对象级的目标物,跟踪目标特征为搜索帧在目标框解码阶段提供了重要的提示信息,令搜索帧更加关注于所要跟踪的目标物体而免受模板中背景信息的影响,提高了跟踪的鲁棒性。此外,目标框解码器具备自优化的能力,能够及时反馈输出的边界框并优化之,提高了跟踪的准确性。本发明在众多困难的实际场景中都可以准确稳定地跟踪目标,和其他方法相比取得了更好的目标跟踪效果。
- 还没有人留言评论。精彩留言会获得点赞!