对象需求识别模型的训练方法、装置和计算机设备与流程
本技术涉及人工智能,特别是涉及一种对象需求识别模型的训练方法、装置、计算机设备、存储介质和计算机程序产品。
背景技术:
1、金融机构每日都需要处理大量的客户咨询,为提高客户咨询处理效率,目前的金融机构都设有线上咨询渠道,并为线上咨询渠道配置了智能客服,以高效处理每日海量的客户咨询信息。其中,智能客服是基于能够准确识别客户需求的模型配置的,可以对客户发送的咨询信息文本进行智能识别,并基于识别结果,确定客户的需求类型,进而推荐与客户需求对应的解决方案。
2、传统技术中,为训练得到能够准确识别客户需求的模型,金融机构的研发人员需要准备大量可供学习的样本。因此,研发人员通常需要耗费大量时间,以对不同客户的大量未知需求类型的咨询信息文本逐一进行需求识别,并为大量咨询信息文本逐一配置表征需求类型的标签,从而得到大量携带标签、可供学习的样本,进而基于携带标签的样本训练得到所需的模型。
3、然而,传统技术中,由于需要耗费大量时间去制作携带标签的样本,导致模型训练效率不高。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够提高模型训练效率的对象需求识别模型的训练方法、装置、计算机设备、计算机可读存储介质和计算机程序产品。
2、第一方面,本技术提供了一种对象需求识别模型的训练方法,包括:
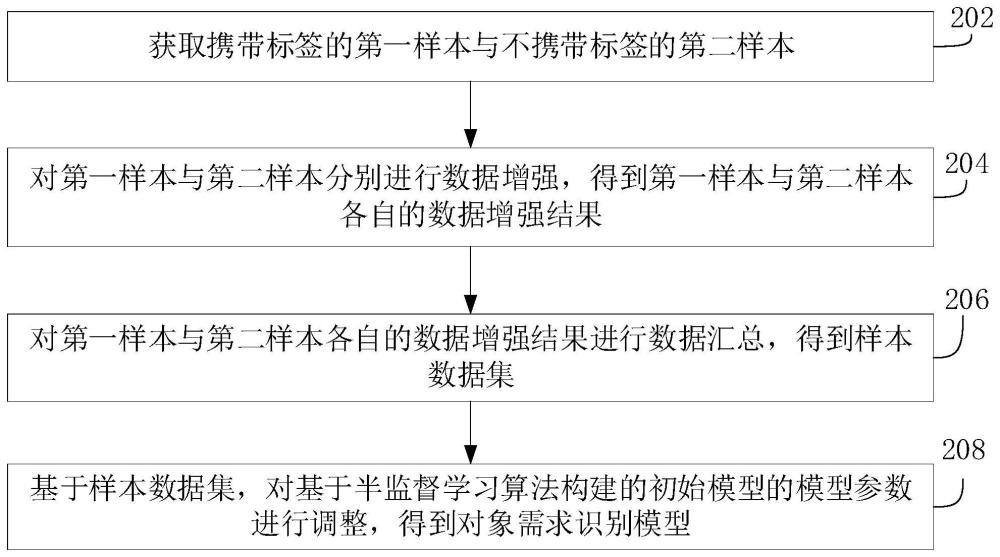
3、获取携带标签的第一样本与不携带标签的第二样本;第一样本与第二样本中均包括多个历史对象的咨询信息文本,第一样本的数据量小于第二样本的数据量;标签中携带咨询信息文本对应的需求类型;
4、对第一样本与第二样本分别进行数据增强,得到第一样本与第二样本各自的数据增强结果;
5、对第一样本与第二样本各自的数据增强结果进行数据汇总,得到样本数据集;
6、基于样本数据集,对基于半监督学习算法构建的初始模型的模型参数进行调整,得到对象需求识别模型。
7、在其中一个实施例中,获取携带标签的第一样本与不携带标签的第二样本,包括:
8、获取多个历史对象各自的咨询信息文本;
9、从咨询信息文本中,选取数量占比低于设定比例的咨询信息文本进行标签配置操作,得到携带标签的第一样本;
10、将咨询信息文本中未进行标签配置操作的咨询信息文本,作为不携带标签的第二样本。
11、在其中一个实施例中,对第一样本与第二样本分别进行数据增强,得到第一样本与第二样本各自的数据增强结果,包括:
12、将第一样本、第二样本中的各咨询信息文本分别作为待增强文本;
13、针对每一待增强文本,从待增强文本中选择多个待替换词;
14、针对每一待替换词,获取与待替换词匹配的可替换词,并采用获取的可替换词替换待替换词,得到待增强文本对应的增强文本;
15、对第一样本对应的待增强文本、增强文本进行数据汇总,得到第一样本的数据增强结果;
16、对第二样本对应的待增强文本、增强文本进行数据汇总,得到第二样本的数据增强结果。
17、在其中一个实施例中,初始模型的主干网络为长短期记忆递归神经网络。
18、在其中一个实施例中,基于样本数据集,对基于半监督学习算法构建的初始模型的模型参数进行调整,得到对象需求识别模型,包括:
19、将样本数据集输入基于半监督学习算法构建的初始模型,得到初始模型的模型损失函数值;
20、基于模型损失函数值,对初始模型的模型参数进行调整,得到更新模型;
21、将样本数据集输入更新模型,得到更新模型的更新模型损失函数值;
22、基于更新模型损失函数值,对更新模型的模型参数进行调整,直到得到的更新模型损失函数值满足模型停止训练条件,得到对象需求识别模型。
23、在其中一个实施例中,还包括:
24、获取目标对象的目标咨询信息文本;
25、将目标咨询信息文本输入对象需求识别模型,得到目标对象的目标需求类型。
26、第二方面,本技术还提供了一种对象需求识别模型的训练装置,包括:
27、样本获取模块,用于获取携带标签的第一样本与不携带标签的第二样本;第一样本与第二样本中均包括多个历史对象的咨询信息文本,第一样本的数据量小于第二样本的数据量;标签中携带咨询信息文本对应的需求类型;
28、数据增强模块,用于对第一样本与第二样本分别进行数据增强,得到第一样本与第二样本各自的数据增强结果;
29、数据汇总模块,用于对第一样本与第二样本各自的数据增强结果进行数据汇总,得到样本数据集;
30、模型参数调整模块,用于基于样本数据集,对基于半监督学习算法构建的初始模型的模型参数进行调整,得到对象需求识别模型。
31、第三方面,本技术还提供了一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现以下步骤:
32、获取携带标签的第一样本与不携带标签的第二样本;第一样本与第二样本中均包括多个历史对象的咨询信息文本,第一样本的数据量小于第二样本的数据量;标签中携带咨询信息文本对应的需求类型;
33、对第一样本与第二样本分别进行数据增强,得到第一样本与第二样本各自的数据增强结果;
34、对第一样本与第二样本各自的数据增强结果进行数据汇总,得到样本数据集;
35、基于样本数据集,对基于半监督学习算法构建的初始模型的模型参数进行调整,得到对象需求识别模型。
36、第四方面,本技术还提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以下步骤:
37、获取携带标签的第一样本与不携带标签的第二样本;第一样本与第二样本中均包括多个历史对象的咨询信息文本,第一样本的数据量小于第二样本的数据量;标签中携带咨询信息文本对应的需求类型;
38、对第一样本与第二样本分别进行数据增强,得到第一样本与第二样本各自的数据增强结果;
39、对第一样本与第二样本各自的数据增强结果进行数据汇总,得到样本数据集;
40、基于样本数据集,对基于半监督学习算法构建的初始模型的模型参数进行调整,得到对象需求识别模型。
41、第五方面,本技术还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现以下步骤:
42、获取携带标签的第一样本与不携带标签的第二样本;第一样本与第二样本中均包括多个历史对象的咨询信息文本,第一样本的数据量小于第二样本的数据量;标签中携带咨询信息文本对应的需求类型;
43、对第一样本与第二样本分别进行数据增强,得到第一样本与第二样本各自的数据增强结果;
44、对第一样本与第二样本各自的数据增强结果进行数据汇总,得到样本数据集;
45、基于样本数据集,对基于半监督学习算法构建的初始模型的模型参数进行调整,得到对象需求识别模型。
46、上述对象需求识别模型的训练方法、装置、计算机设备、存储介质和计算机程序产品,先获取携带标签的第一样本与不携带标签的第二样本,其中第一样本与第二样本中均包括多个历史对象的咨询信息文本,第一样本的数据量小于第二样本的数据量,即模型训练是基于少量携带标签的第一样本、大量不携带标签的第二样本实现的,因此,无需耗费大量时间制作大量携带标签的第一样本,有利于提高模型训练效率,进一步的,由于模型训练过程,通常对样本数据集具有数据量要求,因此,可以通过对第一样本与第二样本分别进行数据增强,得到第一样本与第二样本各自的数据增强结果,再对第一样本与第二样本各自的数据增强结果进行数据汇总,得到数据量足够的样本数据集,而无需去耗费大量时间制作数据量足够的第一样本、第二样本,最后,基于样本数据集,对基于半监督学习算法构建的初始模型的模型参数进行调整,得到对象需求识别模型。整个过程中,一方面,基于少量携带标签的第一样本,大量不携带标签的第二样本训练模型,可以减少制作携带标签的第一样本的时间,另一方面,可以通过数据增强,确保样本数据集的数据量足够,不用耗费更多时间制作数据量足够的第一样本或第二样本,从而提高模型训练效率。
- 还没有人留言评论。精彩留言会获得点赞!