一种服务灯塔认知的3D目标检测任务模型高效训练方法
本申请涉及自动驾驶,尤其是涉及一种服务灯塔认知的3d目标检测任务模型高效训练方法。
背景技术:
1、目前,通常利用针对不同任务且满足一定顺序数据对路端视觉3d目标检测任务模型进行训练,进而根据任务的执行结果对模型进行增量式更新。然而人工智能体在学习新任务时,容易产生灾难性遗忘,即遗忘从旧任务中学习到的知识。例如,对于按照顺序经历路端汽车数据、货车数据训练的模型,后续无法准确检测出路端数据中汽车。
技术实现思路
1、有鉴于此,本申请提供了一种服务灯塔认知的3d目标检测任务模型高效训练方法,以解决路端视觉3d目标检测任务模型训练中存在的灾难性遗忘的技术问题。
2、第一方面,本申请实施例提供一种服务灯塔认知的3d目标检测任务模型高效训练方法,所述方法包括:
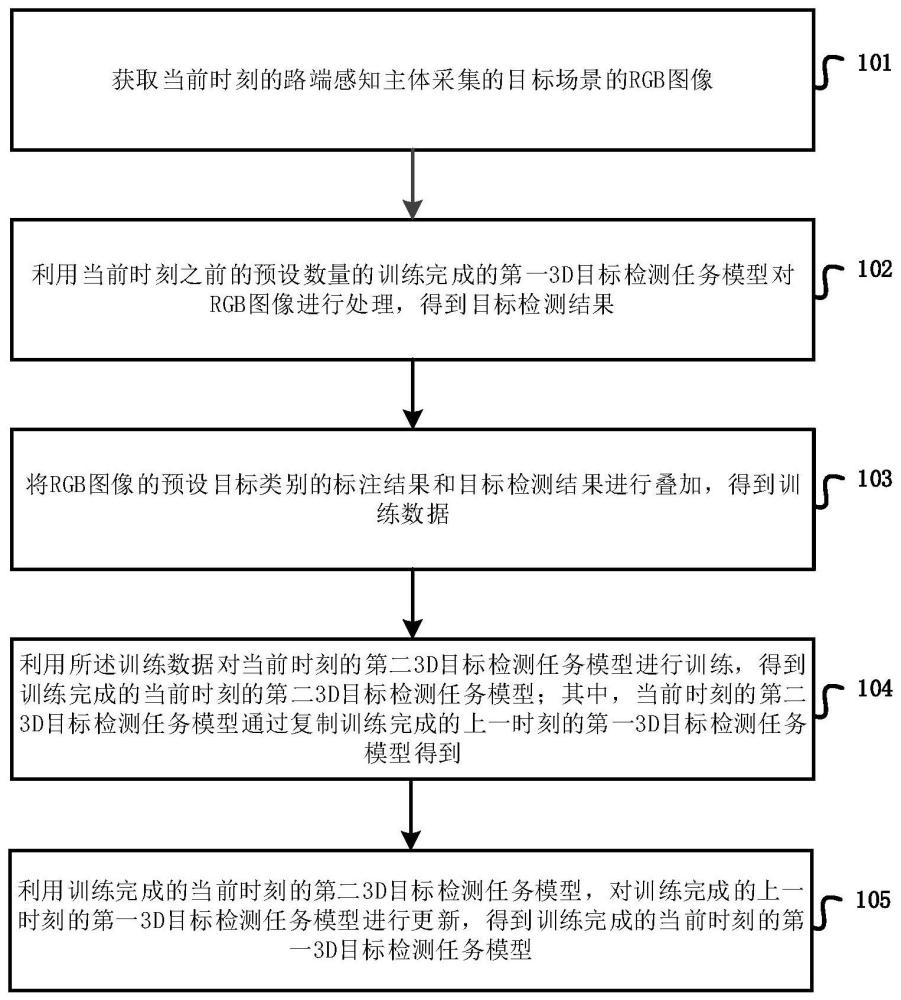
3、获取当前时刻的路端感知主体采集的目标场景的rgb图像;
4、利用当前时刻之前的预设数量的训练完成的第一3d目标检测任务模型对rgb图像进行处理,得到目标检测结果;
5、将rgb图像的预设目标类别的标注结果和目标检测结果进行叠加,得到训练数据;
6、利用所述训练数据对当前时刻的第二3d目标检测任务模型进行训练,得到训练完成的当前时刻的第二3d目标检测任务模型;其中,当前时刻的第二3d目标检测任务模型通过复制训练完成的上一时刻的第一3d目标检测任务模型得到;
7、利用训练完成的当前时刻的第二3d目标检测任务模型,对训练完成的上一时刻的第一3d目标检测任务模型进行更新,得到训练完成的当前时刻的第一3d目标检测任务模型。
8、进一步地,所述目标检测结果包括多个目标的类别和检测框的位置及大小。
9、进一步地,预设目标类别包括:汽车、卡车、货车、公交车、摩托车、自行车和行人的至少一种;rgb图像的预设目标类别的标注结果包括:预设目标类别的检测框的位置及大小。
10、进一步地,利用当前时刻之前的预设数量的训练完成的第一3d目标检测任务模型对rgb图像进行处理,得到目标检测结果;包括:
11、获取多个训练完成的不同时刻的第一3d目标检测任务模型;
12、分别利用训练完成的每个时刻的第一3d目标检测任务模型对rgb图像进行处理进行,得到m个检测框;
13、对m个检测框进行聚类,得到c个聚类,其中,每个聚类代表多个第一3d目标检测任务模型从rgb图像检测出的同一目标;
14、计算每个聚类的多个检测框的位置精度,将位置精度最大值对应的检测框作为所述聚类的检测框。
15、进一步地,获取多个训练完成的不同时刻的第一3d目标检测任务模型;包括:
16、若当前时刻的序号小于n,则获取当前时刻之前所有的第一3d目标检测任务模型;否则;从当前时刻之前所有的第一3d目标检测任务模型随机选取n个第一3d目标检测任务模型。
17、进一步地,对m个检测框进行聚类,得到c个聚类;包括:
18、步骤s1:将m个检测框放入集合b;
19、步骤s2:从集合b中选取置信度最高的检测框a,将检测框a从集合b中删除,基于检测框a构建一个聚类c;
20、步骤s3:对集合b中的任意一个检测框b,判断iou3d(a,b)是否大于预设的阈值,若为是,则将检测框b放入聚类c,从集合b中删除检测框b;其中,iou3d(a,b)为检测框a和检测框b的三维交并比;
21、步骤s4:判断集合b是否为空,若为否,转入步骤s2。
22、进一步地,计算每个聚类的多个检测框的位置精度;包括:
23、计算聚类c的第i个检测框bi的位置精度diou(bi,bm):
24、
25、式中,bm表示聚类c的置信度最高的检测框,1≤i≤k,k表示聚类c的检测框数量,iou3d(bi,bm)表示检测框bi和检测框bm的三维交并比,ρ表示检测框bi的中心点和检测框bm的中心点之间的欧式距离,d表示同时包含检测框bi和检测框bm的最小包络矩形框的对角线距离。
26、进一步地,利用所述训练数据对当前时刻的第二3d目标检测任务模型进行训练,得到完成训练的当前时刻的第二3d目标检测任务模型;包括:
27、利用当前时刻的第二3d目标检测任务模型对rgb图像进行处理,得到多个目标的预测结果;
28、基于训练数据中的预设目标类别的标注结果和对应目标的预测结果,计算得到真值标签监督损失
29、基于训练数据中的目标检测结果和对应目标的预测结果,计算得到伪标签监督损失
30、计算总损失
31、
32、其中,λ为平衡真值标签监督损失和伪标签监督损失所占比重的超参数;
33、利用总损失对当前时刻的第二3d目标检测任务模型的参数进行更新。
34、第三方面,本申请实施例提供一种服务灯塔认知的3d目标检测任务模型高效训练装置,所述装置包括:
35、获取单元,用于获取当前时刻的路端感知主体采集的目标场景的rgb图像;
36、目标检测单元,用于利用当前时刻之前的预设数量的训练完成的第一3d目标检测任务模型对rgb图像进行处理,得到目标检测结果;
37、叠加单元,用于将rgb图像的预设目标类别的标注结果和目标检测结果进行叠加,得到训练数据;
38、训练单元,用于利用所述训练数据对当前时刻的第二3d目标检测任务模型进行训练,得到训练完成的当前时刻的第二3d目标检测任务模型;其中,当前时刻的第二3d目标检测任务模型通过复制训练完成的上一时刻的第一3d目标检测任务模型得到;
39、更新单元,用于利用训练完成的当前时刻的第二3d目标检测任务模型,对训练完成的上一时刻的第一3d目标检测任务模型进行更新,得到训练完成的当前时刻的第一3d目标检测任务模型。
40、第三方面,本申请实施例提供了一种电子设备,包括:存储器、处理器和存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本申请实施例的方法。
41、第四方面,本申请实施例一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器运行时实现本申请实施例的方法。
42、本申请的方法通过连续学习解决了模型训练出现的灾难性遗忘问题。
技术特征:
1.一种服务灯塔认知的3d目标检测任务模型高效训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述目标检测结果包括多个目标的类别和检测框的位置及大小。
3.根据权利要求2所述的方法,其特征在于,所述预设目标类别包括:汽车、卡车、货车、公交车、摩托车、自行车和行人的至少一种;rgb图像的预设目标类别的标注结果包括:预设目标类别的检测框的位置及大小。
4.根据权利要求3所述的方法,其特征在于,利用当前时刻之前的预设数量的训练完成的第一3d目标检测任务模型对rgb图像进行处理,得到目标检测结果;包括:
5.根据权利要求4所述的方法,其特征在于,获取多个训练完成的不同时刻的第一3d目标检测任务模型;包括:
6.根据权利要求5所述的方法,其特征在于,对m个检测框进行聚类,得到c个聚类;包括:
7.根据权利要求6所述的方法,其特征在于,计算每个聚类的多个检测框的位置精度;包括:
8.根据权利要求1所述的方法,其特征在于,利用所述训练数据对当前时刻的第二3d目标检测任务模型进行训练,得到完成训练的当前时刻的第二3d目标检测任务模型;包括:
9.一种服务灯塔认知的3d目标检测任务模型高效训练装置,其特征在于,所述装置包括:
10.一种电子设备,其特征在于,包括:存储器、处理器和存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如权利要求1-8任一项所述的方法。
技术总结
本申请提供一种服务灯塔认知的3D目标检测任务模型高效训练方法,涉及自动驾驶技术领域,所述方法包括:利用当前时刻之前的预设数量的训练完成的第一3D目标检测任务模型对RGB图像进行处理,得到目标检测结果;将RGB图像的预设目标类别的标注结果和目标检测结果进行叠加,得到训练数据;利用所述训练数据对当前时刻的第二3D目标检测任务模型进行训练,得到训练完成的当前时刻的第二3D目标检测任务模型;利用训练完成的当前时刻的第二3D目标检测任务模型,对训练完成的上一时刻的第一3D目标检测任务模型进行更新,得到训练完成的当前时刻的第一3D目标检测任务模型。本申请的方法通过连续学习解决了模型训练出现的灾难性遗忘问题。
技术研发人员:李骏,张新钰,杨磊,王力,余佳芯,张伟伟,沈阳
受保护的技术使用者:清华大学
技术研发日:
技术公布日:2024/2/8
- 还没有人留言评论。精彩留言会获得点赞!