乘累加优化方法、系统、设备和介质与流程
本申请涉及处理器领域,且更具体地,涉及第一张量和第二张量的乘累加优化方法、系统、电子设备和非暂时存储介质。
背景技术:
1、在卷积神经网络的推理和训练模型中,通用矩阵乘(general matrixmultiplication,gemm)和卷积算子(conv)都是一个非常常见的算子,使用频率非常高,比如在resnet50这种模型中,卷积算子非常多。所以对卷积算子的优化,对于处理器加速推理与训练模型变得非常重要。
技术实现思路
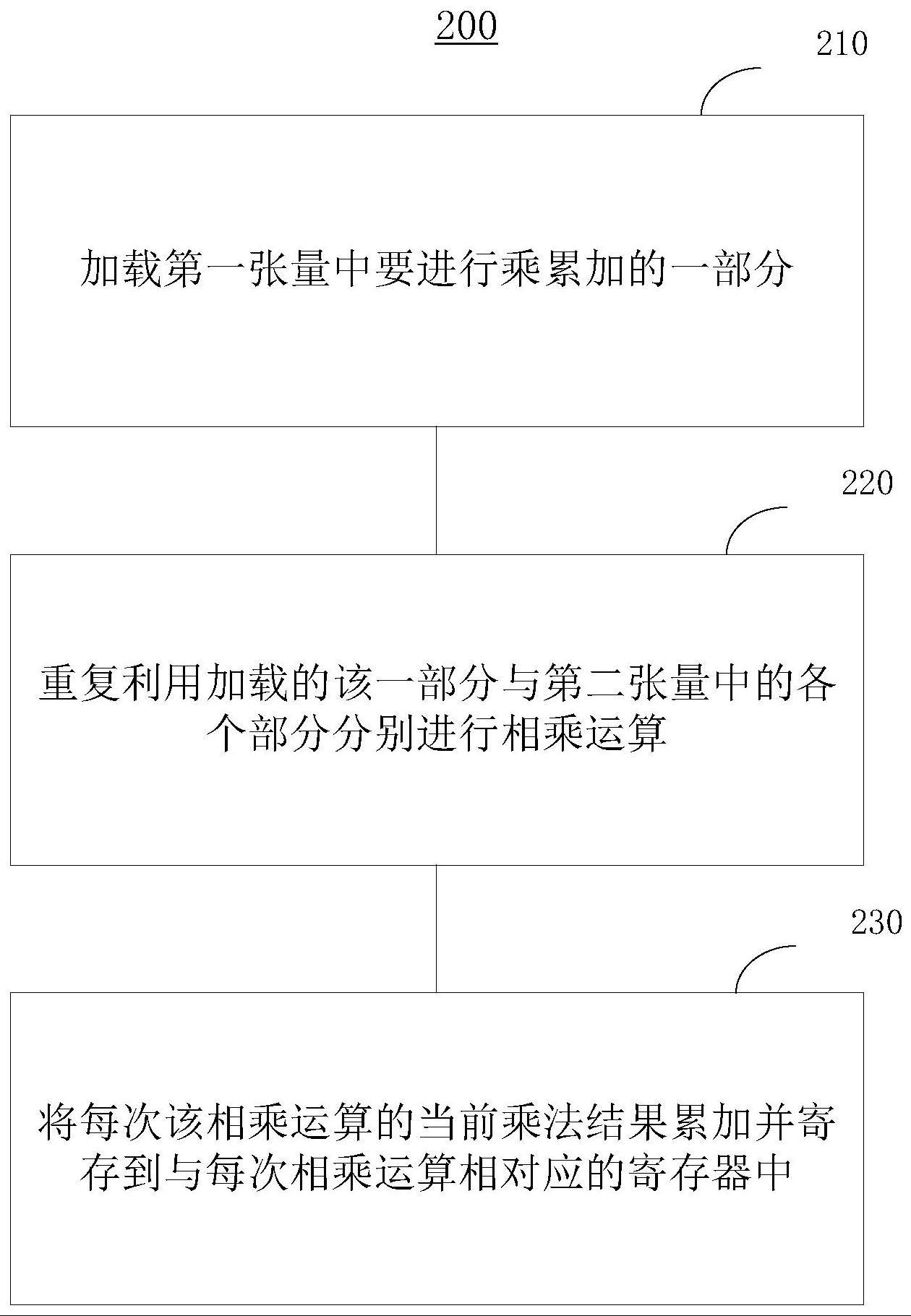
1、根据本申请的一个方面,提供一种第一张量和第二张量的乘累加优化方法,包括:加载第一张量中要进行乘累加的一部分;重复利用加载的所述一部分与第二张量中的各个部分分别进行相乘运算;将每次所述相乘运算的当前乘法结果累加并寄存到与每次所述相乘运算相对应的寄存器中。
2、根据本申请的另一个方面,提供一种第一张量和第二张量的乘累加优化系统,包括:加载装置,被配置为加载第一张量中要进行乘累加的一部分;相乘装置,被配置为重复利用加载的所述一部分与第二张量中的各个部分分别进行相乘运算;寄存装置,被配置为将每次所述相乘运算的当前乘法结果累加并寄存到与每次所述相乘运算相对应的寄存器中。
3、根据本申请的另一个方面,提供一种电子设备,包括:存储器,用于存储指令;处理器,用于读取所述存储器中的指令,并执行根据本申请的实施例的方法。
4、根据本申请的另一个方面,提供一种非暂时存储介质,其上存储有指令,其中,所述指令在被处理器读取时,使得所述处理器执行根据本申请的实施例的方法。
5、如此,可以加载第一张量中要进行乘累加的一部分(例如到第一缓冲器中)一次,就可以复用该第一张量中要进行乘累加的一部分分别与第二张量中的各个部分分别进行多次相乘运算,这极大地节约了加载第一张量(或其各个部分)(例如到第一缓冲器中)的次数。其次,利用与每次该相乘运算相对应的寄存器来分别寄存每次该相乘运算的当前乘法结果,以便下次继续与新的乘法结果进行累加,相当于扩展了多个累加器acc,因此不局限于系统设计的acc数量。
技术特征:
1.一种第一张量和第二张量的乘累加优化方法,包括:
2.根据权利要求1所述的方法,其中,利用循环嵌套方式来实现所述乘累加优化方法。
3.根据权利要求1所述的方法,还包括:
4.根据权利要求3所述的方法,其中所述加载第一张量中要进行乘累加的一部分包括:
5.根据权利要求3所述的方法,其中,
6.根据权利要求4所述的方法,其中,
7.根据权利要求6所述的方法,其中,
8.根据权利要求1-7中任一所述的方法,其中,t=8。
9.根据权利要求3所述的方法,其中,
10.根据权利要求3所述的方法,其中,inner_loop个内循环乘累加操作被展开为inner_loop个具体运算代码,且将所述inner_loop个具体运算代码与其他运算代码共同进行编译优化。
11.一种第一张量和第二张量的乘累加优化系统,包括:
12.根据权利要求11所述的系统,其中,所述乘累加优化系统利用循环嵌套方式来实现所述乘累加优化。
13.根据权利要求11所述的系统,还包括:
14.根据权利要求13所述的系统,还包括:
15.根据权利要求13所述的系统,其中,
16.根据权利要求14所述的系统,其中,
17.根据权利要求16所述的系统,其中,所述运算装置被配置为:
18.根据权利要求11-17中任一所述的系统,其中,t=8。
19.根据权利要求13所述的系统,其中,
20.根据权利要求13所述的系统,其中,所述运算装置被配置为将inner_loop个内循环乘累加操作展开为inner_loop个具体运算代码,且将所述inner_loop个具体运算代码与其他运算代码共同进行编译优化。
21.一种电子设备,包括:
22.一种非暂时存储介质,其上存储有指令,
技术总结
提供第一张量和第二张量的乘累加优化方法、系统、设备和介质。方法包括:加载第一张量中要进行乘累加的一部分;重复利用加载的所述一部分与第二张量中的各个部分分别进行相乘运算;将每次所述相乘运算的当前乘法结果累加并寄存到与每次所述相乘运算相对应的寄存器中。如此,可以加载第一张量中要进行乘累加的一部分一次,就可以复用该第一张量中要进行乘累加的一部分分别与第二张量中的各个部分分别进行多次相乘运算,这极大地节约了加载第一张量的次数。其次,利用与每次该相乘运算相对应的寄存器来分别寄存每次该相乘运算的当前乘法结果,以便下次继续与新的乘法结果进行累加,相当于扩展了多个累加器,不局限于系统设计的累加器数量。
技术研发人员:请求不公布姓名
受保护的技术使用者:上海壁仞科技股份有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!