一种多模态谣言识别方法及装置
本发明属于网络空间安全信息领域,更具体的涉及一种多模态谣言识别方法及装置。
背景技术:
1、社交媒体的迅速发展不仅对知识共享与交流带来了巨大便利,还造成了大量谣言的广泛传播。谣言的传播已经对政治、经济、公共安全、媒体公信力等领域造成了巨大威胁。特别地,当前网络中传播的信息已经从抽象的单一文本模态转变为图文并茂、有声有色的多模态形式,导致传播的虚假信息同样也披上了多模态的外衣。多模态谣言相比于单模态谣言具有更强的感染力,信息传播的更深更远,造成的破坏性更大。因此,在这样的场景下,如何对多模态谣言进行自动地识别已经受到学术界、工业界等机构的广泛关注。
2、在现有研究中,谣言识别可大致划分为两种数据表现形式的识别,即单模态谣言识别和多模态谣言识别。在单模态谣言识别方法中,其主要划分为基于特征工程的方法以及基于自动特征抽取的方法两种类型。针对特征工程的方法识别新闻通常通过人工抽取文本内容的表面特征(标点符号,重复词个数、新闻的总长度等特征)和简单的元数据特征(点赞量、转发量等)来开展的。这类方法能够挖掘较为浅显的有效特征,但这种方法大多以人工特征构建方式为主,其很难应对社交媒体中海量新闻的实时识别。第二类基于自动特征抽取的方法,其主要构建合理有效的神经网络模型来挖掘文本内容中的语法、语义、情感、立场、风格等特征以及学习元数据中的评论、传播结构、用户画像等特征,提取的特征丰富多样,且能够做到自动实时挖掘,目前已经实现了显著的性能提升。综合来看,单模态谣言识别已经获得了长足的发展。
3、当前,网络中传播的谣言不仅包含文本类型的信息,还包含大量多模态类型数据,包括伪造的图片或图文不符的谣言等等,这使得基于多模态谣言识别任务得到了越来越多的关注。当前多模态谣言识别方法根据处理环节的不同主要聚焦在两大方面的研究,即前期与后期的特征融合阶段和中间过程的交互对齐机制。在特征融合阶段,其首先借助不同的编码器分别抽取文本或图像特征,然后通过前融合或后融合的方式整合两类特征进行谣言识别。在交互对齐机制上,其试图构建多模态特征交互关联来实现多模态信息中多种类型的对齐,包括实体级对齐、关系级对齐、语义级对齐等,从而进行多模态谣言识别。
4、然而,虽然这些模型已经促进了多模态谣言识别的发展,但其仍然存在着几个问题:1)在特征融合方面,现有模型通常采用简单的融合策略如拼接、加性或简单的神经网络融合不同模态类型的特征,这样的特征融合较浅,且难以挖掘不同他们之间的内在的依赖关系。2)在交互对齐方面,大多数方法的重点聚焦在不同模态特征之间的相似性语义的挖掘,却忽略了不同模态之间还存在着大量的不一致语义,这些不一致信息中蕴含着大量可信度特征,可能是影响模型性能提升的关键。因此,如何挖掘对不同模态进行更深层次的融合并探索不同模态之间的不一致性作为可信度特征是多模态谣言识别的关键问题。
技术实现思路
1、本发明实施例提供一种多模态谣言识别方法及装置,能够有效挖掘多模态特征之间的关系,更好地且深层次地对谣言的多模态信息进行融合。
2、本发明实施例提供一种多模态谣言识别方法,包括:
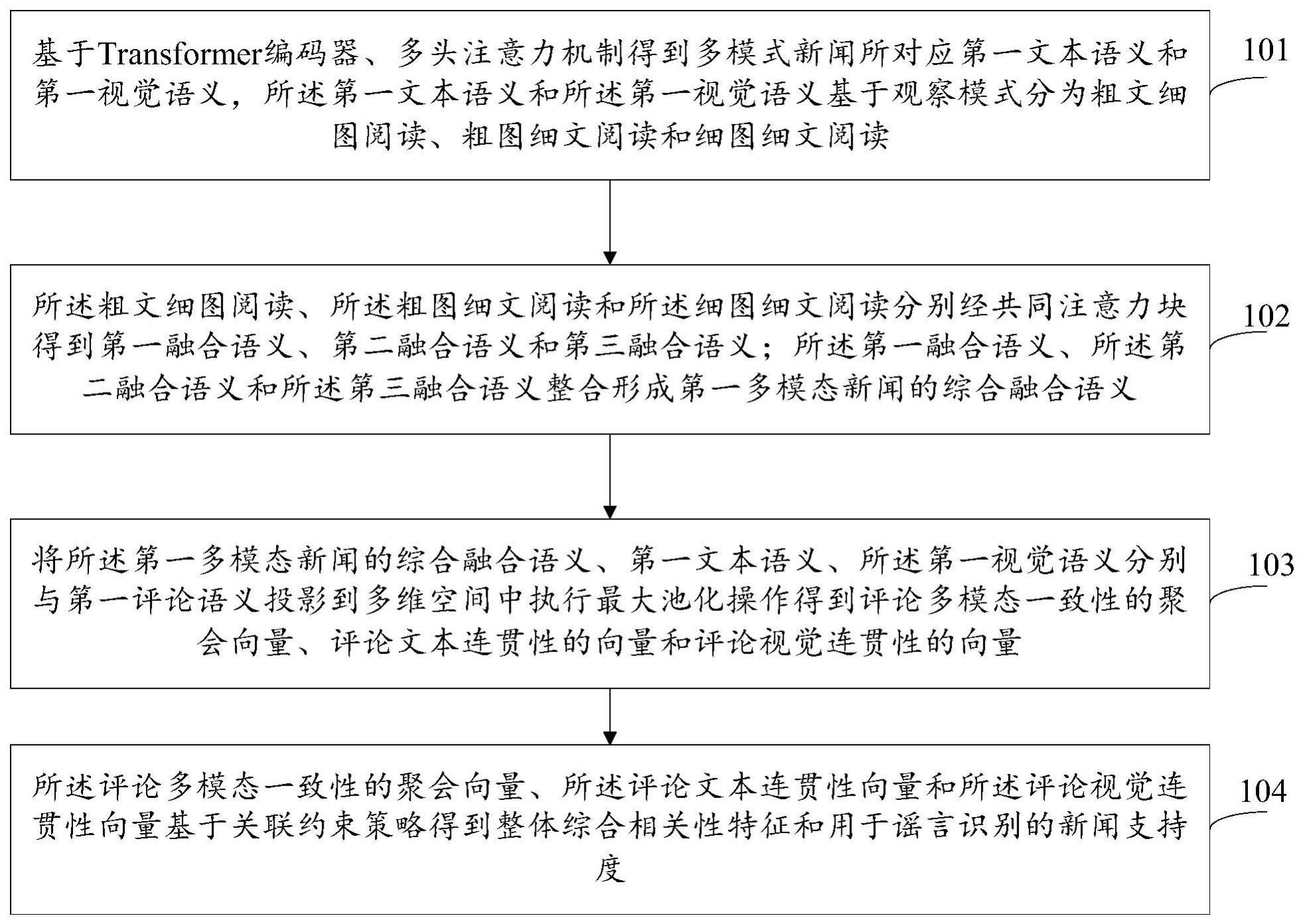
3、基于transformer编码器、多头注意力机制得到多模式新闻所对应第一文本语义和第一视觉语义,所述第一文本语义和所述第一视觉语义基于观察模式分为粗文细图阅读、粗图细文阅读和细图细文阅读;
4、所述粗文细图阅读、所述粗图细文阅读和所述细图细文阅读分别经共同注意力块得到第一融合语义、第二融合语义和第三融合语义;所述第一融合语义、所述第二融合语义和所述第三融合语义整合形成第一多模态新闻的综合融合语义;
5、将所述第一多模态新闻的综合融合语义、第一文本语义、所述第一视觉语义分别与第一评论语义投影到多维空间中执行最大池化操作得到评论多模态一致性的聚会向量、评论文本连贯性的向量和评论视觉连贯性的向量;
6、所述评论多模态一致性的聚会向量、所述评论文本连贯性向量和所述评论视觉连贯性向量基于关联约束策略得到整体综合相关性特征和用于谣言识别的新闻支持度。
7、优选地,所述粗文细图向同注意力块输入<et,v>,得到第一融合语义:
8、
9、所述粗图细文向同注意力块输入<ev,t>,得到第二融合语义:
10、
11、所述细图细文向同注意力块输入<et,ev>,得到第三融合语义:
12、
13、其中,et表示第一文本语义,ev表示第一视觉语义,v表示图像嵌入,t表示文本嵌入,htcir表示第一融合语义,hictr表示第二融合语义,hictc表示第三融合语义。
14、优选地,所述将所述第一多模态新闻的综合融合语义、第一文本语义、所述第一视觉语义分别与所述第一评论语义投影到多维空间,具体包括:
15、将所述第一评语语义和所述第一多模态新闻的综合融合语义投影到dm维公共潜在空间中,得到投影评语级语义和投影多模态新闻的综合融合语义;将所述投影评语级语义定义为查询矩阵,将投影多模态新闻的综合融合语义定义为键矩阵,得到评论多模态一致语义;
16、将所述第一评论语义和所述第一文本语义投影到dm维公共潜在空间中,得到投影评语级语义和投影文本级语义;将所述投影评语级语义定义为查询矩阵,将所述投影文本级语义定义为键矩阵,得到评论文本一致语义;
17、将第一评论语义所述第一视觉语义投影到dm维公共潜在空间中,得到投影评语级语义和投影视觉级语义;将所述投影评语级语义定义为查询矩阵,将所述投影视觉级语义定义为键矩阵,得到评论视觉一致语义。
18、优选地,所述评论多模态一致性的聚会向量通过下列公式确定:
19、
20、所述评论文本连贯性的向量通过下列公式确定:
21、
22、所述评论视觉连贯性的向量通过下列公式确定:
23、
24、其中,icm表示评论多模态一致性的聚会向量,ict表示评论文本连贯性的向量,icv表示评论视觉连贯性的向量,表示评论多模态一致性,表示表示评论文本连贯性,表示评论视觉连贯性。
25、优选地,所述评论多模态一致性的聚会向量、所述评论文本连贯性向量和所述评论视觉连贯性向量基于关联约束策略得到整体综合相关性特征,具体包括:
26、所述评论文本连贯性向量和所述评论多模态一致性的聚会向量通过下列公式确定整个合成相关特征:
27、
28、所述评论视觉连贯性向量和所述评论多模态一致性的聚会向量通过下列公式确定综合相关性特征:
29、
30、通过下列公式确定整体综合相关性特征:
31、mall=mlp(concat(mtm,mvm))
32、其中,mtm表示整个合成相关特征,mvm表示综合相关性特征,mall表示整体综合相关性特征,lct表示ict的长度,lcm表示icm的长度,lcv表示icv的长度。
33、优选地,所述用于谣言识别的新闻支持度通过下列公式确定:
34、im=concat(icv,icm,ict,mall)
35、其中,mall表示整体综合相关性特征,icm表示评论多模态一致性的聚会向量,icm表示评论多模态一致性的聚会向量,ict表示评论文本连贯性的向量,icv表示评论视觉连贯性的向量,im表示支持度。
36、本发明实施例提供一种多模态谣言识别装置,包括:
37、划分单元,用于基于transformer编码器、多头注意力机制得到多模式新闻所对应第一文本语义和第一视觉语义,所述第一文本语义和所述第一视觉语义基于观察模式分为粗文细图阅读、粗图细文阅读和细图细文阅读;
38、整合单元,用于所述粗文细图阅读、所述粗图细文阅读和所述细图细文阅读分别经共同注意力块得到第一融合语义、第二融合语义和第三融合语义;所述第一融合语义、所述第二融合语义和所述第三融合语义整合形成第一多模态新闻的综合融合语义;
39、第一得到单元,用于将所述第一多模态新闻的综合融合语义、第一文本语义、所述第一视觉语义分别与第一评论语义投影到多维空间中执行最大池化操作得到评论多模态一致性的聚会向量、评论文本连贯性的向量和评论视觉连贯性的向量;
40、第二得到单元,用于所述评论多模态一致性的聚会向量、所述评论文本连贯性向量和所述评论视觉连贯性向量基于关联约束策略得到整体综合相关性特征和用于谣言识别的新闻支持度。
41、优选地,所述粗文细图向同注意力块输入<et,v>,得到第一融合语义:
42、
43、所述粗图细文向同注意力块输入<ev,t>,得到第二融合语义:
44、
45、所述细图细文向同注意力块输入<et,ev>,得到第三融合语义:
46、
47、其中,et表示第一文本语义,ev表示第一视觉语义,v表示图像嵌入,t表示文本嵌入,htcir表示第一融合语义,hictr表示第二融合语义,hictc表示第三融合语义。
48、本发明实施例提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行上述任意一项所述的多模态谣言识别方法。
49、本发明实施例提供一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行上述任意一项所述的多模态谣言识别方法。
50、本发明实施例提供一种多模态谣言识别方法及装置,该方法包括:基于transformer编码器、多头注意力机制得到多模式新闻所对应第一文本语义和第一视觉语义,所述第一文本语义和所述第一视觉语义基于观察模式分为粗文细图阅读、粗图细文阅读和细图细文阅读;所述粗文细图阅读、所述粗图细文阅读和所述细图细文阅读分别经共同注意力块得到第一融合语义、第二融合语义和第三融合语义;所述第一融合语义、所述第二融合语义和所述第三融合语义整合形成第一多模态新闻的综合融合语义;将所述第一多模态新闻的综合融合语义、第一文本语义、所述第一视觉语义分别与第一评论语义投影到多维空间中执行最大池化操作得到评论多模态一致性的聚会向量、评论文本连贯性的向量和评论视觉连贯性的向量;所述评论多模态一致性的聚会向量、所述评论文本连贯性向量和所述评论视觉连贯性向量基于关联约束策略得到整体综合相关性特征和用于谣言识别的新闻支持度。本发明实施例提供的方法,首先通过单模态编码块对阅读文本或图像的深度进行建模,然后采用认知感知交互块对这三种习惯进行建模,为了捕获不同模态之间的不一致性语义,构建了一致性约束推理层,强化评论对新闻的不同模态特征的一致性度量,并通过约束策略挖掘不一致特征,进行谣言识别,该方法能够有效挖掘多模态特征之间的关系,更好地且深层次地对谣言的多模态信息进行融合。
- 还没有人留言评论。精彩留言会获得点赞!