基于服务组合超图卷积网络的云计算数据推荐方法
本发明涉及一种基于服务组合超图卷积网络的云计算数据推荐方法。
背景技术:
1、服务计算、分布式计算和容器化技术的融合发展,推动着云原生时代的到来。作为云原生架构的核心的底层实现,云计算提供了弹性、统一的基础设施服务。云计算可以实现按需、弹性、灵活地从可配置计算资源共享池中获取资源(例如,存储、算力、网络、服务、数据等)。云计算正在成为信息技术产业发展的战略重点,在云计算潮流的推动下,企业和组织纷纷将产品管理、人事系统、财务管理等业务流程部署至云端,产生了海量的云计算数据。利用合理的算法和模型深度挖掘云计算数据,获取的信息和知识在服务计算、推荐系统、金融分析、工程设计等领域得到了广泛的应用。
2、在推荐系统领域中,分析、挖掘云计算数据有利于实现个性化推荐,提高推荐结果的关联性和精确度。例如,专利号为201911411071.x,名称为一种基于云计算的科普内容个性化推荐系统通过搜索播放模块、历史浏览信息记录模块和自动填写模块配合,将云计算数据应用于科普内容的个性化推荐。专利号为201710742043.0,名称为一种基于云计算的智能服务推荐方法运用逻辑回归算法进行精确服务选择决策,解决了现有服务推荐算法计算量大、效率低的技术问题。专利号为201510072895.4,名称为一种基于云计算的冷启动项目推荐的方法及装置根据所述评分数信息和贝叶斯算法计算用户喜欢的项目中包含冷启动数据的概率,提高了冷启动项目的推荐准确度。
3、在服务计算的应用场景下,云计算数据中蕴含丰富的服务功能、服务调用、服务组合信息,具有较高的分析价值。其中,服务组合指两种或两种以上api服务进行组合、混搭,构建出具有新功能的api服务。服务组合关系从侧面上反应了api服务之间的关联性和互补性。如果两项api服务之间含有多种服务组合关系,那么这两项api服务之间具有较强的关联性。通过对服务组合关系的合理建模,并将其应用于推荐系统中,有助于提高推荐结果的关联性和精确度。
技术实现思路
1、为克服现有云计算数据推荐方法存在的推荐结果关联度较低、精确度不高等不足,本发明提供了一种关联度较高、降低计算复杂度和过拟合风险、提高推荐结果的精确度的基于服务组合超图卷积网络的云计算数据推荐方法,首先,对云计算数据进行深度挖掘,得到用于表示潜在服务组合关系的序列组合集;其次,利用序列组合集构建服务组合超图,实现组合特征的有效建模;然后,基于切比雪夫近似卷积思想,设计超图卷积网络提取服务组合超图上的超图信号;考虑到超图卷积操作存在较高的过拟合风险,使用hg-pool(hypergraph pool)超图池化方法降低超图信号的特征维度;最后,融合api服务的语义编码结果和降维后的超图信号,计算api服务的推荐概率并进行推荐。
2、本发明所采用的技术方案是:
3、一种基于服务组合超图卷积网络的云计算数据推荐方法,包括以下步骤:
4、步骤一:挖掘云计算数据中的潜在服务组合关系,构建序列组合集;
5、步骤二:基于步骤一中的序列组合集构建服务组合超图,实现对api服务的组合特征的有效建模,超图是一种特殊的图数据结构,其中的边可以连接任意数量的节点;
6、步骤三:根据切比雪夫近似卷积的思想,设计超图卷积网络提取服务组合超图上的超图信号;然后,使用hg-pool池化方法对超图信号进行降维处理;
7、步骤四:利用预训练语言模型对api服务进行语义编码,得到语义嵌入向量,融合语义嵌入向量和超图信号,得到组合嵌入向量,最后,利用组合嵌入向量和超图信号计算api服务的推荐概率,得到推荐结果;预训练语言模型是深度学习中的一种自然语言处理方法,具有词向量编码功能。
8、进一步,所述步骤一的过程如下:
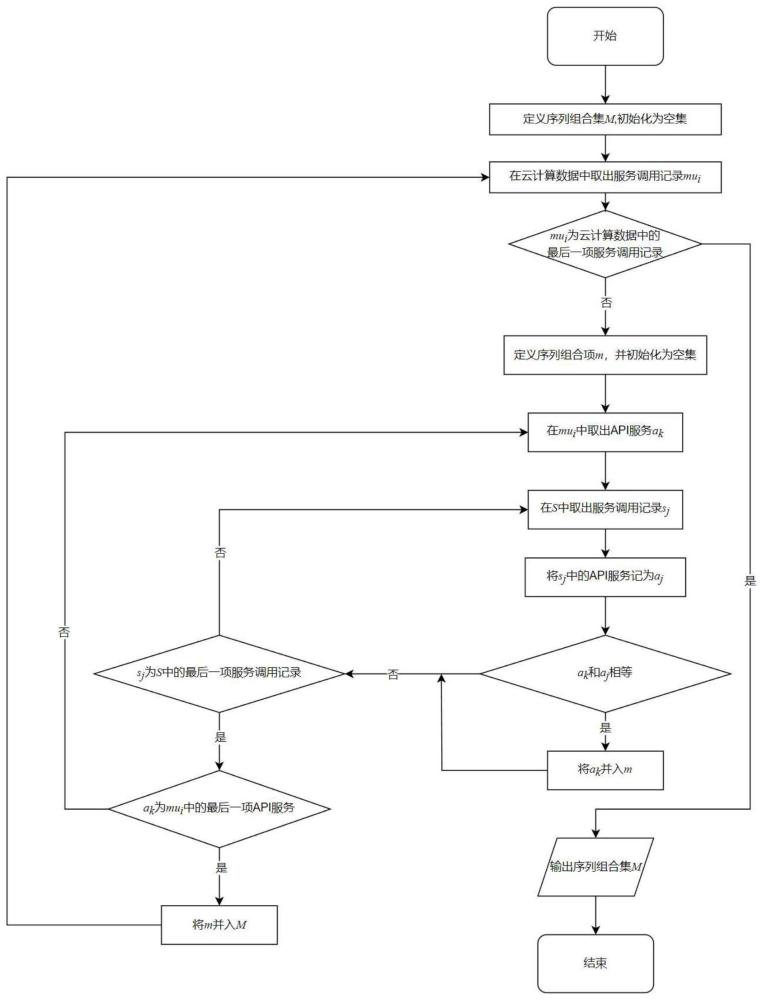
9、1.1云计算数据:在云计算环境下,用户与api服务之间的调用数据,包括api服务、服务调用序列、服务组合;
10、1.2api服务:应用程序接口(applicationprogramminginterface,api)使用符号a表示;
11、1.3服务调用序列:按时间顺序对用户的api服务调用记录进行排序,排序结果称为服务调用序列,使用符号s表示;
12、1.4服务组合:两种或两种以上api服务进行组合、混搭,构建出具有新功能的api服务,用符号mu表示;
13、1.5挖掘服务组合关系,构建序列组合集:遍历服务调用序列,按照服务组合关系抽取api服务。从服务调用序列中抽取得到具有服务组合关系的api服务集合定义为序列组合项,用符号m表示,将所有的序列组合项构成的集合定义为序列组合集,用符号m表示。
14、优选的,所述1.5中,构建序列组合集的过程如下:
15、1.5.1定义序列组合集m,并初始化为空集合;
16、1.5.2遍历云计算数据中的所有服务组合,将第i次取到的服务调用记录记为mui;
17、1.5.3定义序列组合项m,并初始化为空集合;
18、1.5.4遍历mui中的api服务,将第k次取到的api服务记为ak;
19、1.5.5遍历服务调用序列s,将第j次取到的服务调用记录记为sj;
20、1.5.6将服务调用记录中的api服务用符号aj表示;
21、1.5.7若aj和ak相等,则将ak并入序列组合项m;否则,跳转至步骤1.5.5;
22、1.5.8当sj为服务调用序列中的最后一项服务调用记录时,结束遍历;
23、1.5.9当ak为mui中的最后一项api服务时,结束遍历;
24、1.5.10将m并入m;
25、1.5.11当mui为云计算数据中的最后一项服务组合时,结束遍历;
26、1.5.12输出序列组合集m。
27、再进一步,所述步骤二的过程如下:
28、2.1构建服务组合超图的超点集:对服务组合和服务调用序列进行集合运算,
29、取两者的交集,将交集转化为服务组合超图中的超点,并将其加入超点集;
30、服务组合超图的超点集构建过程如下:
31、2.1.1创建超点集v,将其初始化为空集合;
32、2.1.2遍历云计算数据中的所有服务组合,将第i次取到的服务调用记录记为mui;
33、2.1.3将mui中所有的api服务记为集合mseti;
34、2.1.4将服务调用序列中所有的api服务记为集合sset:
35、2.1.5对sset和mseti进行集合运算,取两者的交集,用符号nseti表示;
36、2.1.6遍历nseti,将集合中第j项api服务记为aj;
37、2.1.7若超点集v中不存在下标为j的超点vj,则创建超点vj将其加入v;
38、2.1.8若v中存在vj,则跳转至步骤2.1.6;
39、2.1.9当aj为nseti中的最后一项api服务时,结束遍历;
40、2.1.10当mui为云计算数据中的最后一项服务组合时,超点集创建完毕,结束遍历。
41、2.2构建服务组合超图的超边集:创建超点集,定义关联矩阵描述超点和超边之间的连接关系,遍历序列组合集和超点集,根据序列组合项与超点对应的api服务的包含关系构建连接关系;服务组合超图的超边集的创建过程如下:
42、2.2.1创建超边集e,并将其初始化为空集合;
43、2.2.2定义关联矩阵h,用于描述超点和超边之间的连接关系,将其初始化为空矩阵;
44、2.2.3遍历序列组合集m,取出的序列组合项用符号mk表示;
45、2.2.4创建超边ek;
46、2.2.5遍历超点集v,将第i次取到的超点记为vj;
47、2.2.6找出vj相应的api服务aj;
48、2.2.7若序列组合项mk含有aj,则将超边ek与超点vj相连接,否则,跳转至步骤2.2.5;
49、2.2.8在关联矩阵h中,将第j行k列矩阵元素赋值为1;
50、2.2.9当vj是v中的最后一个超点时,结束遍历;
51、2.2.10若ek至少连接了两个不同的超点,则将ek并入e,否则,删去ek;
52、2.2.11当mk是m中的最后一项序列组合项时,超边集创建完毕,结束遍历。
53、2.3构建服务组合超图,并将其改写为矩阵形式:服务组合超图是对服务调用关系的建模,其结构可以用符号g=(v,e)来表示,其中g代表服务组合超图,v表示超点集,e表示超边集,为了提取超图信号,将服务组合超图改写为矩阵形式;将超图改写为矩阵形式的过程如下:
54、2.3.1定义超边度矩阵de,用于记录任意超边和不同超点之间的连接关系;
55、2.3.2对de进行初始化,de行数和列数均为e中的超边数,遍历de的对角线元素,第j行j列的对角线元素赋值为ej连接的所有超点的数量,其余矩阵元素赋值为0;
56、2.3.3定义邻接矩阵作为服务组合超图的矩阵形式,其表达式为θ=ht·de·h,其中,θ代表邻接矩阵,h为2.2.2中定义的关联矩阵,“t”是矩阵的转置符号,“.”是矩阵的乘法符号,“=”是矩阵的赋值符号。
57、再进一步,所述步骤三的过程如下:
58、3.1服务组合超图上的近似卷积:首先,定义超图的拉普拉斯矩阵和超图卷积过程,然后,根据切比雪夫近似卷积思想,对超图卷积过程展开求解,得到超图信号,超图信号的提取过程如下:
59、3.1.1定义服务组合超图的拉普拉斯矩阵,用符号l表示;
60、3.1.2初始化拉普拉斯矩阵,其表达式为l=i-θ。式中,i为单位矩阵,符号“-”代表矩阵减法;
61、3.1.3定义超图卷积网络的卷积核,用符号ρ表示,超图的卷积核实质上是深度学习中滤波器,其数学形式是二维矩阵;
62、3.1.4定义服务组合超图上的超图信号,用符号x表示,超图信号是服务组合关系的向量表示;
63、3.1.5定义服务组合超图上的超图卷积操作,用符号*表示,整个超图卷积过程可定义为x*ρ;
64、3.1.6根据切比雪夫近似卷积思想,步骤3.1.5中定义的超图卷积过程用切比雪夫多项式展开求解,其表达式为式中,∑代表求和运算,上标n代表近似的最大阶数,下标n代表每次求和的阶数,μn是n阶切比雪夫多项式系数,是缩放的拉普拉斯矩阵l的n阶多项式,符号“≈”代表约等于;
65、3.1.7选用一阶切比雪夫卷积算子进行求解,超图信号提取过程可进一步改写为x*ρ≈τ·θ·x。式中,τ为卷积核ρ的参数;
66、3.1.8输出超图信号x。
67、3.2利用hg-pool方法池化降维超图信号:首先,对邻接矩阵进行采样,得到赋值矩阵;然后,利用赋值矩阵对邻接矩阵进行池化,池化结果用符号θ′表示;最后,使用θ′替换步骤3.1.2和3.1.7中的θ,再次进行步骤3.1,得到降维后的超图信号x′;超图信号的池化降维过程如下:
68、3.2.1定义采样器hg,采样器是一种深度学习部件,用于获取图神经网络模型中指定节点周围的邻居节点信息;
69、3.2.2利用hg对θ进行采样,采样结果定义为赋值矩阵,用符号a表示;
70、3.2.3利用赋值矩阵对邻接矩阵进行池化,其过程用表达式θ′=at·θ·a表示,式中,θ′是池化结果;
71、3.2.4使用θ′替换步骤3.1.2中的θ,重新进行拉普拉斯矩阵的初始化;
72、3.2.5使用θ′替换步骤3.1.7中的θ,重新进行超图信号的求解;
73、3.2.6利用步骤3.1得到降维后的超图信号,使用符号x′表示。
74、所述步骤四的过程如下:
75、4.1对api服务进行语义编码:将api服务的描述文档输入预训练语言模型,得到语义嵌入向量;
76、4.2融合语义嵌入向量和超图信号,得到组合嵌入向量:将步骤4.1中的语义嵌入向量与步骤3.2中池化后的超图信号相拼接,得到组合嵌入向量,用符号z表示;
77、4.3计算推荐概率,得到推荐结果:利用语义嵌入向量和组合嵌入向量,计算每个api服务的推荐分数;然后,利用推荐分数产生推荐概率,得到推荐概率后,选取概率最高api服务作为推荐结果。
78、优选的,所述4.1中,语义嵌入向量的编码过程如下:
79、4.1.1定义超参数h,用于控制推荐结果的数量;
80、4.1.2遍历云计算数据中的所有api服务,将第i次取到的api服务记为ai;
81、4.1.3将ai的功能描述文档输入预训练语言模型,得到语义嵌入向量,用符号yi表示,功能描述文档是一段关于api服务的功能介绍文本信息;
82、4.1.4当ai为云计算数据中的最后一项api服务时,结束遍历。
83、再优选的,所述4.3中,计算推荐概率并进行推荐的过程如下:
84、4.3.1遍历云计算数据中的api服务,将第i次取到的api服务记为ai;
85、4.3.2定义ai的推荐分数,用符号sei表示;
86、4.3.3定义指数形式的推荐分数,用符号表示;
87、4.3.4基于步骤4.1对ai进行语义编码,得到语义嵌入向量yi;
88、4.3.5基于步骤4.2得到组合嵌入向量z;
89、4.3.6计算z的转置与yi的乘积,并对乘积进行归一化处理,归一化处理后的结果用符号yi′表示,归一化处理是深度学习中的一种预处理方法,能将原始数据值映射到[0,1]之间;
90、4.3.7将yi′赋值给sei;
91、4.3.8对自然常数e进行指数运算,其指数为yi′,将计算结果赋值给
92、4.3.9当ai为云计算数据中最后一项api服务时,遍历结束;
93、4.3.10累加所有的指数形式的推荐分数,结果用符号∑ese表示;
94、4.3.11遍历云计算数据中的api服务,将第j次取到的api服务记为aj;
95、4.3.12定义aj的推荐概率rmj;
96、4.3.13用aj的推荐分数除以∑ese,将计算结果赋值给rmj;
97、4.3.14当aj为云计算数据中最后一项api服务时,遍历结束;
98、4.3.15按照推荐概率的大小对api服务进行排序;
99、4.3.16选取推荐概率较高的前h项服务,作为推荐结果。
100、本发明的有益效果在于:(1)通过挖掘并利用云计算数据中潜在的服务组合关系,克服了现有推荐方法关联度较低的不足;(2)设计服务组合超图,实现对服务组合关系的有效建模;(3)将近似卷积和超图池化相结合,降低了超图卷积过程中的计算复杂度和过拟合风险;(4)融合语义编码信息和超图信号,提高推荐结果的精确度。
- 还没有人留言评论。精彩留言会获得点赞!