基于大语言模型的两阶段Text2SQL模型、方法与系统与流程
本发明涉及自然语言处理和结构化查询语句的生成,尤其是一种基于大语言模型的两阶段text2sql模型、方法与系统。
背景技术:
1、当前是信息社会,各种数据库中的信息浩如烟海,当需要查询信息时,常规手段是将描述转化为sql查询语句,再交给计算机去执行,就能方便地对数据库进行查询,大大提高了生活和工作效率。
2、text2sql是当前常用的转化自然语言描述为sql查询语句的技术,但是现有技术方案主要分为三个方向:
3、1.基于sql语法解析和规则解析进行sql生成
4、2.基于传统小模型例如bert进行端到端sql生成
5、3.基于大语言模型(如chatgpt,gpt-4),不进行有监督微调,直接使用prompt进行查询与问答
6、这几种方法存在以下缺点:
7、1.需要基于现有规则构建模板,消耗人力,且整体流程和分解的子任务较为复杂
8、2.对复杂sql语句例如嵌套查询、多表查询的信息构建能力不足
9、3.无法利用已训练模型的先验知识,可迁移性和可拓展性较差
10、4.直接使用prompt无法利用领域内的专家知识,使得回答的内容准确性较差;且输出sql质量受限于大语言模型本身能力,无法进行优化。
11、可见,当前的text2sql技术还有很大的进步空间。
技术实现思路
1、为了克服上述现有技术中text2sql技术的缺陷,本发明提出了一种基于大语言模型的两阶段text2sql模型,简化了text2sql问题的难度的同时,也增强了模型生成高质量和复杂的sql语句的能力。
2、参照图1,本发明提出的一种基于大语言模型的两阶段text2sql模型的训练方法,包括以下步骤:
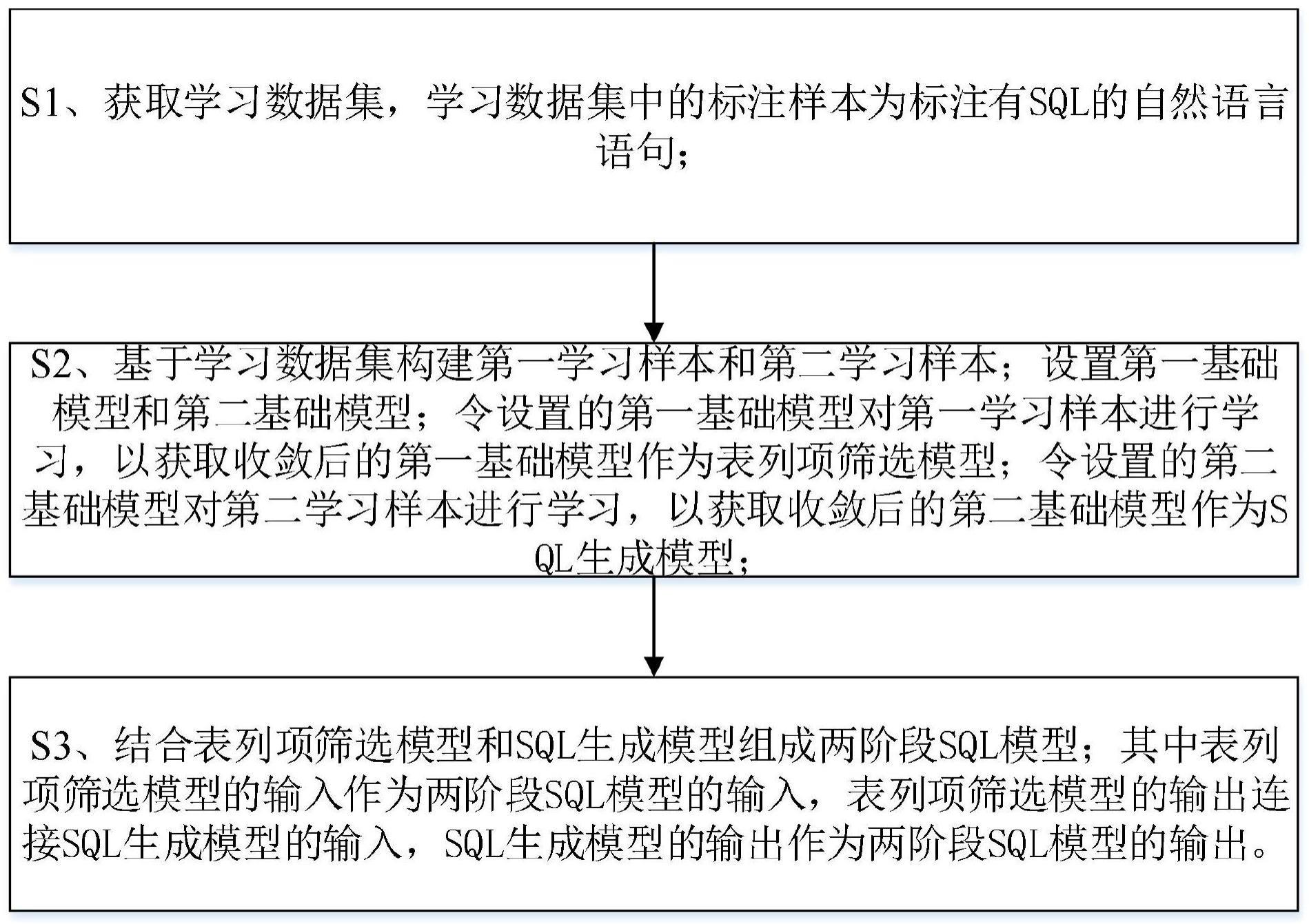
3、s1、基于指定内容数据库获取学习数据集,学习数据集中的标注样本为标注有sql的自然语言语句;
4、s2、基于学习数据集构建第一学习样本和第二学习样本;第一学习样本为标注有对应指定内容数据库的目标表列项的自然语言语句;第二学习样本包括自然语言语句及其对应的目标表列项、目标表列项存储内容的概括值以及标注的sql;表列项包括表名称和该表中任一列的列名称;
5、设置第一基础模型和第二基础模型;第一基础模型的输入为自然语言语句和指定内容数据库中所有的表列项,第一基础模型的输出为表列项分布概率;第二基础模型的输入包括自然语言语句及其目标表列项、目标表列项存储内容的概括值,第二基础模型的输出为自然语言语句的sql;
6、令设置的第一基础模型对第一学习样本进行学习,以获取收敛后的第一基础模型作为表列项筛选模型;令设置的第二基础模型对第二学习样本进行学习,以获取收敛后的第二基础模型作为sql生成模型;
7、s3、结合表列项筛选模型和sql生成模型组成两阶段sql模型;其中表列项筛选模型的输入作为两阶段sql模型的输入,表列项筛选模型的输出连接sql生成模型的输入,sql生成模型的输出作为两阶段sql模型的输出。
8、优选的,s2中,目标表列项存储内容的概括值的获取方式为:
9、如果目标表列项存储内容为离散值,则概括值为存储内容去重后的结果;
10、如果目标表列项存储内容为连续值,则概括值为存储内容所在区间值。
11、优选的,s2具体包括以下分步骤:
12、s21、基于学习数据集构建第一学习样本,令第一基础模型对第一学习样本进行机器学习,以获取表列项筛选模型;
13、s22、选择部分标注样本作为备选第二学习样本,将各备选第二学习样本中的自然语言语句输入表列项筛选模型,获取表列项筛选模型输出的表列项分布概率中最大的n个概率值对应的表列项作为目标表列项;
14、s23、获取备选第二学习样本中自然语言语句的目标表列项存储内容的概括值,结合备选第二学习样本的自然语言语句、目标表列项、目标表列项存储内容的概括值以及sql构成第二学习样本;
15、s24、令第二基础模型对第二学习样本进行机器学习,获取sql生成模型。
16、优选的,s1中学习数据集的获取,包括以下分步骤:
17、s11、从指定内容数据库中获取样本构成数据集,样本包含自然语言语句和sql,对数据集中各自然语言语句的sql进行打分,根据打分将自然语言与语句分为多个难度等级;
18、s12、获取数据集中各难度等级上的自然语言语句数量分布,判断该分布趋势是否为设定的分布趋势;是,则将该数据集作为学习数据集;否,则执行步骤s13;
19、s13、对数据集中的自然语言语句进行增减调整,然后返回步骤s11。
20、优选的,s11中对sql进行打分的方式为:统计sql包含的关键词和内置函数的数量总数作为分数,分数越高表示自然语言语句难度越大。
21、优选的,s1中还包括对标注样本中的sql进行标准化处理,标准化处理包括:全体大写或是小写、字符常量统一使用单引号或是双引号、所有列名统一补齐表格名、字符统一空一个格。
22、优选的,第一基础模型采用自然语言模型,第一基础模型进行机器学习过程中,结合各第一学习样本的目标表列项在表列筛选模型输出的表列项分布概率中的概率值计算均方差损失,根据均方差损失反向更新表列筛选模型;sql生成模型训练过程中结合交叉熵损失函数采用peft技术对预训练的第二基础模型进行微调。
23、本发明提出的一种sql查询方法,其特征在于,包括以下步骤:
24、st1、采用如权利要求1-7任一项所述的基于大语言模型的两阶段text2sql模型的训练方法获取指定内容数据库对应的两阶段sql模型;
25、st2、将待查询的自然语言语句和目标内容数据库中所有的表列项输入两阶段sql模型,两阶段sql模型输出待查询的自然语言语句的sql作为备选sql;
26、st3、对备选sql进行标准化处理,然后将备选sql根据设定的多条转换规则转换成相对应的目标sql;
27、st4、在任意类型的目标内容数据库中顺位执行各目标sql,直至目标内容数据库上目标sql执行成功;数据库类型指的是数据库的内容存储形式。
28、本发明提出的一种sql查询系统,包括存储器和处理器,存储器存储有计算机程序,处理器与存储器连接,处理器用于执行所述计算机程序以实现所述的sql查询方法。
29、本发明提出的一种sql查询系统,包括:两阶段sql模型、转换模块、规则库和执行模块;
30、两阶段sql模型用于输出获取的自然语言语句的sql作为备选sql;
31、规则库中存储有一种或者多种转换规则,转换规则用于将sql转换为适用于其对应类型的数据库的sql;
32、执行模块外接数据库,用于加载目标sql在数据库中进行sql查询;
33、转换模块分别连接两阶段sql模型、规则库和执行模块;
34、转换模块获取两阶段sql模型输出的备选sql,转换模块加载规则库中的转换规则,转换模块根据加载的各项转换规则对备选sql进行转换,获取与转换规则一一对应的目标sql;执行模块获取各目标sql;当进行指定类型数据库查询时,执行模块在指定类型数据库中依次执行各目标sql,直至执行成功。
35、本发明的优点在于:
36、(1)本发明整体方案分成两阶段,第一阶段是确定输入的自然语言在指定内容数据库中所需要的表和列;第二阶段,根据第一阶段选出的表和列,使用大模型进行seq2seq的任务,完成sql的生成。将整个text2sql流程拆分成选表列和生成sql两阶段,并分别训练小模型和预训练大语言模型来完成这两阶段任务,因此模型的数据构建和使用都具有较强的可拓展性,可很好的支持多表查询和复杂语句生成,并具有较强专业领域适配性。
37、(2)两阶段的训练均需要足够数量的高质量数据集,本发明设计了一套sql难度打分体系和标签体系,可用于评估训练集是否难度分布适中且拥有足够多样性。如此,本发明结合sql打分对数据集进行增强,保证了模型训练阶段数据集的样本多样性,从而有利于提高模型精度。
38、(3)本发明采用两阶段训练方法,简化了text2sql问题的难度的同时,也增强了模型生成高质量和复杂的sql语句的能力,并基于现有的开源大模型,充分利用了其先验语言知识,使得本发明具有很好的泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!