一种基于场景先验感知的目标数据生成方法
本发明属于深度学习,具体涉及一种基于场景先验感知的目标数据生成方法。
背景技术:
1、由于典型的数据易获取,近年来基于深度学习的目标检测算法取得了理想的性能。然而,对于一些重要的敏感目标,如航母、巡洋舰等,当我们有对这些目标在特定的背景下完成目标检测的需求时,图像的获取还存在着一定的困难。对于这些特定背景下的敏感目标,如海上行驶的舰队,停靠在港口的舰船,现有的高分辨率的图像数据集的数据量都较小。面对这种情况,研究者们提出了数据集生成,运用图像变换及机器学习的方式最大限度地发挥小样本数据的可用性,解决数据量不够的问题。
2、针对图像的数据生成方法,可以分为单数据变形方法和多数据变形方法。单数据变形方法主要采用几何变换、颜色变换等图像变换方法。多数据变形除了几何变换、颜色变换等方法外,还有学习数据分布的方法,主要是基于生成对抗网络和图像风格迁移的方法。
3、在单数据变形方法中,yun等人在文献“s.yun,d.han,s.oh,s.chun,j.choe,andy.yoo.cutmix:regularization strategy to train strong classifiers withlocalizable features.ieee/cvf international conference on computer vision,6023-6032,2019.”中提出了cutmix算法通过嵌入图像部分内容形成新的数据完成数据生成。在多数据变形方法中,isola等人在文献“p.isola,j.zhu,t.zhou,and a.alexei,image-to-image translation with conditionaladversarial networks.ieeeconference on computer vision and pattern recognition,1125-1134,2017.”中提出了pix2pix算法,它的目标是实现图像的转换,在训练时候需要采用成对的训练数据。
4、现有的单样本变形方虽能在短时间内生成大量图像,但图像人工合成痕迹较重。多样本变形方法虽能生成逼真的图像,但需要较多样本数据用于训练。
技术实现思路
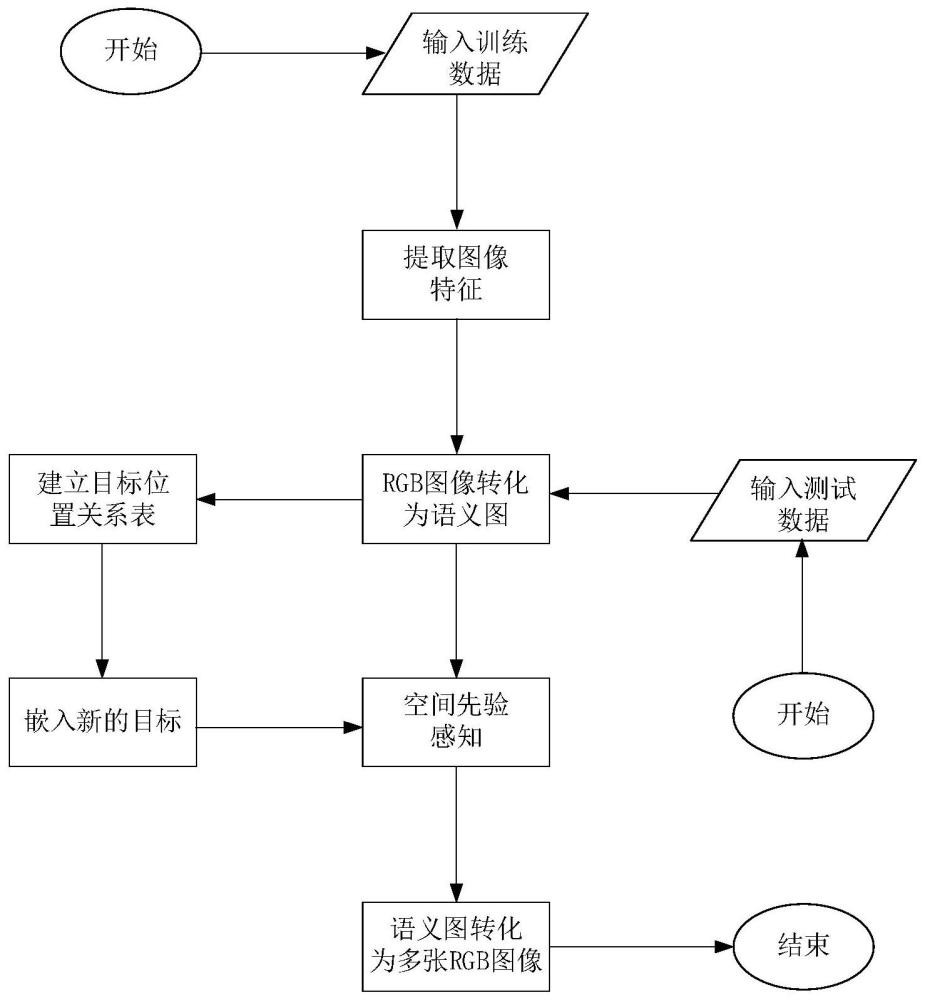
1、为了克服现有技术的不足,本发明提供了一种基于场景先验感知的目标数据生成方法,首先准备训练和测试数据集,构建舰船-语义图数据集;通过基于pix2pix的重构网络完成实际图与语义图的相互变换;再通过场景先验感知的方法确定图像要素之间的位置关系;最终将生成的数据与样本数据一同进行目标检测,计算检测的正确率。本发明方法通过提取生成目标的位置信息,获得目标之间和目标与环境位置关系,使生成的数据符合人们的认知。
2、本发明解决其技术问题所采用的技术方案包括如下步骤:
3、步骤1:准备训练和测试数据集;
4、选取n张海上舰队图像进行标注,标注包含舰队补充信息的语义分割数据,构建舰船-语义图数据集;
5、步骤2:通过基于pix2pix的重构网络完成实际图与语义图的相互变换;在基于pix2pix的重构网络中,在生成器部分采用多尺度判别器和对抗性损失;
6、步骤3:通过场景先验感知的方法确定图像要素之间的位置关系;
7、步骤4:将通过步骤2与步骤3后生成的数据与舰船-语义图数据集一同进行目标检测,计算检测的正确率。
8、优选地,所述步骤1具体为:
9、步骤1-1:人工标注550对真实图像与其对应的语义图,大小为256×256像素;真实图像包含的元素有多艘各类别军舰组成的舰队、海洋和天空;
10、步骤1-2:将标注的数据集按10:1的标准划分训练集和测试集,其中随机选取500对图像作为训练集,50对图像作为测试集。
11、优选地,所述步骤2具体为:
12、步骤2-1:基于pix2pix的重构网络由全局生成器网络和判别器网络组成,生成器将与判别器博弈生成判别器认为是真实图像的图片;
13、步骤2-2:全局生成器网络由生成器网络g1和局部增强器网络g2组成,将256*256像素真实图像作为输入,局部增强器网络中每一层输出的图像像素是前一层输出图像像素大小的4倍,即长宽各为前一张图像的两倍,以更高的像素与g1输出的图像合成新的图像;在生成的过程中采取先降维再升维的方式;全局生成器由3个部分组成:卷积前端、残差块组和转置卷积后端;将像素为256×256的语义标签依次通过3个组件映射,输出像素为256×256的语义图像;
14、步骤2-3:判别器结构中使用多尺度判别器,包括3个判别器,具有相同的网络结构,但在不同的图像尺度上工作,这3个判别器分别被称为d1、d2和d3;
15、步骤2-4:使用三个损失函数;
16、条件损失具体的目标如公式(1)所示:
17、lcgan(g,d)=ex,y[log(d(x,y))]+ex,z[log(1-d(x,g(x,z)))] (1)
18、特征匹配损失将判别器dk,k=1,2,3的第p层特征提取器表示为然后计算特征匹配损失如公式(2)所示:
19、
20、一致性损失函数用于确定细节之间的位置变化,如公式(3)所示:
21、lm(g,d,x,y)=ex[x*g(d(x))-d(x)]+ey[y*g(d(y))-d(y)] (3)
22、其中,g(.)代表生成网络,d(.)代表判别网络,x和y分别代表真实的rgb图像和对应的标签语义图,np表示输入图像的像素大小,ex,y[.]表示输入图像与输出图像间的损失,ex,z[.]表示输入图像与输入条件间的损失,e(s,x)表示输入图像与输出图像间的损失,t表示输入图像数量,ex[.]表示从真实图像到语义图像转换的损失,ey[.]表示从语义图像到真实图像转换的损失;
23、最终的完整损失将条件损失、特征匹配损失和一致性损失结合为如下公式(4):
24、
25、其中λ1和λ2为加权系数。
26、优选地,所述λ1的值为0.8,λ2的值为0.2。
27、优选地,所述步骤3具体为:
28、步骤3-1:将目标之间的距离、目标与周围环境的距离维护在位置分布表中,在采用裁剪填充的过程中引用这张表,通过先验感知方法确定生成目标的位置分布,最终得到变换后的语义图,将标注的语义-舰船图像数据集作为训练集,该数据集的图像中包含天空、舰船和海洋三个元素;
29、步骤3-2:在建立位置分布表后,将训练集中随机一张图像x中的目标作为裁剪填充的目标;然后,通过建立的图表和目标图像中的位置分布选择一块区域,并将其从x中剪切出来的目标粘贴到中选定的目标,并计算新图像的标签;
30、最终,将这个新图像用于后续生成式对抗网络的生成器部分,其中,具体的裁剪填充公式如下所示:
31、
32、其中,参数m是位置分布表中的具体位置分布关系确定目标在图像中的具体位置,xa为通过步骤2生成的语义图像,xb为需要添加的舰船的语义图像。
33、本发明的有益效果如下:
34、本发明通过对目标间位置关系信息的利用,生成10倍以上相同风格图像数据。将生成的数据与样本数据共同组成新的数据集进行目标检测,正确率达到了90%以上。为了提高卷积神经网络分类器的性能,提出了提高区域注意力的策略,提升生成的数据细节处清晰度。
- 还没有人留言评论。精彩留言会获得点赞!