面向全天候场景的自监督单目深度估计方法及装置
本技术涉及图像深度估计,特别涉及一种面向全天候场景的自监督单目深度估计方法及装置。
背景技术:
1、目前,在增强现实、3d重建、自动驾驶汽车、位置识别等领域从2d(twodimensional,二维)的rgb图像中估计深度技术得到广泛应用。其中,自监督单目深度估计引起了越来越多研究人员的关注,尤其是基于深度卷积神经网络的自监督单目深度估计。
2、相关技术中,主要利用白天图像进行自监督单目深度估计,即基于白天图像的基准进行自监督单目深度估计,以解决白天图像的自监督单目深度估计问题。
3、然而,相关技术中,由于白天图像和夜间图像之间存在较大的域差异,阻碍了自监督单目深度估计在真实场景中的部署和应用,即使用场景过于单一,难以从夜间图像中有效地提取深度特征,难以利用一个共享编码器提取不同场景下数据域的一致性特征,模型域自适应能力低下,亟需改进。
技术实现思路
1、本技术提供一种面向全天候场景的自监督单目深度估计方法及装置,以解决相关技术中,使用场景过于单一,难以从夜间图像中有效地提取深度特征,难以利用一个共享编码器提取不同的数据域的一致性特征,模型域自适应能力低下等问题。
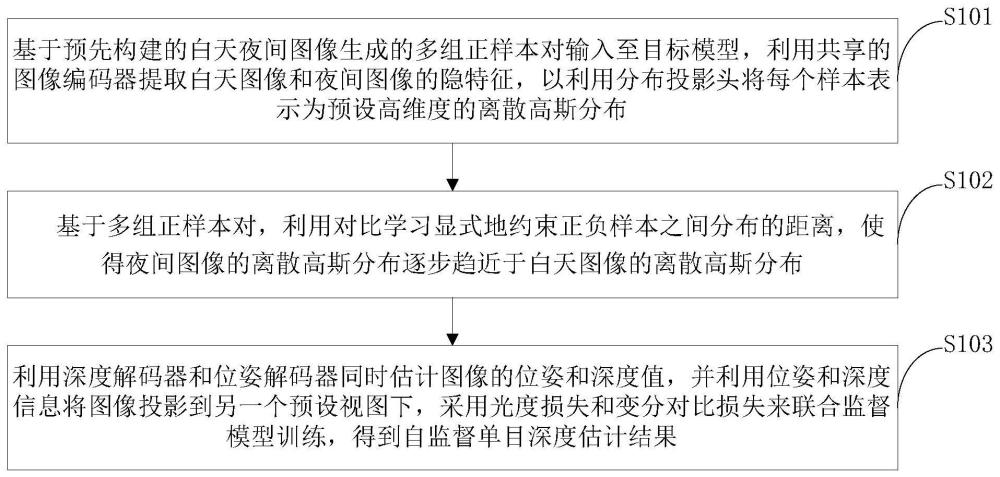
2、本技术第一方面实施例提供一种面向全天候场景的自监督单目深度估计方法,包括以下步骤:将基于预先构建的白天-夜间图像生成的多组正样本对输入至目标模型,利用共享的图像编码器提取所述白天图像和夜间图像的隐特征,以利用分布投影头将每个样本表示为预设高维度的离散高斯分布;基于所述多组正样本对,利用对比学习显式地约束正负样本之间分布的距离,使得所述夜间图像的离散高斯分布逐步趋近于所述白天图像的离散高斯分布;以及利用深度解码器和位姿解码器同时估计图像的位姿和深度值,并利用位姿和深度信息将所述图像投影到另一个预设视图下,采用光度损失和变分对比损失来联合监督模型训练,得到自监督单目深度估计结果。
3、可选地,在本技术的一个实施例中,所述将基于预先构建的白天-夜间图像生成的多组正样本对输入至目标模型,包括:利用cyclegan生成与训练数据中每张白天图像相对应的夜间图像;将所有的训练数据构建为白天-夜间样本对,得到所述多组正样本对,并将所述多组正样本对输入至所述目标模型。
4、可选地,在本技术的一个实施例中,所述基于所述多组正样本对,利用对比学习显式地约束正负样本之间分布的距离,使得所述夜间图像的离散高斯分布逐步趋近于所述白天图像的离散高斯分布,包括:利用两层的第一全连接神经网络将每个样本的特征投影到均值空间中,获取每个维度高斯分布的均值;利用两层的第二全连接神经网络将所述每个样本的特征投影到与所述均值空间维度相同的标准差空间中,获取每个维度高斯分布的标准差;基于所述均值和所述标准差,利用每个样本所对应的均值向量和方差向量将所述每个样本表示为一个固定的高斯分布,得到一个训练样本分布组。
5、可选地,在本技术的一个实施例中,所述利用深度解码器和位姿解码器同时估计图像的位姿和深度值,并利用位姿和深度信息将所述图像投影到另一个预设视图下,采用光度损失和变分对比损失来联合监督模型训练,得到自监督单目深度估计结果,包括:基于所训练样本分布组,计算其中每一对正样本分布的js散度的相反数,作为正样本分布的相似程度;基于simclr的思想,将训练中的一个批次中其他样本作为负样本,将所述相似程度带入到simclr预设的对比损失中,以作为域自适应任务的优化目标。
6、可选地,在本技术的一个实施例中,所述利用深度解码器和位姿解码器同时估计图像的位姿和深度值,并利用位姿和深度信息将所述图像投影到另一个预设视图下,采用光度损失和变分对比损失来联合监督模型训练,得到自监督单目深度估计结果,还包括:利用基于深度卷积神经网络的位姿解码器估计所述训练样本特征组中辅助样本映射到主样本的相对位姿;基于深度值和所述相对位姿,将所述训练样本组中的辅助样本重投影到主图像中,得到重投影样本组,其中,所述重投影样本组中包含与原训练样本组中主样本对相对应的重投影样本对;基于所述重投影样本组与所述训练样本组中的主样本对,计算两者之间的光度损失,作为自监督单目深度估计任务的优化目标。
7、本技术第二方面实施例提供一种面向全天候场景的自监督单目深度估计装置,包括:输入模块,用于将基于预先构建的白天-夜间图像生成的多组正样本对输入至目标模型,利用共享的图像编码器提取所述白天图像和夜间图像的隐特征,以利用分布投影头将每个样本表示为预设高维度的离散高斯分布;处理模块,用于基于所述多组正样本对,利用对比学习显式地约束正负样本之间分布的距离,使得所述夜间图像的离散高斯分布逐步趋近于所述白天图像的离散高斯分布;以及估计模块,用于利用深度解码器和位姿解码器同时估计图像的位姿和深度值,并利用位姿和深度信息将所述图像投影到另一个预设视图下,采用光度损失和变分对比损失来联合监督模型训练,得到自监督单目深度估计结果。
8、可选地,在本技术的一个实施例中,所述输入模块,包括:生成单元,用于利用cyclegan生成与训练数据中每张白天图像相对应的夜间图像;构建单元,用于将所有的训练数据构建为白天-夜间样本对,得到所述多组正样本对,并将所述多组正样本对输入至所述目标模型。
9、可选地,在本技术的一个实施例中,所述处理模块,包括:第一获取单元,用于利用两层的第一全连接神经网络将每个样本的特征投影到均值空间中,获取每个维度高斯分布的均值;第二获取单元,用于利用两层的第二全连接神经网络将所述每个样本的特征投影到与所述均值空间维度相同的标准差空间中,获取每个维度高斯分布的标准差;第三获取单元,用于基于所述均值和所述标准差,利用每个样本所对应的均值向量和方差向量将所述每个样本表示为一个固定的高斯分布,得到一个训练样本分布组。
10、可选地,在本技术的一个实施例中,所述估计模块,包括:计算单元,用于基于所训练样本分布组,计算其中每一对正样本分布的js散度的相反数,作为正样本分布的相似程度;优化单元,用于基于simclr的思想,将训练中的一个批次中其他样本作为负样本,将所述相似程度带入到simclr预设的对比损失中,以作为域自适应任务的优化目标。
11、可选地,在本技术的一个实施例中,所述估计模块,还包括:估计单元,用于利用基于深度卷积神经网络的位姿解码器估计所述训练样本特征组中辅助样本映射到主样本的相对位姿;投影单元,用于基于深度值和所述相对位姿,将所述训练样本组中的辅助样本重投影到主图像中,得到重投影样本组,其中,所述重投影样本组中包含与原训练样本组中主样本对相对应的重投影样本对;计算单元,用于基于所述重投影样本组与所述训练样本组中的主样本对,计算两者之间的光度损失,作为自监督单目深度估计任务的优化目标。
12、本技术第三方面实施例提供一种电子设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序,以实现如上述实施例所述的面向全天候场景的自监督单目深度估计方法。
13、本技术第四方面实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储计算机程序,该程序被处理器执行时实现如上的面向全天候场景的自监督单目深度估计方法。
14、本技术实施例通过利用对比学习对白天-夜间图像样本对特征分布的显式约束和自监督深度估计目标的联合优化,实现了模型域自适应能力的提高以及对夜间图像深度特征的有效提取,提高了模型在全天候场景下的深度估计能力。由此,解决了相关技术中,使用场景过于单一,难以从夜间图像中有效地提取深度特征,难以利用一个共享编码器提取不同的数据域的一致性特征,模型域自适应能力低下等问题。
15、本技术附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!