人脸图像生成模型的训练方法、装置、设备及存储介质与流程
本技术涉及计算机应用,尤其涉及人脸图像生成模型的训练方法、装置、设备及存储介质。
背景技术:
1、在做人物口型驱动的时候,会将任务拆分成如下几个步骤:音频特征提取、表情系数预测、3d渲染、人脸生成。具体的,从输入的音频中提取出音频特征,使用音频特征来预测相应的表情系数,使用表情系数来生成对应的三维模型,最后,根据生成的三维模型,进行人脸的生成。
2、在对人物口型驱动进行训练时,每个任务都在拟合自己的任务,但是口型驱动任务最终的目标实际是对于输入音频,人物嘴巴能发出对应的口型,表情系数预测网络部分只能拟合表情系数,如果表情系数本身就是错误的,那么也会导致最终生成的人脸图像中的口型和音频不匹配。因此,如何提高人脸图像的鲁棒性是目前亟需解决的技术问题。
技术实现思路
1、本技术实施例提供了人脸图像生成模型的训练方法、装置、设备和存储介质,能够通过联合训练的方式训练得到训练后的人脸图像生成模型,从而确保通过训练后的人脸图像生成模型生成的人脸图像中的目标对象的口型与输入音频的对齐效果得到显著提升。
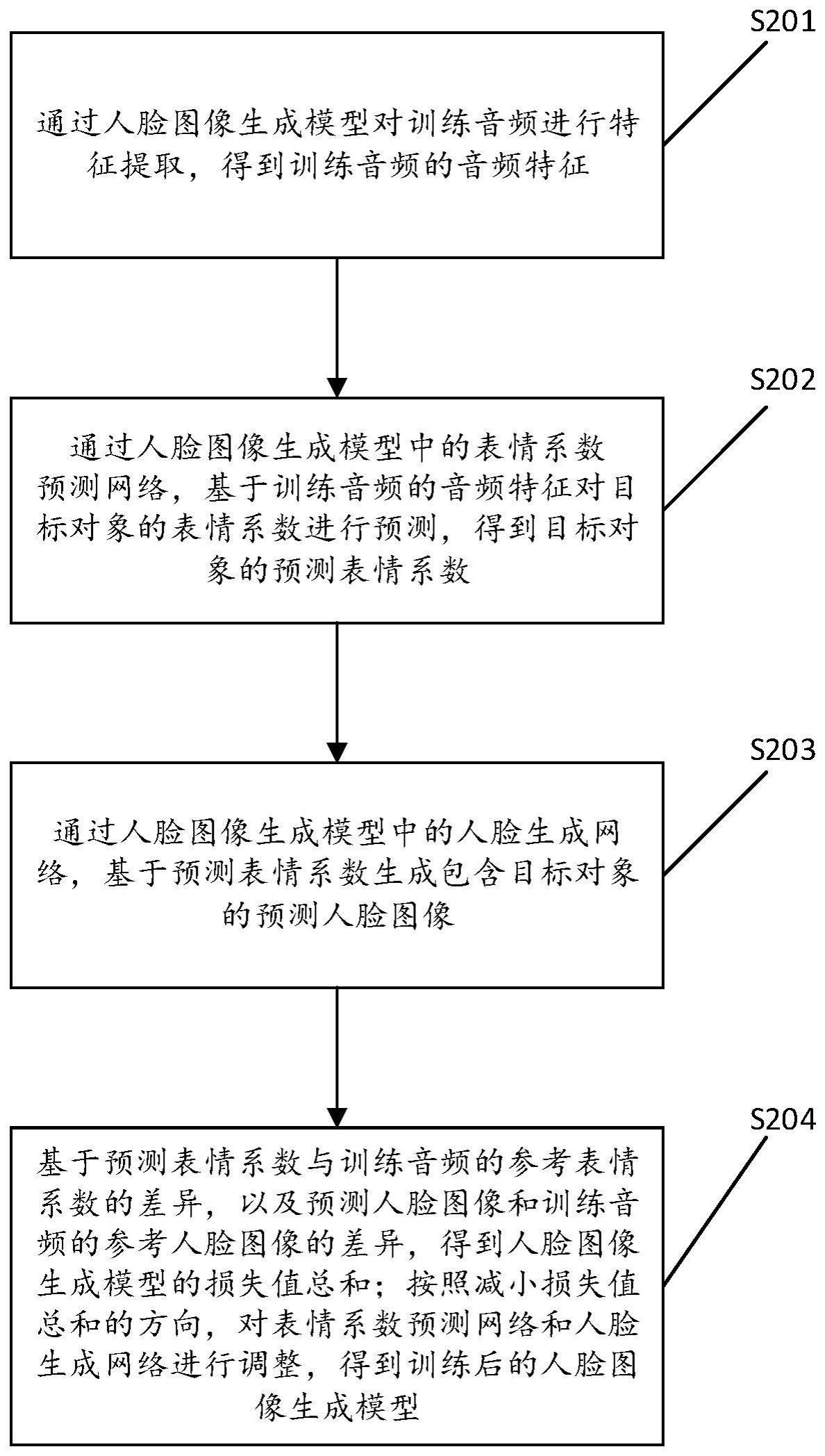
2、一方面,本技术实施例提供了一种人脸图像生成模型的训练方法,该方法包括:
3、通过人脸图像生成模型对训练音频进行特征提取,得到所述训练音频的音频特征;
4、通过所述人脸图像生成模型中的表情系数预测网络,基于所述训练音频的音频特征对目标对象的表情系数进行预测,得到所述目标对象的预测表情系数;
5、通过所述人脸图像生成模型中的人脸生成网络,基于所述预测表情系数生成包含所述目标对象的预测人脸图像;其中,所述预测人脸图像的表情与所述预测表情系数指示的表情匹配;
6、基于所述预测表情系数与所述训练音频的参考表情系数的差异,以及所述预测人脸图像和所述训练音频的参考人脸图像的差异,得到所述人脸图像生成模型的损失值总和;
7、按照减小所述损失值总和的方向,对所述表情系数预测网络和所述人脸生成网络进行调整,得到训练后的人脸图像生成模型。
8、在一个实施例中,所述按照减小所述损失值总和的方向,对所述表情系数预测网络和所述人脸生成网络进行调整,得到训练后的人脸图像生成模型,包括:
9、通过梯度回传算法,按照减小所述损失值总和的方向,对所述表情系数预测网络和所述人脸生成网络进行调整,得到训练后的人脸图像生成模型。
10、在一个实施例中,所述通过梯度回传算法,按照减小所述损失值总和的方向,对所述表情系数预测网络和所述人脸生成网络进行调整,得到训练后的人脸图像生成模型,包括:
11、基于所述预测人脸图像和所述训练音频的参考人脸图像的差异,对所述人脸生成网络进行调整,得到调整后的人脸生成网络;
12、基于所述预测表情系数与所述训练音频的参考表情系数的差异,以及所述预测人脸图像和所述训练音频的参考人脸图像的差异,对所述表情系数预测网络进行调整,得到调整后的预测网络;
13、基于所述调整后的人脸生成网络,以及所述调整后的表情系数预测网络,构建所述训练后的人脸图像生成模型;其中,所述训练后的人脸图像生成模型由所述调整后的人脸生成网络,以及所述调整后的表情系数预测网络组成。
14、在一个实施例中,所述人脸图像生成模型还包括音频特征提取网络,所述音频特征提取网络用于对所述训练音频进行特征提取,得到所述训练音频的音频特征;
15、所述基于所述预测表情系数与所述训练音频的参考表情系数的差异、所述预测人脸图像和所述训练音频的参考人脸图像的差异,以及所述训练音频的音频特征和所述训练音频的参考音频特征的差异,得到所述人脸图像生成模型的损失值总和;按照减小所述损失值总和的方向,对所述表情系数预测网络、所述人脸生成网络和所述音频特征提取网络进行调整,得到训练后的人脸图像生成模型,包括:
16、按照减小所述损失值总和的方向,对所述表情系数预测网络、所述人脸生成网络进行和所述音频特征提取网络调整,得到训练后的人脸图像生成模型。
17、在一个实施例中,所述按照减小所述损失值总和的方向对所述表情系数预测网络、所述人脸生成网络和所述音频特征提取网络进行调整,得到训练后的人脸图像生成模型,包括:
18、通过梯度回传算法,按照减小所述损失值总和的方向,对所述表情系数预测网络、所述人脸生成网络和音频特征提取网络进行调整,得到训练后的人脸图像生成模型。
19、在一个实施例中,所述通过梯度回传算法,按照减小所述损失值总和的方向,对所述表情系数预测网络、所述人脸生成网络和所述音频特征提取网络进行调整,得到训练后的人脸图像生成模型,包括:
20、基于所述预测人脸图像和所述训练音频的参考人脸图像的差异,对所述人脸生成网络进行调整,得到调整后的人脸生成网络;
21、基于所述预测表情系数与所述训练音频的参考表情系数的差异,以及所述预测人脸图像和所述训练音频的参考人脸图像的差异,对所述表情系数预测网络进行调整,得到调整后的表情系数预测网络;
22、基于所述预测表情系数与所述训练音频的参考表情系数的差异,所述预测人脸图像和所述训练音频的参考人脸图像的差异,以及所述训练音频的音频特征和所述训练音频的参考音频特征的差异,对所述音频特征提取网络进行调整,得到调整后的音频特征提取网络;
23、基于所述调整后的人脸生成网络,所述调整后的表情系数预测网络,以及所述调整后的音频特征提取网络,构建所述训练后的人脸图像生成模型;其中,所述训练后的人脸图像生成模型由所述调整后的人脸生成网络,所述调整后的表情系数预测网络,以及所述调整后的音频特征提取网络组成。
24、在一个实施例中,所述表情系数预测网络和所述人脸生成网络中的任一网络的调整方式,包括:
25、在所述任一网络中增加预设参数;其中,所述预设参数的维度与所述任一网络的预训练参数的维度相同,且所述预设参数的参数量小于所述预训练参数的参数量;
26、按照减小所述损失值总和的方向,对所述任一网络中的预设参数进行调整,以对所述任一网络进行调整。
27、在一个实施例中,所述预设参数包括第一预设参数和第二预设参数,其中所述第一预设参数的行数或者列数,与所述预训练参数的行数相同,且所述第二预设参数的行数或者列数,与所述预训练参数的列数相同,所述第一预设参数的参数量小于所述预训练参数的参数量,所述第二预设参数的参数量小于所述预训练参数的参数量;
28、所述按照减小所述损失值总和的方向,对所述任一网络中的第一预设参数以及第二预设参数进行调整,以对所述任一网络进行调整。
29、另一方面,本技术实施例提供了一种人脸图像生成模型的训练装置,该人脸图像生成模型的训练装置包括:
30、音频特征提取单元,用于通过人脸图像生成模型对训练音频进行特征提取,得到所述训练音频的音频特征;
31、表情系数预测单元,用于通过所述人脸图像生成模型中的表情系数预测网络,基于所述训练音频的音频特征对目标对象的表情系数进行预测,得到所述目标对象的预测表情系数;
32、人脸图像生成单元,用于通过所述人脸图像生成模型中的人脸生成网络,基于所述预测表情系数生成包含所述目标对象的预测人脸图像;其中,所述预测人脸图像的表情与所述预测表情系数指示的表情匹配;
33、所述人脸图像生成单元,还用于基于所述预测表情系数与所述训练音频的参考表情系数的差异,以及所述预测人脸图像和所述训练音频的参考人脸图像的差异,得到所述人脸图像生成模型的损失值总和。
34、所述人脸图像生成单元,还用于按照减小所述损失值总和的方向,对所述表情系数预测网络和所述人脸生成网络进行调整,得到训练后的人脸图像生成模型。
35、另一方面,本技术实施例提供一种计算机设备,包括处理器、存储装置和通信接口,处理器、存储装置和通信接口相互连接,其中,存储装置用于存储支持计算机设备执行上述方法的计算机程序,计算机程序包括程序指令,处理器被配置用于调用程序指令,执行如下步骤:
36、通过人脸图像生成模型对训练音频进行特征提取,得到所述训练音频的音频特征;
37、通过所述人脸图像生成模型中的表情系数预测网络,基于所述训练音频的音频特征对目标对象的表情系数进行预测,得到所述目标对象的预测表情系数;
38、通过所述人脸图像生成模型中的人脸生成网络,基于所述预测表情系数生成包含所述目标对象的预测人脸图像;其中,所述预测人脸图像的表情与所述预测表情系数指示的表情匹配;
39、基于所述预测表情系数与所述训练音频的参考表情系数的差异,以及所述预测人脸图像和所述训练音频的参考人脸图像的差异,得到所述人脸图像生成模型的损失值总和;
40、按照减小所述损失值总和的方向,对所述表情系数预测网络和所述人脸生成网络进行调整,得到训练后的人脸图像生成模型。
41、另一方面,本技术实施例提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序包括程序指令,程序指令当被处理器执行时使处理器执行上述人脸图像生成模型的训练方法。
42、本技术实施例中,通过人脸图像生成模型对训练音频进行特征提取,得到训练音频的音频特征。通过人脸图像生成模型中的表情系数预测网络,基于训练音频的音频特征对目标对象的表情系数进行预测,得到目标对象的预测表情系数。通过人脸图像生成模型中的人脸生成网络,基于预测表情系数生成包含目标对象的预测人脸图像。基于预测表情系数与训练音频的参考表情系数的差异,以及预测人脸图像和训练音频的参考人脸图像的差异,得到人脸图像生成模型的损失值总和;按照减小损失值总和的方向,对表情系数预测网络和人脸生成网络进行调整,得到训练后的人脸图像生成模型。由于联合训练时人脸图像生成模型中的表情系数预测网络和人脸生成网络都是朝着同一个目标进行训练,从而确保通过训练后的人脸图像生成模型生成的人脸图像中的目标对象的口型与输入音频的对齐效果得到显著提升。
- 还没有人留言评论。精彩留言会获得点赞!