一种基于局部优化的多视角多人人体姿态估计方法
本发明涉及一种基于局部优化的多视角多人人体姿态估计方法,属于人工智能。
背景技术:
1、三维人体姿态估计因在智能体育、零售分析、人机交互等现实世界中存在大量应用,所以一直成为计算机视觉领域的研究热点。然而在单目人体姿态中拥有一些极具挑战性的问题,因为在单一摄像机视角下,存在深度信息丢失和严重遮挡现象。
技术实现思路
1、目的:鉴于以上技术问题中的至少一项,本发明提供一种基于局部优化的多视角多人人体姿态估计方法,提出一个新的优化策略,以缓解现有环境影响、遮挡带来的精度丢失影响。
2、本发明采用的技术方案为:
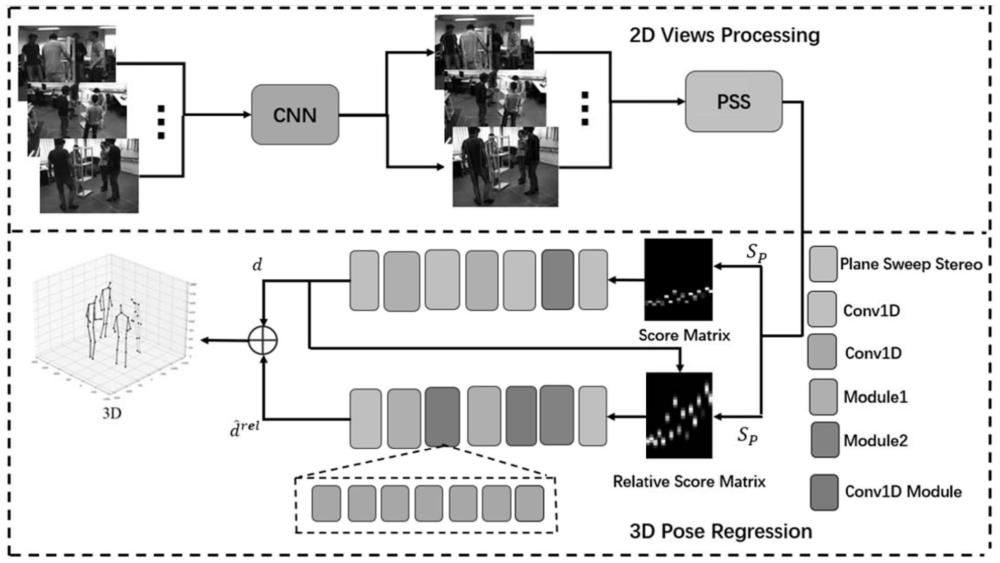
3、第一方面,本发明提供一种基于局部优化的多视角多人人体姿态估计方法,包括:
4、获取多视角的图片,其中所述多视角的图片为同一时刻多个视角的包含有目标人体的图片;
5、将所述多视角的图片分别输入到2d人体关节点检测网络模型,得到多视图的2d人体关节点;其中所述多视图的2d人体关节点包括一个主视图的2d人体关节点和参考视图的2d人体关节点;
6、将多视图的2d人体关节点投影至虚拟深度平面中,主视图的2d人体关节点与其余视图的2d人体关节点进行比对,利用视图一致性得到得分矩阵;
7、将得分矩阵展开为一维向量作为粗略深度回归网络的输入,得到输出的根关节点的粗略深度信息;
8、将所述根关节点的粗略深度信息与得分矩阵进行融合,作为精细深度回归网络的输入,得到输出的所有人体关节点的深度信息;
9、根据所有人体关节点的深度信息和所有视图的2d人体关节点,利用已知的相机参数进行坐标系转换计算,从像素坐标系下的坐标映射到3d空间坐标系下,得到3d人体关节点;
10、连接各3d人体关节点得到人体姿态估计结果。
11、本发明中,深度回归网络模型包括粗略深度回归网络和精细深度回归网络。
12、在一些实施例中,粗略深度回归网络的处理过程包括:
13、对输入的得分矩阵sp展开为一维特征信息d后,通过第一个一维卷积和局部优化模块,得到初步具有关节依赖的一维特征信息d1;
14、d1=w1(conv1(d))
15、式中conv1代表第一次卷积操作,w1代表整体一次局部优化操作;
16、将一维特征信息d1经历两次卷积和局部优化的操作后经过第4次的卷积操作得到新的具有关节依赖的一维特征向量d2;对一维特征向量d2进行归一化处理得到根关节点的粗略深度信息d;
17、d2=conv14(w23(conv23(d1)))
18、d=σ(d2)
19、式中w23代表第2次和第3次的局部优化操作,conv23代表第2次和第3次的卷积操作,conv14代表第4次的卷积操作,σ代表的是softmax函数。
20、在一些实施例中,精细深度回归网络的处理过程包括:
21、将输入的得分矩阵sp展开为一维特征信息d后,与具有关节依赖的一维特征向量d2相加得到一维特征向量d3;
22、将一维特征向量d3通过两个普通一维卷积模块、两个膨胀卷积块、三个局部优化模块后,进行归一化处理得到精细深度信息d1;其中膨胀卷积和普通一维卷积都是对特征进行卷积操作;
23、将精细深度信息d1与粗略深度信息d相加得到人体关节点的深度信息d2;
24、d3=d2+d
25、d1=σ(conv24((w123(conv123(d3))))
26、d2=d1+d
27、其中σ代表softmax函数,w123代表第1次、第2次、第3次的局部优化操作,conv123代表第1次、第2次、第3次的卷积操作,conv24代表第4次的卷积操作。
28、在一些实施例中,将多视图的2d人体关节点投影至虚拟深度平面中,主视图的2d人体关节点与其余视图的2d人体关节点进行比对,利用视图一致性得到得分矩阵,包括:
29、一个视图的2d人体关节点代表一个2d姿态p,将目标视图的候选2d姿态p反向投影到虚拟深度平面d中,投影后的2d姿态表示为q(d);
30、从参考视图中的候选2d姿态集合{p}中寻找最近的2d姿态r(d):
31、
32、其中,τ(·,·)为测量图像平面的两个关节之间的距离,根据这个距离计算出目标姿态p的一个视图的得分矩阵j表示关节的总数;
33、虚拟深度平面d处关节j的得分测量投影姿态q(d)与关节j处匹配的参考视图姿态r(d)的对准,公式如下:
34、
35、其中之间的最小距离导致sd·j分高,这表明深度在d附近的可能性更高,σ是控制曲线的超参数,sd·j表示虚拟深度平面d处关节j的得分;
36、将所有视图的得分矩阵s进行加权平均融合得到最终的得分矩阵sp,而p代表目标姿态,也就是所有关节的得分矩阵。
37、在一些实施例中,根据所有人体关节点的深度信息和所有视图的2d人体关节点,利用已知的相机参数进行坐标系转换计算,从像素坐标系下的坐标映射到3d空间坐标系下,得到3d人体关节点,包括:
38、根据所有视图的2d人体关节点,将像素坐标系下的坐标(u,v)转换到相机坐标下的坐标(x,y);
39、
40、将相机坐标系下的坐标(x,y)转换到图像物理坐标系下的坐标(xc,yc,zc);
41、
42、其中zc为人体关节点的深度信息,对应每个像素坐标深度;f代表相机的内参;
43、得到图像物理坐标系下的坐标后,利用图像物理坐标系和世界坐标系的转换关系,得到3d人体关节点世界坐标系下的坐标;
44、
45、其中(xw,yw,zw)为世界坐标系下的坐标,r、t代表旋转矩阵和偏移向量,为相机外参。
46、因此知道像素坐标、对应的深度信息和已知的相机内外参即可映射到世界坐标系下的坐标。
47、在一些实施例中,2d人体关节点检测网络模型采用2d姿态估计器,使用高分辨率深度网络模型进行估计,输入任一视角的2d图片,通过网络提取出对应的特征图,然后回归出对应的2d坐标,最终形成2d人体关节点,即2d姿态p。
48、在一些实施例中,所述局部优化模块中使用了两层感知机放大了关节通道的相关性,从而提取出深度的关节依赖信息,计算流程如下:
49、
50、其中f1是一维卷积层的输出特征信息,而m代表感知机提取通道信息的操作;conv2表示使用2个普通的一维卷积提取新的空间特征,用于聚焦空间信息,得到的空间关节依赖关系;然后通过引入的sa简单注意力模块的能力函数去估计神经元的重要性,然后用于提取更准的特征信息,计算流程如下:
51、
52、其中sa代表引入的简单注意力模块的操作,通过简单注意力模块的信息特取,得到新的特征信息f3,输入到下一个卷积层中进行卷积操作。
53、本技术采用多视角的图片作为输入,用常见的高分辨率深度学习网络模型作为2d姿态估计器,用于估计多个视图的2d骨架点。
54、其次采用多视图的一致性,对不用视角的2d姿态进行计算,得到对应的得分矩阵,把得分矩阵作为新的输入,输入到两种不同的深度回归网络中,用于估计每个关节的深度信息。
55、其中深度回归网络分为粗略深度回归网络和精细深度回归网络,用于提取更精准的深度信息,但是用于一维卷积层存在弊端,无法提取通道和空间等更深层次的特征信息,这样会导致很多因环境影响、遮挡等因素导致的估计误差无法弥补。
56、因此设计了一种新的网络结构去完成局部优化,利用了两层的感知机结构外加两层的一维卷积层去弥补这些缺陷,并直接引入简单注意力机制sa模块去加速、精准提取出特征信息,用于后续的深度回归网络回归深度信息。
57、最后利用已知的2d姿态、深度信息、相机参数去把关节点映射到3d空间中,形成3d姿态。
58、第二方面,本发明提供了一种基于局部优化的多视角多人人体姿态估计装置,包括处理器及存储介质;
59、所述存储介质用于存储指令;
60、所述处理器用于根据所述指令进行操作以执行根据第一方面所述的方法。
61、第三方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所述的方法。
62、第四方面,本发明提供了一种设备,包括,
63、存储器;
64、处理器;
65、以及
66、计算机程序;
67、其中,所述计算机程序存储在所述存储器中,并被配置为由所述处理器执行以实现上述第一方面所述的方法。
68、有益效果:本发明提供的基于局部优化的多视角多人人体姿态估计方法,具有以下优点:通过设计一个新的优化策略去优化神经网络来进行3d人体关节点估计,进而提升整体的准确性,更适合处理3d人体关节点估计中存在的遮挡问题、外部环境影响问题;通过深度神经网络回归模型,将人体骨架识别模型提取得到的2d关节点,通过视角一致性得到对应的得分矩阵;将得分矩阵展开成一维的特征信息输入到深度回归网络中,得到所有关节点相对应的深度信息;利用已知的相机参数、深度信息、2d骨架点直接映射到3d空间中,得到相对应的3d骨架点,并按照关节点之间的对应关系,绘制出相应的骨架。
- 还没有人留言评论。精彩留言会获得点赞!