基于图网络时序一致性的伪造视频检测方法和装置
本发明涉及一种基于图网络时序一致性的深度伪造视频鉴别方法和装置,属于深度学习、计算机视觉和图神经网络领域。
背景技术:
1、近年来,随着深度学习和计算机视觉的飞速发展,尤其是神经网络模型中生成式对抗网络(gan)和扩散模型(diffusion model)的发展,使得生成式人工智能(ai generatecontent)得到了井喷式的发展。
2、具体来说,深度伪造技术主要是对人脸进行编辑或生成,主要分为:人脸重现、人脸替换、人脸编辑和人脸生成。人脸重现使用源人脸驱动目标人脸,使得目标人脸做的行为和源人脸一致。人脸替换指的是使用源人脸替换目标人脸,使得目标人脸变成了源人脸。人脸编辑是指通过修改目标人脸的面部属性,例如,修改目标人脸的面部表情、面部器官大小、肤色等。人脸合成是在没有目标人脸作为基础的条件下,创建一张现实中完全不存在的人脸。
3、随着深度伪造技术的迅猛发展,制作者通过电脑或手机软件轻制作大量的深度伪造视频,并发布到互联网上进行传播。
4、现有针对深度伪造视频鉴别的研究较少,目前主要是将深度伪造视频进行下采样为图片进行研究,主要的方法是使用计算机视觉领域的深度学习模型进行特征提取,最终使用二分类器进行检测。这些方法忽略了视频帧之间的时序信息,不能发掘存在于视频帧之间的时序不一致信息,降低了对深度伪造视频的识别精确度。
技术实现思路
1、本发明的要克服现有技术的上述缺点,提供一种基于图网络时序一致性的深度伪造视频检测方法。本发明结合了人脸关键点的特征和时序信息特征,计算帧与帧之间的相似性,对视频帧进行构图,实现对伪造视频进行判别,大大提高检测算法的准确率。
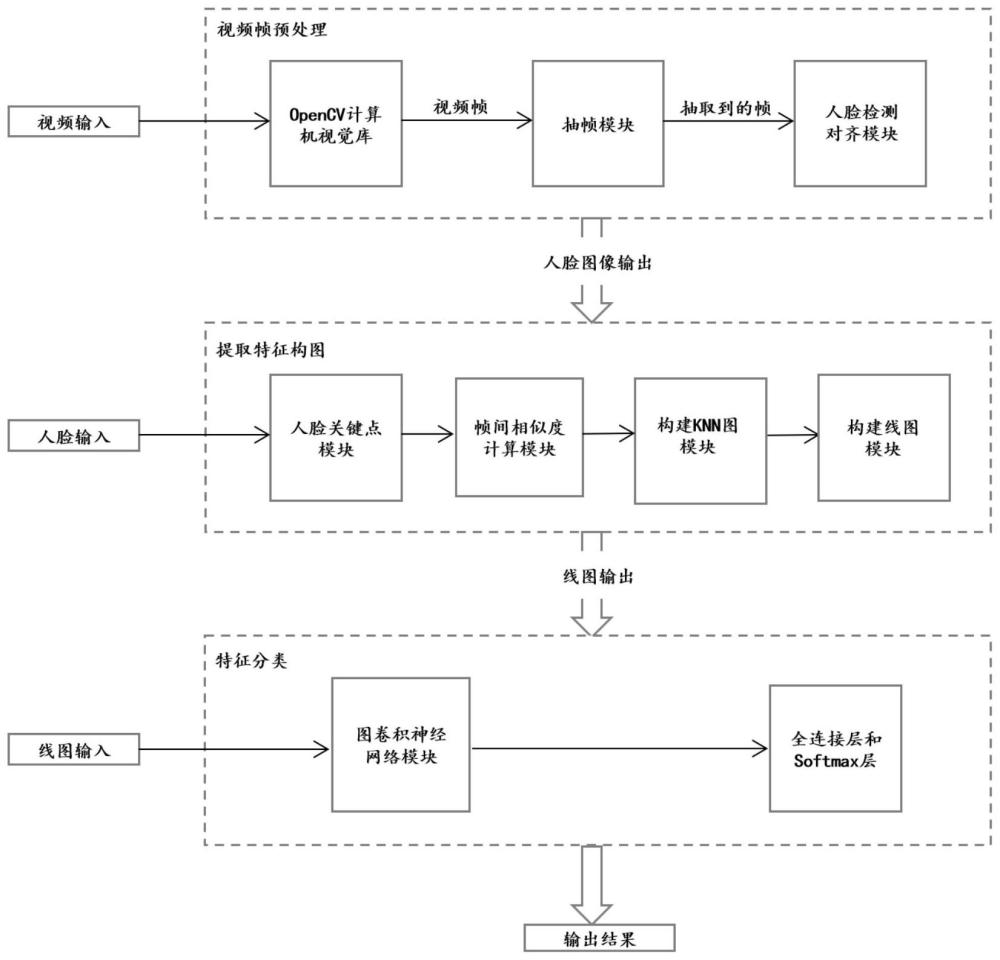
2、本发明采用的技术方案:本发明的第一个方面提供基于图网络时序一致性的伪造视频检测方法,包括如下步骤:
3、s1:将输入的深度伪造视频进行逐帧分解并抽取帧,得到抽取后的视频帧。
4、s2:对步骤s1得到的视频帧序列,依次采用retinaface模型进行人脸检测,对存在人脸的视频帧进行仿射变换与标准人脸坐标点进行对齐和缩放,最后将经过对齐和缩放的人脸视频帧进行裁剪,并得到rgb人脸视频帧图像。
5、s3:对步骤s2得到的帧图像使用人脸关键点检测网络提取图片中的眉毛、眼睛、鼻子、嘴巴、脸部轮廓区域的关键点特征,对每一帧提取关键点。
6、s4:根据步骤s3得到的视频帧的关键点特征,计算每帧视频之间的相似度。
7、s5:根据视频帧之间的相似度,使用k近邻图(k-nearest neighborhood graph)来构建knn图。
8、s6:将步骤s5得到的knn图转化为线图(line graph)。
9、s7:使用图卷积神经网络(graph convolutional network),对线图进行全局特征提取,获得图的表示,并且使用一个全局池化层,获得线图的全局表征。
10、s8:将步骤s7得到的全局表征输入到全连接层和softmax层,将其映射为伪造视频的伪造算法分类,实现对伪造算法的检测。
11、所述步骤s1中,将输入的深度伪造视频进行逐帧分解并抽取帧,得到抽取后的视频帧。具体如下:将输入的深度伪造视频进行逐帧分解并抽取帧,得到抽取后的视频帧,具体如下:将输入深度伪造视频分解为单帧图像,按照视频总帧数,均匀抽取100帧图像。对于不足100帧的视频,抽取视频的全部帧。
12、所述步骤s3中,对步骤s2得到的帧图像使用人脸关键点检测网络提取图片中的眉毛、眼睛、鼻子、嘴巴、脸部轮廓区域的关键点特征,对每一帧提取关键点。具体如下:
13、提取图片中的眼神漂移、面部表情、嘴唇同步等特征,它将人脸关键点分为内部关键点和轮廓关键点,内部关键点包含眉毛、眼睛、鼻子、嘴巴共计51个关键点,轮廓关键点包含17个关键点。其中,51个关键点如下:
14、单边眉毛有5个关键点,从左边界到右边界均匀采样,共10个关键点;眼睛分为6个关键点,分别是左右边界,上下眼睑均匀采样,共12个关键点;嘴唇分为20个关键点,其中左右嘴角各2个,上下嘴唇的外边界各自均匀采样5个点,上下嘴唇的内边界,各自均匀采样3个点,共20个关键点;鼻子上鼻梁采样4个关键点,鼻尖部分则均匀采集5个关键点,共9个关键点。另外,脸部轮廓均匀采样了17个关键点。一共采样面部68个关键点。
15、所述步骤s4中,根据步骤s3得到的视频帧的关键点特征,计算每帧视频之间的相似度,具体的计算公式如下:
16、
17、其中,表示第i帧和第j帧图片之间关键点向量的相似度。k表示68个关键点的序号。其中表示第i帧图片的关键点向量中的第k个关键点的值。计算各个关键点之间的欧式距离,累加得到两帧图片的相似度。
18、所述步骤s5中,根据相似度组建k邻近(knn)图,具体如下:首先将每帧图像转化为对应的节点,节点之间通过节点间的相似度进行连接。对每个节点,取k=6个最近邻的节点和其相连,其中每个节点之间边的权重为两个节点之间的关键点相似度。
19、所述步骤s6中,将步骤s5得到的knn图转化为线图(line graph)。具体过程如下:所述步骤s6中,将knn图转化为线图的步骤如下。首先,将knn图中的边(vi,vj)被转化为线图中的节点且如果knn图中的两条边有公共节点,则对应线图中的两个节点相互连接。将视频的knn图转化为线图后,线图上的节点的特征为对应knn图中边携带的多特征相似度sij。
20、所述步骤s7中,使用图卷积神经网络(graph convolutional network),对线图进行全局特征提取,获得图的表示,并且使用一个全局池化层,获得线图的全局表征。具体过程如下:
21、构造一个带池化的图卷积神经网络(graph convolutional network,gcn),对视频的线图进行全局特征提取,获得图表示。具体而言,首先定义line图上的节点特征矩阵x和邻接矩阵a。然后,应用多层gcn进行特征学习,每一层的输出可以表示为:
22、h(l+1)=σ(d-1/2ad-1/2h(l)w(l)) (2)
23、其中h(l)表示第l层的节点特征,w(l)表示第l层的权重矩阵,σ(·)表示激活函数,d是a的度矩阵。在获得了线图上所有节点的表征后,进一步利用一个池化层获取线图的全局表征:
24、z=poolling(h(l+1)) (3)
25、本发明的第二个方面涉及基于图网络时序一致性的伪造视频检测装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现本发明的基于图网络时序一致性的伪造视频检测方法
26、本发明的第三个方面涉及一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现本发明的基于图网络时序一致性的伪造视频检测方法。
27、本发明与现有技术相比的优点及功效在于:
28、(1)本发明在提取原始视频图像特征时,利用了人脸关键点提取技术,对于人脸轮廓、眉毛、眼睛、鼻子、嘴巴等68个关键点进行定位,并利用帧间关键点坐标的偏移,计算帧间的不一致性,发现帧间运动的时序不一致性,提高模型对于时序不一致性的捕捉能力。
29、(2)本发明与采用手工特征的方法相比,本发明利用图卷积神经网络提升了特征提取的灵活性。使用视频帧之间的时序信息。利用帧间相似度构建时序图,运用图卷积神经网络,极大地提高了检测精确度。
- 还没有人留言评论。精彩留言会获得点赞!