一种基于显式和隐式混合编码的动态场景重建方法
本发明涉及动态场景重建,更具体的说是涉及一种基于显式和隐式混合编码的动态场景重建方法。
背景技术:
1、使用一组2d图像重建和渲染3d场景的问题一直是计算机视觉和图形学领域的一个挑战。这项任务在虚拟现实、互动游戏和电影制作等各种应用中具有重要意义。最近,神经辐射场(nerf)通过使用可微分体绘制技术,使静态场景重建任务的性能取得了显著的进步。nerf仅需要将3d位置(x,y,z)和2d观察方向(θ,φ)作为输入,采用单个多层感知器(mlp)来拟合静态场景,即可得到3d点的颜色和密度,使其能够从多个2d图像准确地重建3d结构,并从以前未见过的视点生成逼真的图像。然而,由于现实世界是动态的,并且在复杂场景中经常涉及运动,因此将nerf重建静态场景的功能扩展到动态场景是亟待解决的问题。但是,由于nerf完全依赖于mlp这种隐式表示,为了获取采样点的颜色和密度,在每轮迭代中采样点都要经过数百万次的查询,使得动态场景的重建方法更加复杂。例如,d-nerf利用形变网络和规范网络来建模和拟合动态场景,但需要注意的是,这个过程要20多个小时才能收敛。与时间处理相关的高计算成本对这些技术在现实生活场景中的广泛应用提出了挑战。
2、最近的几种静态场景重建方法通过使用显式和隐式混合表示的方法,证明了比nerf这种纯隐式mlp场景表达具有更快的速度,仅需要十几分钟就可使模型收敛,这种速度的提高是利用体素网格的三线性插值来填充体素内的3d空间来实现的。但是,这种方法大多数是为静态场景重建而设计的,现有的方法不能直接应用于动态场景重建。主要原因是直接将静态场景的3d空间(x,y,z)表示扩展到具有时间维度的4d空间(x,y,z,t)会带来巨大的存储成本,该成本随着时间帧的数量呈线性增加,造成单一场景训练参数需要几十gb来存储,这是不切实际的。为了改善这个问题,一些动态nerf方法利用形变网络来学习点的映射关系,并将形变后的采样点输入到规范空间中。变形网络将三维点从观察空间(t≠0)映射到规范空间(t=0),有效地将动态场景重建问题转化为熟悉的静态场景。这种方法节省了大量存储空间,但是这些方法过度依赖于准确的位移估计模块,并且位移的累积误差估计会对规范网络的学习产生负面影响。另一方面,现有的体素表达通常采用单一分辨率体素网格来重建场景,然而,高分辨率体素网格不足以模拟大幅度运动,而低分辨率体素网格则无法捕获小小幅度运动中的细节。最终导致无法兼顾不同程度的运动,使得渲染结果变低。
技术实现思路
1、有鉴于此,本发明提供了一种基于显式和隐式混合编码的动态场景重建方法,以解决背景技术中的问题。
2、为了实现上述目的,本发明提供如下技术方案:
3、一种基于显式和隐式混合编码的动态场景重建方法,具体步骤包括如下:
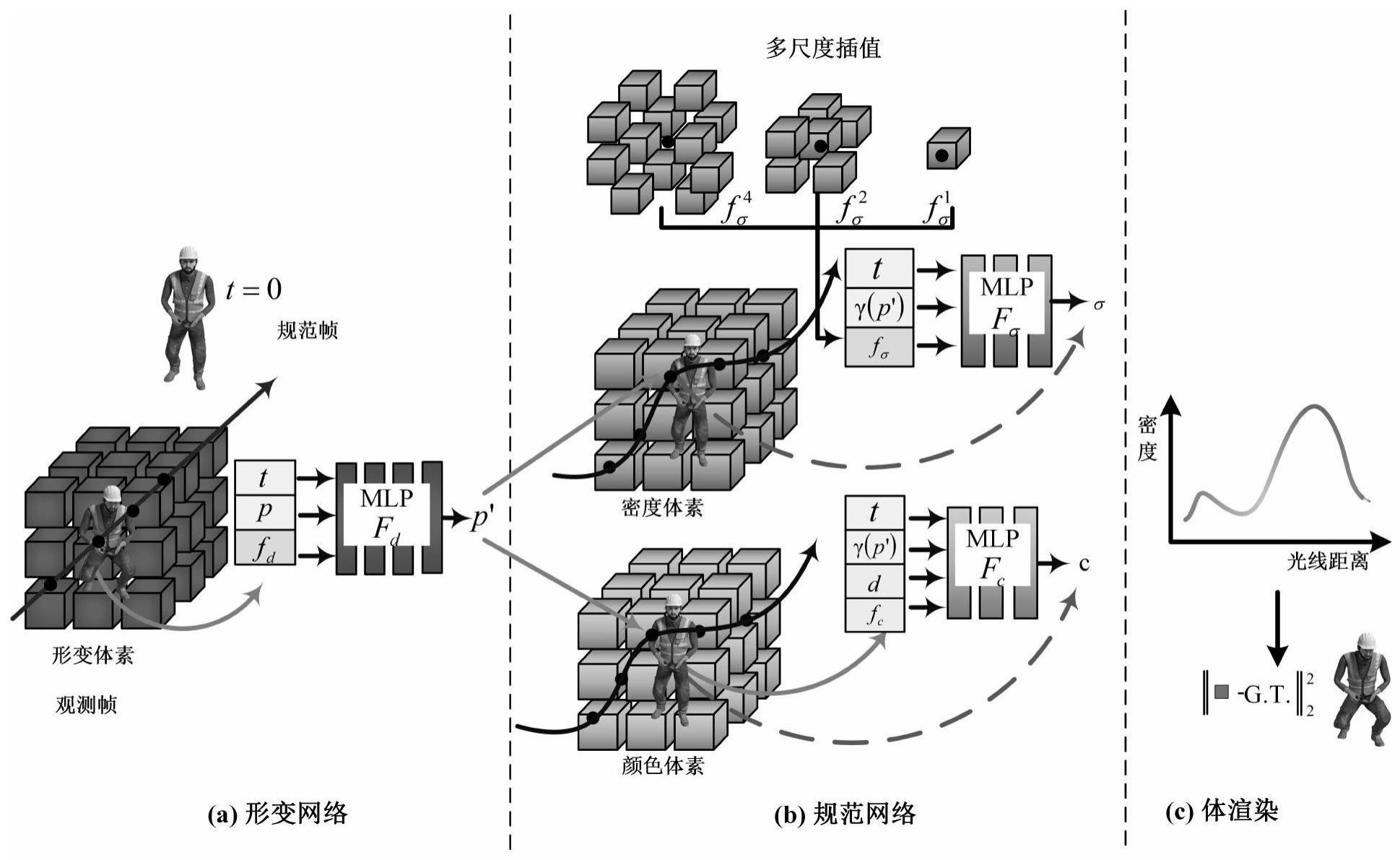
4、构建动态场景重建模型,包括依次连接的形变网络、规范网络和体渲染场;形变网络利用显式体素网格来存储3d动态特征,同时采用轻量级mlp来解码所述3d动态特征,输出位移估计;所述规范网络修正所述形变网络中位移估计的误差,将时间信息编码融入到密度和颜色的估计中;所述体渲染场利用规范网络预测的颜色和密度来计算像素点的颜色值;
5、构建批处理数据,并将批处理数据送入构建好的动态场景重建模型中进行训练,通过渲染得到的图像与真实图像的像素值做损失,利用损失函数值来优化网络参数直到收敛,得到最优动态场景重建模型;
6、输入待测数据到所述最优动态场景重建模型,获得渲染后的图像。
7、优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,所述形变网络包括依次设置形变体素网格和形变多层感知器;给定体素网格分辨率每个体素顶点存储的特征向量长度为nd,形变多层感知器fd包括输入层、隐藏层和输出层,用于输出估计的位移量。
8、优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,所述规范网络包括密度模块和颜色模块;
9、在所述密度模块中依次设置密度体素网格gσ,密度多层感知器fσ,给定体素网格分辨率每个体素顶点存储的特征向量长度为nσ,密度多层感知器fσ包括输入层、隐藏层和输出层,用以输出估计的密度σ;
10、在所述颜色模块中依次设置颜色体素网格gc,颜色多层感知器fc,给定体素网格分辨率每个体素顶点存储的特征向量长度为nc,颜色多层感知器fc包括输入层、隐藏层和输出层,用以输出估计的颜色rgb。
11、优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,所述体渲染场,计算每条光线的颜色,设p(h)=o+hd是从相机光心的中心o发射到投影像素的相机射线上的一点,其中射线方向d即投影像素点到光心的单位向量,经过密度模块和颜色模块后得到一条光线上n个采样点的密度σ和颜色c,则该光线的估计颜色为其中,hn和hf表示场景体积的边界,p′(h,t)是通过变形网络从观察空间变换到标规范空间的采样点,是hn到当前采样点h的累计透射率。
12、优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,构建批处理数据具体步骤如下:每轮从训练集图像中随机选取n_rays个像素点,以相机光心为原点o,沿着投影像素方向d发出一条射线,获得批处理所用的n_rays条光线,同时记录每条光线所属相片的时间n_rays_t,以光线的近端near和远端far为区间,在光线上采样n_sample个采样点p(x,y,z),至此获得批处理数据为(n_rays,n_sample,p)和(n_rays,n_sample,n_rays_t)。
13、优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,将批处理数据送入构建好的动态场景重建模型中进行训练具体步骤如下:
14、查询采样点p位于形变体素网格中的位置,根据所处体素的顶点进行三线性插值,得到p点的nd维的形变特征向量fd;利用编码公式对特征向量fd、采样点位置p和所属时间n_rays_t进行编码,得到t时刻的采样点p在规范空间t=0时刻的采样点位置p′=p+δp;
15、查询采样点p'位于颜色体素网格中的位置,变形网络通过迭代过程学习t时刻点的位移,逐渐向正确的结果收敛,在规范网络的密度和颜色估计网络中加入了对时间信息编码γ(n_ray_t),获得采样点的颜色c;
16、查询采样点p'位于密度体素网格中的位置,采用多尺度三线性插值来获得密度特征向量fσ,将γ(p′)、γ(n_ray_t)和fσ拼接到一起送入密度多层感知器fσ中,获得采样点的密度σ;
17、获得一条光线上n_sample个采样点的颜色ci和密度σi,有n_rays条,其中0≤i≤n_sample;在体渲染场利用体渲染公式,获得光线对应像素点的颜色将与真实值c来做损失用以优化网络模型。
18、优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,还包括:分段式训练方法;过滤掉对目标计算目标像素颜色没有贡献的采样点,具体步骤如下:粗阶段训练和细阶段训练;
19、粗阶段训练,采用第一网络参数,并且在估计颜色和密度时,由体素网格直接插值得到,快速恢复场景的粗略几何形状;
20、粗阶段结束后通过查询当前所有网格顶点的密度信息,在掩码推理时,光线权重u(h,t)σ(p′(h,t))小于αc=10-3的光线作为空空间被掩码掉,在非空点中,寻找包含目标对象的最小边界框;在细阶段训练利用粗阶段网格来进行初始化,采用第二网络参数,在预测颜色之前,应用额外的滤值,去除采样点累计透过率u(h,t)小于阈值αf=10-4点。
21、优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,还包括测试步骤:
22、给定测试图像序列,相机位姿为,帧的时间序列构成测试集,图像分辨率为h×w,其中n为正整数,表示测试集中一个场景所包含的rgb图像数量;
23、将测试集图像序列、相机位姿和时间序列送入训练好的模型中,依次从每个相机位姿逐像素点的发出光线进行采样,采样点依次获得对应颜色和密度,最终利用体渲染模块获得渲染后的图像,图像序列作为真实值来评估测试结果。
24、经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于显式和隐式混合编码的动态场景重建方法,并通过多尺度插值和时间感知来高质量重建动态场景。动态场景重建模型为三个模块,分别是形变网络、规范网络和体渲染场,用以避免学习高维映射的复杂关系并降低存储成本。在形变网络中,采用可优化的显式体素网格来存储3d动态特征,同时采用轻量级mlp来解码这些形变特征,通过此设置大大的减少了mlp这种全局性的重建负担,将重建任务分配给每一个小体素,从而显著的加速了训练过程以及收敛速度。在规范网络中,为了纠正形变网络中位移估计的误差,将时间信息编码融入到密度和颜色的估计中,增强规范网络的鲁棒性和对运动的感知力。此外,在密度场中放弃了简单的三线性插值,而是设计了多尺度插值,从多种距离的体素中获取特征信息,这种方法可以在捕获较大幅度的运动时,很好的兼顾小幅度运动中的复杂细节。体渲染场则利用规范网络预测的颜色和密度来计算像素点的颜色值,用于与真值做损失来优化网络。
- 还没有人留言评论。精彩留言会获得点赞!