一种基于扩散模型的图像生成方法与装置与流程
本发明涉及图像生成,尤其涉及一种基于扩散模型的图像生成方法与装置。
背景技术:
1、图像生成任务在计算机视觉领域及多种现实场景下都有重要应用,如图文交互、数据增扩、和艺术创作等等,近年来成为了备受关注的研究领域之一。基于扩散模型的图像生成方法起源于热力学中的扩散过程,如今在图像生成领域表现出突出的优势,其生成结果在可控性、创新性和真实性上都超过了以往基于gan或vae的方法。然而,扩散模型的计算效率低下是使用过程中不可避免的问题,尤其对于无分类器引导的扩散方案,其计算效率的低下不仅来源于逐步的基础迭代过程,还来源于需要计算有无引导两种情况下的噪声估计。无分类器引导的扩散模型能够大幅提升生成样本的质量,却以高额的计算成本作为代价。当前已有方案将知识蒸馏引入扩散模型,通过学生模型降低必要迭代次数,但算法效果不甚理想,生成图像的质量明显受损,细节特征无法被生成。因此,如何让扩散模型在提高生成效率和生成质量之间达到更好的平衡,是目前需要解决的问题。
技术实现思路
1、本发明的目的就在于为了解决上述问题而提供一种基于扩散模型的图像生成方法与装置,本发明通过输入文本描述,引导扩散模型快速迭代,最终得到高质量的生成图像。
2、本发明通过以下技术方案来实现上述目的:
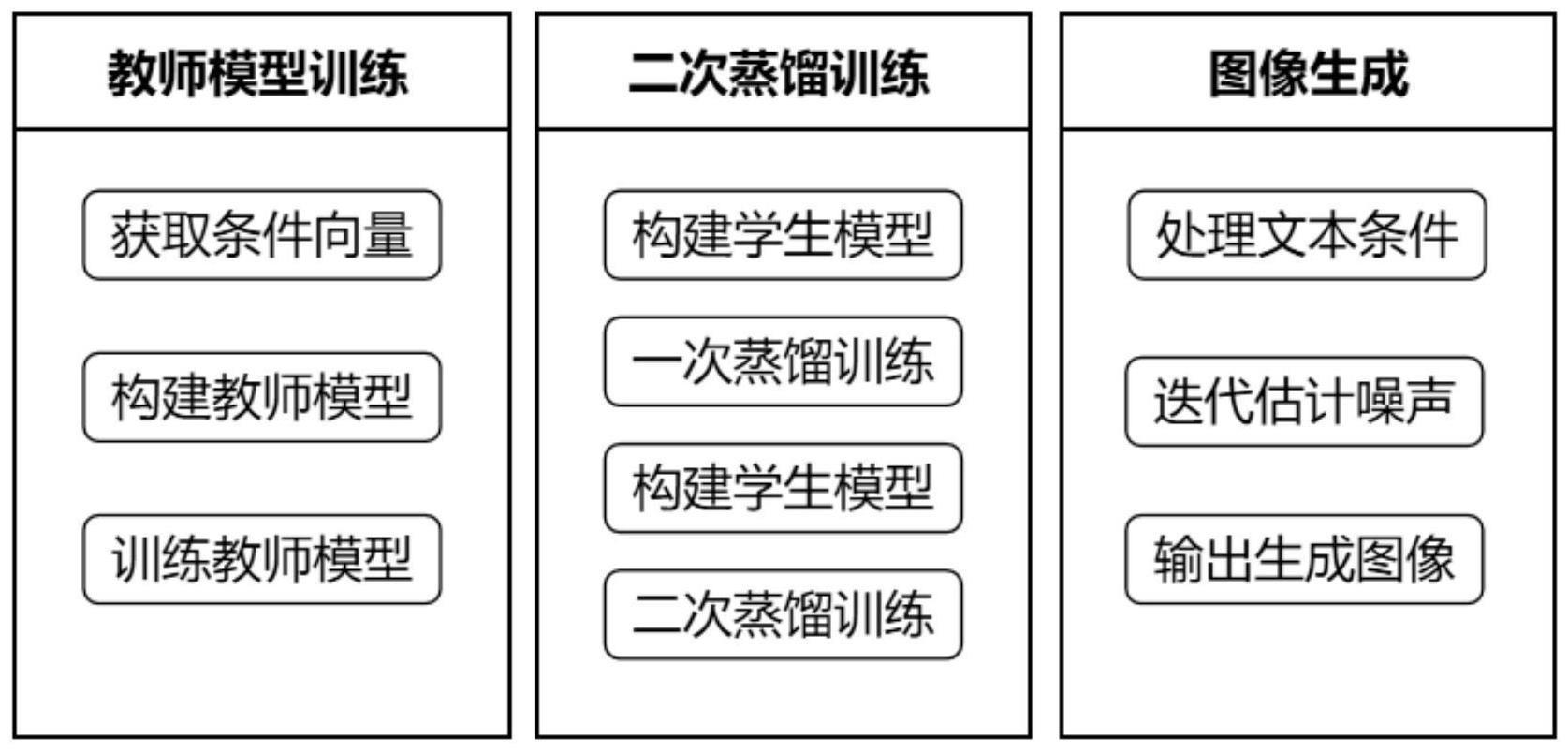
3、一种基于扩散模型的图像生成方法,包括以下步骤:
4、步骤1,结合文本编码构建并训练教师模型:
5、构建自注意力编码模块获取条件向量;
6、结合自注意力编码模块,构建基于transformer的教师扩散模型;
7、采用隐式条件引导方式训练教师模型;
8、步骤2,对教师模型进行二次蒸馏:
9、参考教师模型,构建参数量更小的学生模型;
10、一次蒸馏训练,将训练完成的学生模型作为新的教师模型;
11、构建新的学生模型,进行二次蒸馏训练;
12、步骤3,利用最终模型实现图像生成:
13、输入文本条件,得到生成图像。
14、进一步方案为,所述步骤1中,构建自注意力编码模块获取条件向量包括:输入文本描述,即关于目标生成图像的信息,经过运算,输出一维条件向量,作为迭代过程中的引导标签。该条件生成模块基于注意力机制构建,至少包含一个编码器和一个自注意力模块。所述基于自注意力的条件生成模块,采用文本编码和注意力计算单元,学习文本条件中的语义信息,并在输出向量中集成。
15、构建基于transformer的教师扩散模型包括:教师模型用于融合条件变量,以迭代的方式实现噪声估计和图像生成。其主干分为四个层级,每层至少拥有两个注意力单元。注意力单元融合了多头自注意力机制和可变窗口机制,加强局部之间的信息交互,适应于大尺寸输入的特征学习和概率估计。
16、为了保证生成图像的语义准确,将第一步中的条件变量输入到模型的两个不同位置。(a)作为token单元附加在下采样层的输出,即图像token之后;(b)前两个层级的多头自注意力模块中,条件向量作为辅助信息,与自注意力模块中的权重序列拼接。
17、采用隐式条件引导方式训练教师模型包括:输入带噪声的图像,教师模型t用于估计应当去除的噪声,以迭代的方式在输入图像中减去。训练步骤包括参数初始化、预训练和目标域数据微调三个阶段,模型训练方式至少包括扩散模型常用的训练方式,如显式条件引导和隐式条件引导等。
18、显式条件引导训练时,模型预测的噪声分布如下式:
19、
20、隐式条件引导训练时,模型预测的噪声分布如下式:
21、
22、其中,c为有条件标签,表示无条件,s为scale系数,用于调节条件的影响权重。
23、模型的损失函数为:
24、loss=‖∈-∈θ(xt,t)‖2
25、其中,∈为真实采样噪声,∈θ(xt,t)为模型估测噪声,t表示迭代步数。
26、进一步方案为,所述步骤2中,构建学生模型包括:学生模型用于继承教师模型的学习能力,以更少的计算消耗来实现与教师模型相近的输出结果。构建一个与教师模型结构相同的模型s1,其参数量可根据任务需求和应用场景有所减少,具体表现在模型第三个层级的block个数减少。
27、一次蒸馏训练包括:利用教师模型的参数对学生模型进行初始化,将教师模型的学习经验传递给学生模型。学生模型的迭代步长应当等于教师模型的一半,即学生模型一次迭代后的损失函数计算,应当来源于教师模型两次迭代后的估计结果。
28、教师模型经过t1和t2两个时刻的迭代,得到的输出计作此时学生模型进行一次迭代,其输出计为则学生模型的损失函数需要添加两者的均方误差:
29、
30、二次蒸馏训练包括:重复第一次蒸馏的过程,再次将迭代步长缩短,同时保证教师模型的噪声估计不受影响。将训练完成的学生模型s1作为新的教师模型,再次构建一个学生模型s2,s2的参数继承自s1,采取和一次蒸馏相同的训练方式,将迭代次数减少一半。
31、将训练好的第二个学生模型s2作为最终模型,其参数规模可以大幅减少,迭代次数相较于教师模型减少至四分之一。
32、二次蒸馏的训练方式将扩散模型的迭代次数成倍减少,且基于条件向量的辅助支持使生成图像的细节得到保持。
33、该步骤至少包含两个教师模型,教师-学生的知识蒸馏过程中,保留教师模型学习得到的特征细节,减少因多次迭代所耗费的计算资源和计算时间。
34、进一步方案为,所述步骤3中,利用训练好的模型进行图像生成;输入文本引导,模型通过迭代噪声,逐步恢复图像;有文本条件辅助时,文本信息经过注意力模块加入到迭代过程中;无文本条件辅助时,将条件变量设置为随机变量。
35、本发明另一方面还提供了一种基于扩散模型的图像生成装置,包括:
36、模型构建模块,结合自注意力机制,构建文本条件的信息提取模块和噪声估计模块,适用于文本和图像两种模态的特征提取和生成图像的细节维持,其包括:文本编码模块、自注意力提取模块、transformer噪声分布估计和扩散迭代模块;
37、二次蒸馏模块,至少构建两个教师模型,利用教师-学生的蒸馏模式将迭代次数减半,加快扩散模型运行速度,其包括:构建基于多头自注意力的模型框架模块、获取及融合多模态的条件变量模块、一次蒸馏和二次蒸馏模块;
38、图像生成模块,利用最后一次蒸馏得到的学生模型,根据文本条件进行生成引导、噪声估计和图像的迭代生成;
39、在图像生成模块中,给定条件向量情况下的生成流程如下:
40、将文本条件以语句或字词的形式输入信息提取模块,得到编码后的条件向量;
41、利用训练好的第二个学生模型,结合条件向量进行扩散迭代;
42、将迭代过程中的噪声从真实噪声中去除,经过一定次数的计算后,得到生成图像。
43、文本编码模块用于将输入的文本信息处理为特征向量,辅助扩散模型的迭代过程;
44、自注意力提取模块基于自注意力单元构建文本编码器,用于处理上下文关联信息;
45、扩散迭代模块的模型训练采用扩散模型的方式,每一次迭代得到一个噪声估计;
46、构建基于多头自注意力的模型框架模块的模型主干采用基于transformer的模型,根据注意力机制进行噪声估计;
47、获取及融合多模态的条件变量模块将条件变量加入模型的特定位置,用于引导图像生成;
48、一次蒸馏和二次蒸馏模块进行至少连续两次蒸馏操作,将迭代次数成倍减少。
49、本发明的有益效果在于:
50、本发明以自注意力模块为网络基础结构,构建了包含细节保持的条件向量生成模块、基于注意力的扩散模型和二次蒸馏迭代框架,加快了扩散模型的运行速度,同时将对生成图像质量的影响减到最低,在降低模型运行损耗和提升图像质量之间达到了更好的平衡,将条件注意力机制引入扩散模型,利用自注意力机制的多模态适应性,对条件向量进行编码、并同时增强对图像细节的捕捉;可以作为图像生成领域通用的算法框架。
51、本发明将二次蒸馏方式引入扩散过程,教师-学生的蒸馏至少将迭代过程减少四倍,大幅提升了生成效率。现有的基于去噪扩散概率模型的图像生成方案,大多采用无分类器引导的方式,该方式能够有效提升生成图像的质量,却加剧了采样效率低下的问题。本发明将知识蒸馏和条件注意力机制与扩散模型结合,利用学生模型缓解迭代速度慢的问题,利用文本条件辅助来解决图像细节保护的问题,达到加快模型计算、优化生成质量的效果。
- 还没有人留言评论。精彩留言会获得点赞!