基于kafka流的数据处理方法、电子设备及存储介质与流程
本发明涉及数据处理领域,特别是涉及一种基于kafka流的数据处理方法、电子设备及存储介质。
背景技术:
1、随着时代的进步与经济飞速发展,互联网与云计算等各种新兴技术也得到了迅猛进步,同时促使数据也出现了十分惊人的增长速度,数量也在不断增加。大量数据也会导致存储成本极速攀升,同时也为用户提供更有价值的研究数据。特定用户场景中对数据传输时效性、用户相关数据、以及数据质量比较关注,第一时间对特定最新最近数据分析,以及如何从海量数据中获取到用户想要高质量的数据,且安全、时效性高传输、支持灵活暂停/开启、修改数据指标等高质量数据等成为了需要解决的问题。
技术实现思路
1、针对上述技术问题,本发明采用的技术方案为:
2、本发明实施例提供一种基于kafka流的数据处理方法,所述方法包括如下步骤:
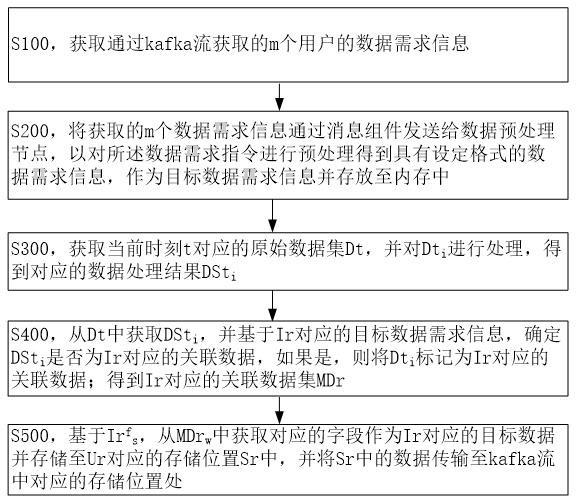
3、s100,获取通过kafka流获取的m个用户的数据需求信息,第r个数据需求信息ir={ur,ir1,ir2,……,irs,……,irg(r),mr};ir中的第s个数据需求项irs={irds,irfs},irds为irs对应的字段标识,irfs为irds对应的字段内容;r的取值为1到m,s的取值为1到g(r),g(r)为ir中的数据需求项的数量;mr为ir对应的关系标识,所述关系标识包括第一关系标识、第二关系标识和第三关系标识,第一关系标识用于表征ir1,ir2,……,irs,……,irg(r)之间满足第一关系,第二关系标识用于表征ir1,ir2,……,irs,……,irg(r)满足第二关系、第三关系标识用于表征ir1,ir2,……,irs,……,irg(r)满足第三关系;ur为第r个用户的id;
4、s200,将获取的m个数据需求信息通过消息组件发送给数据预处理节点,以对所述数据需求指令进行预处理得到具有设定格式的数据需求信息,作为目标数据需求信息并存放至内存中;
5、s300,获取当前时刻t对应的原始数据集dt={dt1,dt2,……,dti,……,dtn(t)},并对dti进行处理,得到对应的数据处理结果dsti={dsti1,dsti2,……,dstij,……,dstih},dti为dt中的第i条数据,i的取值为1到n(t),n(t)为dt中的数据量;dstij为dsti中的第j个数据处理结果,dstij={dstdij,dstfij},dstdij为dti的第j个字段标识,dstfij为dstdij对应的字段,j的取值为1到h,h为字段标识的数量;所述原始数据集基于kafka流得到;
6、s400,从dt中获取dsti,并基于ir对应的目标数据需求信息,确定dsti是否为ir对应的关联数据,如果是,则将dti标记为ir对应的关联数据;得到ir对应的关联数据集mdr={mdr1,mdr2,……,mdrw,……,mdrp(r)};mdrw为ir对应的第w个关联数据,w的取值为1到p(r),p(r)为ir对应的关联数据的数量;
7、s500,基于irfs,从mdrw中获取对应的字段作为ir对应的目标数据并存储至ur对应的存储位置sr中,并将sr中的数据传输至kafka流中对应的存储位置处。
8、可选地,在s400中,通过grpc协议获取dti。
9、可选地,s400具体包括:
10、s401,设置i=1;
11、s402,如果i≤n,执行s403;否则,执行s;
12、s403,从dt中获取dsti,并设置r=1;
13、s404,如果r≤m,执行s405;否则,执行s409;
14、s405,对于irs,从dsti获取对应的字段作为irs的关联字段dstrsi,如果irs∈dstrsi,则赋予irs第一标识,否则,赋予irs第二标识;执行s406;
15、s406,设置s=s+1,如果s≤g(r),执行s405,否则,执行s407;
16、s407,获取ir中的第一标识的数量p1r,如果mr为第一关系标识,并且如果p1r=g(r),或者,如果mr为第二关系标识,并且如果p1r≥1,则将dsti作为ir的关联数据;否则,则不将dsti作为ir的关联数据;执行s408;
17、s408,设置r=r+1,执行s404;
18、s409,设置i=i+1;执行s402;
19、s410,得到mdr,并退出当前控制程序。
20、可选地,在s405中,如果irs的长度大于设定阈值,则基于irs构建对应的双数组字典树。
21、可选地,s200还包括:
22、将所述目标数据需求信息进行持久化存储。
23、可选地,还包括:
24、s600,将sr中的数据按照第一存储周期存储至redis数据库中,以及将redis数据库中的数据按照第二存储周期进行持久化存储,其中,第二存储周期的时长大于第一存储周期的时长。
25、可选地,s300还包括:
26、如果n(t)>gt,则基于gt-n(t)在当前数据处理节点网络中增加对应数量的数据处理节点,作为新的数据处理节点网络,并将新的数据处理节点网络作为当前数据处理节点网络,以对dt进行处理;其中,gt为当前时刻t对应的数据处理节点网络的数据总处理量。
27、本发明至少具有以下有益效果:
28、本发明实施例提供的基于kafka流的数据处理方法,能够从海量的数据中及时且准确的获取到多个用户所需求的数据。
技术特征:
1.一种基于kafka流的数据处理方法,其特征在于,所述方法包括如下步骤:
2.根据权利要求1所述的方法,其特征在于,在s400中,通过grpc协议获取dti。
3.根据权利要求1所述的方法,其特征在于,s400具体包括:
4.根据权利要求3所述的方法,其特征在于,在s405中,如果irs的长度大于设定阈值,则基于irs构建对应的双数组字典树。
5.根据权利要求1所述的方法,其特征在于,s200还包括:
6.根据权利要求1所述的方法,其特征在于,还包括:
7.根据权利要求1所述的方法,其特征在于,s300还包括:
8.一种非瞬时性计算机可读存储介质,所述存储介质中存储有至少一条指令或至少一段程序,其特征在于,所述至少一条指令或所述至少一段程序由处理器加载并执行以实现如权利要求1-7中任意一项的所述方法。
9.一种电子设备,其特征在于,包括处理器和权利要求8中所述的非瞬时性计算机可读存储介质。
技术总结
本发明提供了一种基于kafka流的数据处理方法、电子设备和存储介质,包括:获取通过kafka流获取的m个用户的数据需求信息;将获取的m个数据需求信息通过消息组件发送给数据预处理节点,得到具有设定格式的目标数据需求信息;获取当前时刻t对应的原始数据集Dt;从Dt中获取DSt<subgt;i</subgt;,并基于Ir对应的目标数据需求信息,确定DSt<subgt;i</subgt;是否为Ir对应的关联数据,如果是,则将Dt<subgt;i</subgt;标记为Ir对应的关联数据;基于Ir<supgt;f</supgt;<subgt;s</subgt;,从MDr<subgt;w</subgt;中获取对应的字段作为Ir对应的目标数据。本发明能够从海量的数据中及时且准确的获取到多个用户所需求的数据。
技术研发人员:富佰成,方省,陈帅,曹家,罗引,王磊
受保护的技术使用者:北京中科闻歌科技股份有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!