一种基于多层次语义增强的多模态假新闻检测方法
本发明属于多模态假新闻检测领域,具体的说是一种基于多层次语义增强的多模态假新闻检测方法。
背景技术:
1、随着社交媒体平台越来越深入人们的生活,它们已成为公众获取信息的主要来源。遗憾的是,与之相伴的是假新闻内容的爆发性增长。由于假新闻内容的迷惑性,人们常常被其误导,进而影响自己的判断和决策。此外,假新闻还可能被用来歪曲和捏造事实,引导舆论,对社会信任和稳定产生不利影响。因此,为了阻止假新闻的激增,迫切需要自动检测方法来识别假新闻,提高社交媒体生态系统的可信度。假新闻检测是一个二元分类问题,其目标是分析新闻内容以确定其真实性。传统的假新闻检测侧重于文本内容,依靠从文本、社交媒体传播过程和用户互动中提取语义特征来检测假新闻。然而,随着多媒体技术的不断发展,造谣者越来越多地使用多模态内容(如有吸引力的图片)来吸引公众的注意力,以促进更快的传播。因此,多模态假新闻检测领域正受到越来越多的关注。
2、多模态假新闻检测领域已经取得了一些进展,但现有方法对新闻图像信息的利用还不够充分。一些方法简单的通过预先训练的vgg-19或resnet-50网络提取图像特征,或结合频域信息作为图像特征的补充。然而,这些方法都没有充分挖掘图像的语义信息,尤其是没有结合文本信息对图像特定内容进行语义提取。此外,简单的提取图像特征无法有效缩小图像和文本特征之间的模态差距,不利于后续的多模态融合。除了新闻内容的基本特征外,新闻实体的知识层面特征对于预测样本的真实性也至关重要。知识图谱由作为图节点的实体和作为边的不同类型的关系组成,其中蕴含着丰富的背景知识信息。因此,为了提高假新闻检测的性能,一些方法利用新闻实体的高阶知识语义信息作为客观证据来源,将其纳入模型中。对于视觉实体的获取,这些方法只是利用yolov3或fasterr-cnn来检测图像中的目标。然而,这对于视觉实体的检测是不够的,因为yolov3等检测器识别的视觉实体局限于预训练的实体类别,而图像描述中包含的实体类型往往蕴含一些开放世界中的实体。之后,这些方法通过对齐和融合视觉实体和文本实体,或在知识层面发现不一致的语义特征来进行虚假新闻检测。但这些方法往往忽略了添加外部知识所带来的额外噪声影响。在提取视觉或文本实体时,往往会识别出一些无关的新闻实体,其不仅无益于检测新闻内容的真实性,还会在模型中引入不同程度的噪声信息。
技术实现思路
1、本发明是为了解决上述现有技术存在的不足之处,提出一种基于多层次语义增强的多模态假新闻检测方法,以期能解决传统多模态假新闻检测方法未能充分挖掘图像潜在的语义信息的难题,并去除新闻实体中蕴含的噪声,获取精确的新闻知识语义信息,从而能更精准的检测多模态假新闻。
2、本发明为达到上述发明目的,采用如下技术方案:
3、本发明一种基于多层次语义增强的多模态假新闻检测方法的特点在于,是按如下步骤进行:
4、步骤一、多模态新闻数据的收集和预处理;
5、提取社交媒体平台上每条多模态新闻的文本内容及其对应的一张图像,得到新闻文本集和新闻图像集其中,ti表示第i条新闻文本;ii表示ti对应的第i张新闻图像;
6、设置第i张新闻图像ii及其第i条新闻文本ti的真实性标签,记为yi,且yi∈{0,1};从而构建训练数据集其中,n表示训练数据集中的新闻数量;
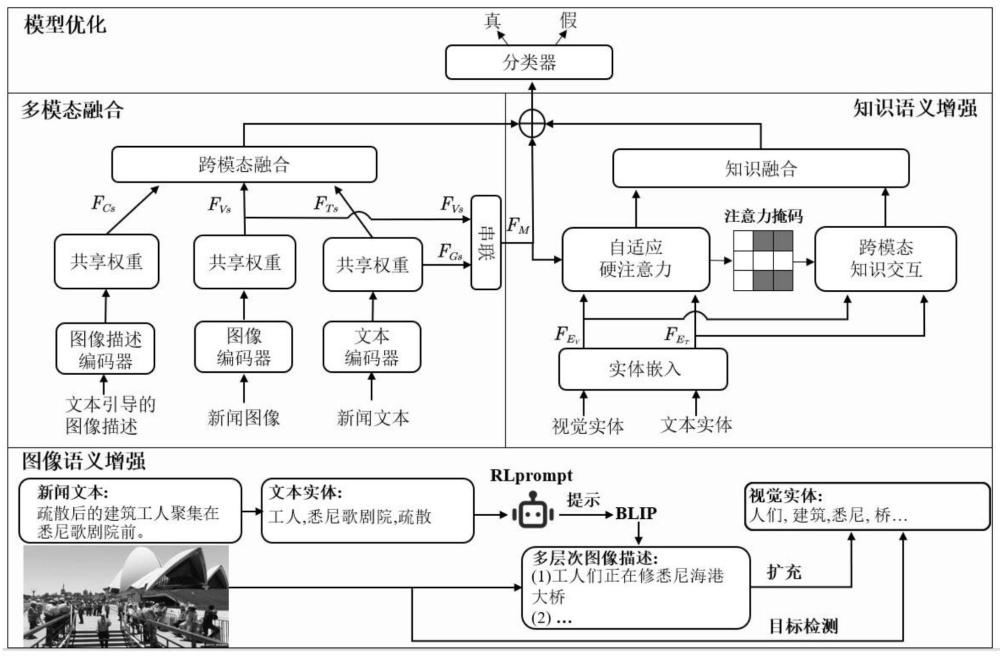
7、步骤二、构建多模态假新闻检测网络,包括:图像语义增强模块、多模态融合模块、知识语义增强模块;
8、步骤三、构建图像语义增强模块,包括:rlprompt单元、提示语句构建单元、blip模型;
9、步骤3.1、rlprompt单元生成n个待学习提示词{z}1{z}2...{z}k...{z}n;
10、步骤3.2、提示语句构建单元的处理:
11、步骤3.2.1、利用实体链接工具tagme对第i条新闻文本ti进行实体识别,得到文本实体集其中,表示第i条新闻文本ti中的第j个文本实体,m表示每条新闻文本中的文本实体数量;
12、步骤3.2.2、构建基于第i条新闻文本ti中两个文本实体作为提示主体词汇的交互提示语句表示第i条新闻文本ti中的第j’个实体;and表示连接符;
13、构建基于第i条新闻文本ti中单个文本实体作为提示主体词汇的局部提示语句
14、步骤3.3、blip模型生成第i条多模态新闻的图像描述集
15、将第i张新闻图像ii送入blip模型中,得到全局图像描述
16、将第i张新闻图像ii和交互提示语句pcon,i送入blip模型中,引导生成新闻的交互图像描述
17、将第i张新闻图像ii和局部提示语句ploc,i送入blip模型中,引导生成新闻的局部图像描述
18、步骤四、构建多模态融合模块,包括:特征提取单元、跨模态特征增强单元;
19、步骤4.1、特征提取单元用于提取多模态新闻的不同模态初始特征;
20、步骤4.2、跨模态特征增强单元用于对不同模态初始特征进行处理,并输出跨模态特征fn,i;
21、步骤五、构建知识语义增强模块,包括实体链接单元、自适应硬注意力机制单元、跨模态知识交互单元、知识融合单元;
22、步骤5.1、实体链接单元用于提取新闻实体并链接至知识图谱;
23、步骤5.2、自适应硬注意力机制单元用于对实体嵌入特征进行处理,得到过滤后的实体特征;
24、步骤5.3、跨模态知识交互单元用于对实体嵌入特征进行特征增强,得到实体知识交互特征;
25、步骤5.4、知识融合单元将过滤后的视觉实体特征fve,i、过滤后的文本实体特征fte,i、文本实体知识交互特征和图像实体知识交互特征串联后作为一组实体嵌入,之后应用自注意机制对所述实体嵌入进行进一步建模,并使用全连接层和平均池化层对建模后的实体嵌入进行处理,最终输出新闻背景知识特征fe,i;
26、步骤六、多模态假新闻检测网络的优化:
27、步骤6.1、利用式(8)预测第i条多模态新闻为假新闻的概率
28、
29、式(8)中,σ代表sigmoid激活函数,wc表示分类器的权重矩阵,bc表示偏差向量;f′m,i表示维度改变后的全局多模态新闻特征;
30、步骤6.2、利用式(9)构建交叉熵损失函数
31、
32、步骤6.3、基于所述训练数据集x,使用adam优化策略对所述多模态假新闻检测网络进行训练,直至网络总损失函数收敛为止,从而得到最优多模态假新闻检测模型,用于对任一多模态新闻进行预测。
33、本发明所述的基于多层次语义增强的多模态假新闻检测方法的特点也在于,所述步骤3.1包括:
34、步骤3.1.1、rlprompt单元利用distilgpt-2语言模型从词汇表中学习待学习提示词{z}1{z}2...{z}k...{z}n;其中,{z}k表示第k个待学习的提示词;n代表提示词的个数;
35、步骤3.1.2、将起始符<start>输入冻结后的distilgpt-2模型中,得到起始符<start>的上下文嵌入,并利用两层mlp层对上下文嵌入进行重编码,得到编码特征后传递给冻结后的distilgpt-2模型的分类头,从而输出第1个提示词{z}1;
36、步骤3.1.3、基于步骤2.1.2,将第1个提示词{z}1按照自回归生成方式输入冻结后的distilgpt-2模型中,从而逐步生成长度为n的待学习提示词{z}1{z}2...{z}k...{z}n。
37、所述步骤4.1包括:
38、步骤4.1.1、使用预训练的bert模型对第i条新闻文本ti进行特征提取,得到第i条新闻文本ti的特征序列ft,i=[f1.i,f2.i,...,fl.i,...,fl.i],其中,fl.i表示所述第i条新闻文本ti中第l个词级别的文本特征;
39、利用长短期记忆网络lstm对特征序列ft,i进行进一步特征提取,并取长短期记忆网络lstm的最后一个步长输出的隐状态特征作为第i条新闻文本ti的全局特征fg,i;
40、步骤4.1.2、使用所述冻结后的blip模型中的视觉特征编码器对第i张新闻图像ii进行特征提取,得到图像特征fv,i;
41、步骤4.1.3、使用所述冻结后的blip模型中的文本特征编码器对图像描述集ci进行特征提取,得到图像描述特征fc,i;
42、步骤4.1.4、使用一个共享权重的mlp层改变特征序列ft,i和全局特征fg,i的维度,使其与图像特征fv,i和图像描述特征fc,i的维度一致,得到维度变化的特征序列f′t,i和全局特征f′g,i。
43、所述步骤4.2包括:
44、步骤4.2.1、构建一个由一层m×n的线性层和一层relu激活函数层组成的mlp层,将f′t,i、f′g,i、fv,i、fc,i分别输入共享权重为wshared的mlp层中进行处理后,得到第i条新闻文本ti的文本中间特征序列fts,i、第i条新闻文本ti的全局文本中间特征fgs,i,第i张新闻图像ii的图像中间特征fvs,i,新闻图像描述ci的图像描述中间特征fcs,i;
45、步骤4.2.2、根据式(1),应用新闻图像中间特征fvs,i对文本中间特征序列fts,i进行注意力操作,从而得到图像增强的文本特征fvt,i;应用文本中间特征序列fts,i分别对图像中间特征fvs,i和图像描述中间特征fcs,i进行注意力增强操作,从而得到文本增强的图像特征ftv,i和文本增强的图像描述特征ftc,i:
46、
47、式(1)中,qv,i表示基于图像中间特征fvs,i的查询向量,kt,i表示基于文本中间特征序列fts,i的键向量,vt,i表示基于文本中间特征序列fts,i的值向量,d1表示查询向量、键向量和值向量的维度大小,softmax表示将实数向量映射为概率分布的数学函数,t表示转置,wvt表示图像一文本注意力操作的权重矩阵,qt,i表示基于文本中间特征序列fts,i的查询向量,kv,i表示基于图像中间特征fvs,i的键向量,vv,i表示基于图像中间特征fvs,i的值向量,wtv表示文本-图像注意力操作的权重矩阵,kc,i表示基于图像描述中间特征fcs,i的键向量;vc,i表示基于图像描述中间特征fcs,i的值向量,wtc表示文本-图像描述注意力操作的权重矩阵;
48、步骤4.2.3、将fvt,iftv,i和ftc,i串联后作为一组中间特征,并应用自注意机制对所述中间特征进行进一步建模,之后使用全连接层和平均池化层对建模后的特征进行处理,最终输出跨模态特征fn,i。
49、所述步骤5.1包括:
50、步骤5.1.1、使用百度openai平台的api识别第i张新闻图像ii中的物体和名人,并使用实体链接工具tagme对全局图像描述提取额外的视觉实体,从而形成新闻视觉实体集其中,表示第i张新闻图片ii中的第t个实体,t表示每张新闻图片的实体数量;步骤5.1.2、使用预训练好的实体表征模型transe将文本实体集和视觉实体集链接至freebase知识图谱中,从而获得文本实体嵌入特征和视觉实体嵌入特征
51、所述步骤5.2包括:
52、步骤5.2.1、将全局文本中间特征fgs,i和图像中间特征fvs,i拼接,构成全局多模态新闻特征fm,i,并使用另一个mlp层改变全局多模态新闻特征fm,i的维度,使其与实体嵌入特征的维度一致,得到维度改变后的全局特征f′m,i;
53、步骤5.2.2、利用f′m,i对视觉实体嵌入特征进行自适应硬注意力操作,从而利用式(2)和式(3)计算得到全局特征f′m,i对视觉实体嵌入相应的注意力分数α1,i和相似度矩阵β1,i;
54、
55、
56、式(2)和式(3)中,qm,i表示基于全局多模态新闻特征fm,i的查询向量,表示基于视觉实体嵌入特征的键向量,d2表示查询向量、键向量和值向量的维度;
57、步骤5.2.3、利用式(4)计算注意力分数α1,i的阈值δ1,i:
58、
59、步骤5.2.4、当第t个视觉实体对应的注意力分数小于阈值δ1,i时,认为第t个视觉实体与新闻无关,并将其对应相似度设置为--oo;否则,保持原始相似度不变,从而得到更新后的相似度矩阵;
60、步骤5.2.5、对更新后的相似度矩阵重新进行softmax操作,得到更新后的注意力得分α1,i,并利用式(5)进行后续的注意力操作,以获得过滤后的视觉实体特征fve,i;
61、
62、式(5)中,表示基于视觉实体嵌入特征的值向量,表示视觉实体自适应硬注意力机制的权重矩阵;
63、步骤5.2.6、按照步骤4.2.1-步骤4.2.5的过程,利用全局特征f′m,i对文本实体嵌入进行相同的自适应硬注意力操作,从而得到更新后的文本实体相似度矩阵β2,i和过滤后的文本实体特征fte,i。
64、所述步骤5.3包括:
65、步骤5.3.1、根据视觉实体相似度矩阵β1,i和文本实体相似度矩阵β2,i,将相似度为-∞的实体所对应的值设置为0,相似度不为-∞的实体所对应的值将被设置为1,从而得到相应的视觉实体选择序列η1,i和文本实体选择序列η2,i;
66、步骤5.3.2、将视觉实体选择序列η1,i和文本实体选择序列η2,i进行点乘,得到注意力掩码maskc,i;
67、步骤5.3.3、应用视觉实体嵌入和注意力掩码maskc,i对文本实体嵌入进行注意力操作,从而利用式(6)得到文本实体知识交互特征
68、
69、式(6)中,表示基于视觉实体嵌入的查询向量,表示基于文本实体嵌入的键向量,表示基于文本实体嵌入的值向量,d3表示查询向量、键向量和值向量的维度;表示视觉-文本实体注意力操作的权重矩阵;
70、应用文本实体嵌入和注意力掩码的转置对视觉实体嵌入进行注意力操作,从而利用式(7)得到图像实体知识交互特征
71、
72、式(7)中,表示基于文本实体嵌入的查询向量,表示基于视觉实体嵌入的键向量,表示基于视觉实体嵌入的值向量,表示文本-视觉实体注意力操作的权重矩阵。
73、所述步骤3.1.2中的两层mlp层是按如下步骤进行优化,以得到最佳提示词;
74、步骤a、将图像描述集ci作为第i条新闻ti的额外信息送入最优多模态假新闻检测模型中,并计算第i条新闻ti为假的概率;
75、步骤b、利用式(1)得到最优多模态假新闻检测模型预测的正确标签yi的概率pz(yi):
76、
77、式(1)中,pz(yi|zi,xi)代表最优多模态假新闻检测模型计算所得的假新闻概率,zi代表待学习的提示词{z}1{z}2...{z}k...{z}n,xi代表第i条多模态新闻的所有新闻内容,包括新闻文本ti,新闻图像ii和新闻图像描述ci;
78、步骤c、将正确标签和错误标签之间的概率差距记为gapz(yi)=pz(yi)-(1-pz(yi));
79、当最优多模态假新闻检测模型预测正确时,gapz(yi)为正值,否则为负值;
80、对于正确的预测,将gapz(yi)乘以一个较大的数值λ来表示预测的可取性,其中,当yi=1时,取值λ2,当yi=0时,取值λ1;
81、步骤d、利用distilgpt-2模型生成xi的多组提示词z(xi),从而利用式(2)计算任意一组提示词z∈z(xi)的奖励r(xi,yi,zi);
82、
83、步骤e、通过计算奖励的平均值和标准差对其进行归一化处理,从而利用式(3)计算多组提示词z(xi)的奖励z-score(xi,yi,z(xi)):
84、
85、步骤f、基奖励z-score(xi,yi,z(xi)),应用soff q-learning算法对两层mlp层的参数进行更新,得到优化后的两层mlp层。
86、本发明一种电子设备,包括存储器以及处理器的特点在于,所述存储器用于存储支持处理器执行所述多模态假新闻检测方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
87、本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序的特点在于,所述计算机程序被处理器运行时执行所述多模态假新闻检测方法的步骤。
88、与现有技术相比,本发明的有益效果在于:
89、1、本发明通过强化学习发现最佳提示格式,并引导blip模型生成与特定文本实体相关的图像描述,从而充分挖掘图像潜在的语义信息。同时本发明还利用生成的图像描述扩展视觉实体,并通过自适应硬注意力机制提取精确的新闻高阶知识语义信息,从而提高了多模态假新闻检测的准确率。
90、2、本发明将新闻文本实体作为提示主体词汇,并应用强化学习发现最佳提示格式,以生成文本引导的图像描述,从而解决了充分挖掘新闻图像潜在的语义信息的难题,进而提高了多模态假新闻检测的准确率。
91、3、本发明将新闻中蕴含的实体链接在知识图谱中从而获取新闻知识表征,并将其输入知识语义增强模块,以自动选择强相关的新闻实体,去除新闻无关的噪声实体,从而获得精确的新闻高阶知识语义特征,从而提高了多模态假新闻检测的准确率。
- 还没有人留言评论。精彩留言会获得点赞!