基于原型的多异构参与方的纵向联邦学习系统及方法
本发明涉及一种基于原型的多异构参与方的纵向联邦学习系统及方法,属于信息安全保护与联邦学习。
背景技术:
1、在现实的应用场景中,数据往往分布在多个参与方(例如银行单位和电商平台)中。为了训练得到较优的模型,希望参与方能够共享本地数据特征来协同实现数据分析和建模。然而,各个数据持有者担心将自己的数据暴露给其他方或者第三方,从而导致隐私泄露和商业机密被窃取。
2、目前,传统的机器学习方法是将所有的数据聚集到同一个服务器中,然后进行全局模型训练。然而,传统的机器学习方法容易导致数据泄露和隐私侵犯的问题,因此,需要一种新的数据协作技术来保证数据安全。
3、纵向联邦学习作为一种新型的机器学习技术,通过共享模型而不是共享数据来实现各方的协同训练,这在一定程度上保护了原始数据的安全。此外,纵向联邦学习实现了各参与方样本对齐特征联合的模型训练,因而受到学术界和工业界的广泛关注。然而,现有的纵向联邦学习方法仍然存在一些问题。当参与方本地拥有异构模型的情况下,则无法训练一个性能较优的模型。此外,现有的纵向联邦学习技术无法同时训练多异构模型,无法满足参与方拥有异构模型的情况下实现模型训练。
4、目前,纵向联邦学习方法主要有以下两种类型:
5、类型1:基于聚合的纵向联邦学习训练方法。首先将全局模型分发给主动方和被动方。在训练过程中,主动方和被动方分别利用自己的数据训练模型,计算得到模型的输出预测结果。被动方将中间结果使用加密的方式发送给主动方,让主动方协助计算损失和梯度。主动方利用自己模型的损失和被动方发来的损失计算得到加密的聚合损失。主动方和被动方用聚合损失计算梯度来更新本地模型参与。
6、但是,该方法在参与方本地模型是异构的情况下,无法训练得到性能较优的模型参数。这是由于基于聚合的纵向联邦学习方法聚合的本地模型的预测结果,而预测结果中包含本地模型信息和本地特征信息,聚合本地模型信息对模型的精度造成一定的负面影响,从而导致模型收敛速度慢。其次,该方法只能训练得到一个全局模型,而不能同时训练多个异构模型,在实际应用中面临较多限制。
7、类型2:基于拆分的纵向联邦学习训练方法。该方法将一个全局模型划分为顶层模型和底层模型。每个参与方使用自己的数据训练底层模型,被动方将模型输出结果发送给主动方,主动方聚合来自被动方以及自己的底层模型的输出,并将聚合之后的结果作为顶层模型的输入,继续完成顶层模型的前向传播过程。当前向传播结束后,主动方计算损失函数,完成顶层模型的梯度下降过程。最后,主动方向被动方回传各自的梯度,被动方利用收到的梯度完成底层模型的更新。
8、与类型1类似,该方法也面临着在参与方本地异构模型的情况下只能训练一个全局模型,存在收敛速度慢、模型性能低下等问题,限制了纵向联邦学习的应用。参与方的本地模型往往是异构的。
9、因此,在参与方本地是异构模型的场景下,如何有效且能够同时训练多个异构模型,提高异构模型的性能,是当前面临的关键性问题。
技术实现思路
1、本发明的目的是针对现有技术存在的问题和缺陷,为了有效解决在异构客户端情况下数据共享时存在数据泄露和隐私侵犯风险的技术问题,创造性地提出一种基于原型的多异构参与方的纵向联邦学习系统及方法。
2、首先,对本发明涉及的概念和内容进行说明。
3、参与方:指拥有本地数据并参与到联邦学习训练的客户端。此外,将参与方分为两类,一类是主动方,也就是拥有标签值和本地特征的客户端,另一类是被动方,也就是只拥有本地特征的客户端。
4、纵向联邦学习:指在保证参与方的本地数据不出域的情况下,各参与方实现样本对齐特征联合的联邦学习训练过程。
5、表示层:指本地异构网络的激活函数之前的部分。通过表示层将所有的本地特征嵌入到相同的空间中,输出本地嵌入值。
6、决策层:指本地异构网络的激活函数之后的部分,通过决策层来得到本地异构网络的预测结果。
7、原型:指本地异构网络的表示层输出的本地嵌入值。由于所有的参与方都将各自本地特征嵌入到相同的空间中,称本地嵌入值为原型。
8、本发明采用以下技术方案实现。
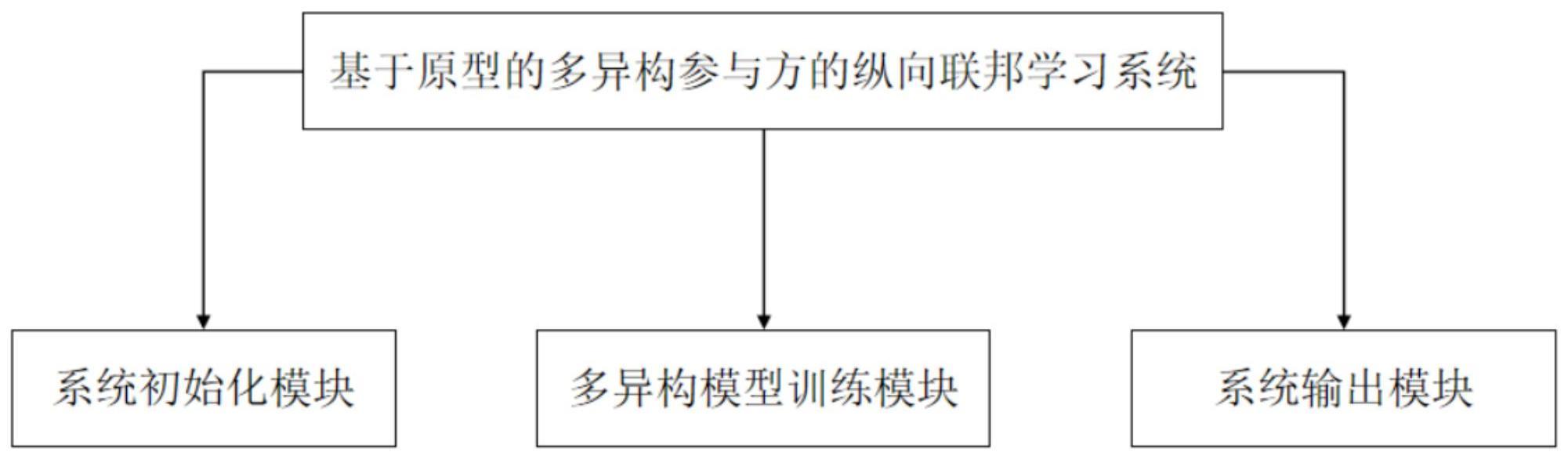
9、一方面,本发明提出了一种基于原型的多异构参与方的纵向联邦学习系统,包括系统初始化模块、多异构模型训练模块和系统输出模块。
10、系统初始化模块,用于初始化训练任务和选择纵向联邦学习参与方。系统初始化模块包含训练任务初始化模块和参与方选择模块,其中,训练任务初始化模块用于任务发布者根据自己的需求发布相关的训练任务,参与方选择模块用于任务发布者根据任务需求选择参与纵向联邦学习训练的参与方。
11、多异构模型训练模块,用于纵向联邦学习中各参与方协同训练和异构模型更新;
12、系统输出模块,用于输出参与方训练得到的收敛多异构模型。
13、其中,任务的发布者调用系统初始化模块,用于初始化训练任务和选择参与纵向联邦学习的参与方;参与方同时允许多异构模型训练模块,实现参与方本地异构模型的更新;系统输出模块输出参与方更新得到最终的本地异构模型。
14、上述组成模块之间的连接关系如下:
15、系统初始化模型的输出端与多异构模型训练模块的输入端相连,将系统初始化模型的内容发送给多异构模型训练模块。多异构模型训练模型的输出端与系统输出模块的输入端相连接,将多异构模型训练模块训练得到的异构模型发送给系统输出模块。
16、另一方面,本发明提出了一种基于原型的多异构参与方的纵向联邦学习方法,包括以下步骤:
17、步骤1:模型初始化。参与方分别初始化本地模型参数和本地优化算法。
18、步骤2:在不暴露参与方本地数据的情况下,各参与方使用隐私集合求交技术求得所有参与方的数据交集。其中,参与方包括被动方和主动方。
19、步骤3:各个参与方使用本地数据和本地模型的表示层计算本地嵌入值。
20、具体地,包括以下步骤:
21、步骤3.1:各个参与方将本地数据特征作为本地模型表示层的输入。经过表示层的计算后,输出本地嵌入值;
22、步骤3.2:各个参与方将本地嵌入值添加随机数来保护本地原始数据的安全。
23、步骤3.3:各个参与方将具有随机数的本地嵌入值发送给主动方。
24、步骤4:主动方计算全局嵌入值。
25、具体地,包括以下步骤:
26、步骤4.1:主动方收集所有被动方发送的具有随机数的本地嵌入值;
27、步骤4.2:主动方使用平均聚合,聚合所有参与方的本地嵌入值,得到具有随机数的全局嵌入值。
28、步骤4.3:主动方将具有随机数的全局嵌入值减去随机数,得到真正的全局嵌入值,简称全局嵌入值。
29、步骤4.4:主动方将全局嵌入值发送给所有的参与方。
30、步骤5:所有参与方并行计算本地预测结果。
31、具体地,包括以下步骤:
32、步骤5.1:参与方获得全局嵌入值。
33、步骤5.2:参与方使用全局嵌入值和本地模型的决策层,计算得到本地预测结果。
34、步骤5.3:参与方将本地预测结果发送给主动方。
35、步骤6:主动方计算损失值。
36、具体地,包括以下步骤:
37、步骤6.1:主动方获得参与方的本地预测结果。
38、步骤6.2:主动方将本地标签值和参与方的本地预测结果作为损失函数的输入,计算得到各个参与方的损失值。
39、步骤6.3:主动方将各个参与方的损失值发送给各个参与方。
40、步骤7:各个参与方并行的反向传播更新本地模型。
41、具体地,包括以下步骤:
42、步骤7.1:参与方获得损失值;
43、步骤7.2:参与方根据损失值和本地优化函数更新优化本地模型参数。
44、步骤8:重复步骤3至步骤7,直到训练模型收敛或达到预先协商的最大训练轮数,此时停止训练。
45、由此,实现了在不泄露数据和侵犯隐私的情况下的多异构参与方的纵向联邦学习。
46、有益效果
47、本发明方法,与现有技术相比,具有以下优点:
48、1.本发明提高了在异构参与方的本地模型的情况下纵向联邦学习的训练模型的精度。本发明采用原型聚合的方式来汇集所有参与方的本地知识值,减少了对异构模型信息的依赖,从而减少了其他参与方异构模型信息对训练模型精度的影响,提高了训练模型的精度。
49、2.本发明可以同时训练多个异构模型,也就是每个参与方拥有的本地模型都可以得到训练,并获得收敛性模型。
50、3.本发明具有良好的隐私保护能力。本发明聚合的原型而不是原始数据,从而降低了原始数据泄露的风险。此外,在本地嵌入值中注入了随机数,使得主动方无法获得参与方的本地嵌入值,从而进一步保护了参与方的原始数据。
- 还没有人留言评论。精彩留言会获得点赞!