基于中间索引的法律规范条文检索方法及系统与流程
本发明属于法规智能推荐,尤其涉及一种基于中间索引的法律规范条文检索方法及系统。
背景技术:
1、在进行企业隐患排查时,专家人员需要根据隐患情况给出该隐患在相应法律规范中对应的具体条款,作为后续处罚和整改的依据。而在实际工作过程中,企业出现的隐患往往是相似的,但每次隐患填报均需要提供完整准确的法律规范条文。现有的处理方法是由专家人员在现场先记录检查中出现的所有隐患,再根据隐患描述内容人工查询每条隐患对应的现行法律规范条文,该处理方法人工成本和时间成本较高,不利于企业隐患快速排查。为了简化专家隐患排查的工作流程,可以在专家填写隐患描述内容后直接检索并推荐该隐患可能涉及的法律规范条文供专家选择。
2、传统的文档检索方法可以分为基于词汇的文档检索方法和基于语义的文档检索方法两大类。在根据隐患描述内容检索法律规范条文的场景中,隐患内容趋近于现实性描述,而法律规范条文的内容却偏向于概括性描述,所以基于词汇的文档检索方法检索的准确率较低,而基于语义的文档检索方法计算资源消耗较大,不能实时推荐检索结果。
技术实现思路
1、本发明的目的在于解决上述技术问题之一,提供一种基于中间索引的法律规范条文检索方法及系统。
2、为实现上述目的,本发明采用的技术方案是:
3、一种基于中间索引的法律规范条文检索方法,包括以下步骤:
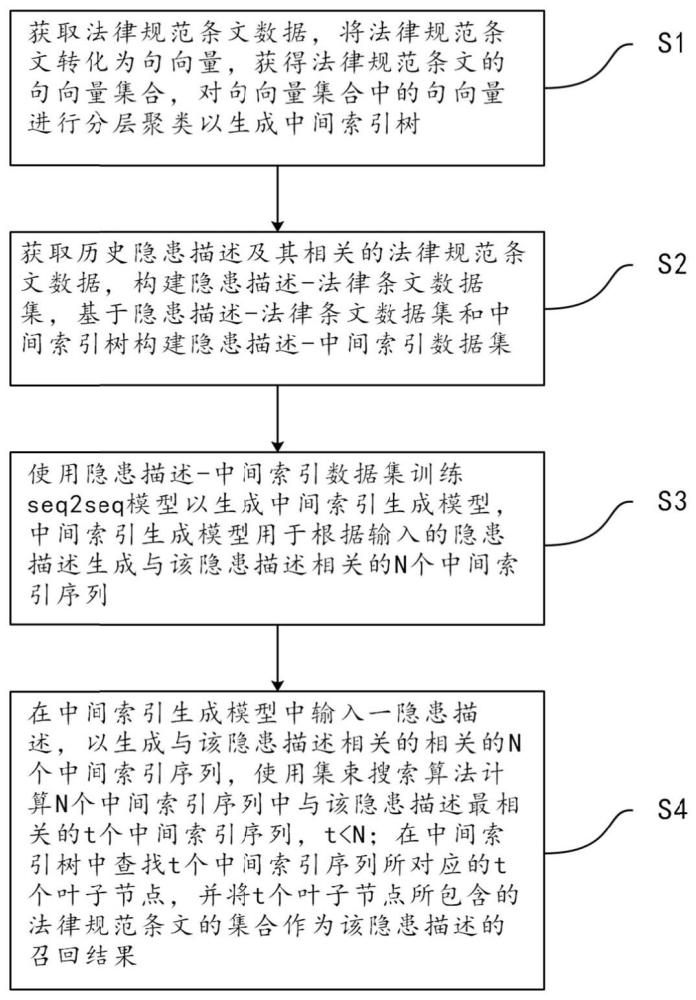
4、s1:获取法律规范条文数据,将法律规范条文转化为句向量,获得法律规范条文的句向量集合,对句向量集合中的句向量进行分层聚类以生成中间索引树;中间索引树的每一叶子结点均对应有唯一的中间索引序列,并且,每一叶子结点均包含至少一条句向量及其对应的法律规范条文;
5、s2:获取历史隐患描述及其相关的法律规范条文数据,构建隐患描述-法律条文数据集,基于隐患描述-法律条文数据集和中间索引树构建隐患描述-中间索引数据集;
6、s3:使用隐患描述-中间索引数据集训练seq2seq模型以生成中间索引生成模型,中间索引生成模型用于根据输入的隐患描述生成与该隐患描述相关的n个中间索引序列;
7、s4:在中间索引生成模型中输入一隐患描述,以生成与该隐患描述相关的n个中间索引序列,使用集束搜索算法计算n个中间索引序列中概率最高的t个中间索引序列,t<n;在中间索引树中查找t个中间索引序列所对应的t个叶子节点,并将t个叶子节点所包含的法律规范条文的集合作为该隐患描述的召回结果。
8、本发明一些实施例中,步骤s1具体包括以下步骤:
9、s11:读取法律规范文档,按照法律规范的章节条目提取其中包含的法律规范条文;
10、s12:使用sentence-bert模型将提取到的法律规范条文批量转化为句向量,并基于法律规范的章节条目对句向量进行聚合,获得聚合后的句向量数据集;
11、s13:使用k-means算法处理聚合后的句向量数据集中的句向量,按照分层聚类的方法逐层构建中间索引树,中间索引树的每一叶子结点均对应有唯一的中间索引序列,并且,每一叶子结点均包含至少一条句向量;
12、s14:将每一叶子结点包含的句向量所对应的法律规范条文均存储至该叶子结点。
13、本发明一些实施例中,对句向量进行聚合的方法包括以下步骤:
14、法律规范包括多级标题,确定法律规范中的某一级标题为预定级别标题;
15、计算同一预定级别标题下包含的多条法律规范条文的平均句向量,将平均句向量作为多条法律规范条文的整体句向量。
16、平均句向量的计算公式为:
17、
18、其中,是平均句向量,h是待聚合句向量的总数,vi是第i个待聚合向量,i是待聚合句向量的编号。
19、本发明一些实施例中,进行分层聚类的方法包括以下步骤:
20、将句向量数据集中的句向量按n个类别进行聚类;
21、遍历聚类后的n个类别,检测是否存在句向量条数大于m条的类别;
22、对所有句向量条数大于m条的类别,新建一层继续按n个类别进行聚类,直至所有类别中的句向量条数均小于或等于m条。
23、本发明一些实施例中,隐患描述-法律条文数据集中每一隐患描述均对应有至少一条与其相关的法律规范条文;
24、所有隐患描述-中间索引数据集中,每一隐患描述均对应有至少一个中间索引序列。
25、本发明一些实施例中,构建隐患描述-中间索引数据集的方法包括:
26、遍历隐患描述-法律条文数据集;
27、查找隐患描述-法律条文数据集中的每一法律规范条文在中间索引树中对应的叶子结点;
28、将每一法律规范条文对应的隐患描述与其在中间索引树中对应的叶子结点的中间索引序列建立联系以生成隐患描述-中间索引数据集。
29、本发明一些实施例中,步骤s2还包括以下步骤:
30、选取预定数量的法律规范条文,每一法律规范条文随机截取k个连续词汇作为该法律规范条文的补充隐患描述;
31、将选取的法律规范条文与其对应的补充隐患描述补充至隐患描述-法律条文数据集。
32、本发明一些实施例中,步骤s3具体包括以下步骤:
33、s31:构建基于transformer编解码架构的seq2seq模型;
34、s32:将隐患描述-中间索引数据集导入seq2seq模型,将隐患描述-中间索引数据集中的隐患描述作为模型输入,将隐患描述-中间索引数据集中的中间索引序列作为模型输出,训练seq2seq模型以生成中间索引生成模型。
35、本发明一些实施例进一步提供一种基于中间索引的法律规范条文检索系统,包括:
36、索引树构建模块:用于将法律规范条文转化为句向量,并对转化出的句向量进行分层聚类以生成中间索引树;
37、数据集构建模块:用于读取历史隐患描述及其相关的法律规范条文数据,构建隐患描述-法律条文数据集,以及,基于隐患描述-法律条文数据集和中间索引树构建隐患描述-中间索引数据集;
38、模型训练模块:用于构建seq2seq模型,使用隐患描述-中间索引数据集训练seq2seq模型以生成中间索引生成模型;
39、相关度计算模块:用于使用集束搜索算法在中间索引生成模型输出的n个中间索引序列中计算概率最高的t个中间索引序列;
40、法规召回模块:用于在中间索引树中查找相关度计算模块计算出的t个中间索引序列所对应的t个叶子节点,并输出t个叶子节点所包含的法律规范条文的集合。
41、本发明一些实施例中,索引树构建模块包括:
42、法规读取单元:用于读取法律规范,并按照法律规范的章节条目提取其中包含的法律规范条文;
43、句向量转化单元:用于将法规读取单元提取到的法律规范条文转化为句向量,对转化出的句向量进行聚合以获得聚合后的句向量集合;
44、分层聚类单元:用于使用k-means算法对句向量转化单元生成的句向量数据集中的句向量进行分层聚类,以生成中间索引树。
45、本发明的有益效果在于:
46、1、本发明所提供的法律规范条文检索方法能够针对隐患描述检索并推荐与其相关的法律规范条文;
47、2、本发明所提供的法律规范条文检索方法能够根据法律规范条文间的语义特征构建树形中间索引,再借助生成式神经网络模型将隐患描述转化为中间索引以检索法律规范条文,相比于传统的基于词汇的文档检索方法和基于语义的文档检索方法,提升了法律规范条文推荐的准确度,降低了计算资源的消耗,提高了检索速度。
- 还没有人留言评论。精彩留言会获得点赞!