文本隐式篇章关系识别方法、系统、设备及存储介质
本发明属于自然语言处理,具体涉及一种文本隐式篇章关系识别方法、系统、设备及存储介质。
背景技术:
1、隐式篇章关系识别作为篇章分析中一项重要的基础任务,在pdtb v2.0发布之后有了更细化的分类标准和更成熟的任务评价体系,提供了一个标准的数据集和评测基准,使得研究人员可以比较不同的篇章关系识别模型的性能,并推动该领域的研究进一步发展。该语料库也是隐式篇章关系识别的基准语料库,该语料库规定并细化了篇章关系的种类,将所有类别进行三个粒度的划分,分别定义为类别(class)、类型(type)与子类(subtype)。类别层面将所有篇章关系分为四个类别:比较关系(comparison),偶然关系(contingency),时序关系(temporal),扩展关系(expansion),类型层面细化为16种类型,子类层面更进一步有23种子类。
2、隐式篇章关系的识别在近些年的发展中也经历了不同的研究阶段,早期的研究主要是通过篇章中的语言结构和语用功能人工提取统计文本中的特征词对,并使用传统机器学习方法识别篇章关系。不过此类方法需要人工标注特征,耗时耗力且泛化能力弱,由于时间成本和模型效果的问题已经不再使用了。近年来,随着深度学习与神经网络的进一步发展,此类模型也逐渐广泛应用于隐式篇章关系识别任务中,这些模型使用深度学习方法,结合自然语言处理技术,通过对句子进行编码和表示学习,以及使用关系分类器,能够有效地识别出句子之间的因果关系、条件关系、转折关系等。这些模型的性能不断提高,能够在多种应用领域,如信息提取、问答系统和机器阅读理解等方面发挥重要作用。然而,当前的挑战之一是对于特定领域文本的处理和理解,以及对于复杂关系的准确抽取和表示仍然存在一定的困难。未来的发展方向包括结合更多的语义信息、引入更多的上下文理解以及改进模型的解释性和可解释性等方面。
3、现有技术针对教育领域文本中隐式篇章关系识别效果较差,由于教育领域涉及多学科知识,例如心理学、教育管理、教育技术等,文本内容繁杂、涵盖面广,每个领域都有大量的专业术语。这些术语通常是由多个单词组成的术语组合,其中有些术语组合甚至在不同领域中也具有不同的含义。因此,在隐式篇章关系识别任务中,需要对教育领域中使用的专业术语有深入的了解,并能够在上下文中准确地识别和使用这些术语。同时,由于术语组合的复杂性和多样性,模型需要具有一定的语义理解能力,以推断出不同术语组合的含义,并将它们与文本中的其他信息进行整合,从而准确地识别隐含的关系。
技术实现思路
1、本发明的目的在于针对上述现有技术对于教育领域文本中隐式篇章关系识别效果较差的问题,提供一种文本隐式篇章关系识别方法、系统、设备及存储介质,通过外部知识融合辅助理解论元内实体,以及通过细粒度多角度理解论元关系,发掘得到更深层次的论元交互表征结果,进而更好地对含义复杂的论元进行判别,提升文本识别效果。
2、为了实现上述目的,本发明有如下的技术方案:
3、第一方面,提供一种文本隐式篇章关系识别方法,包括:
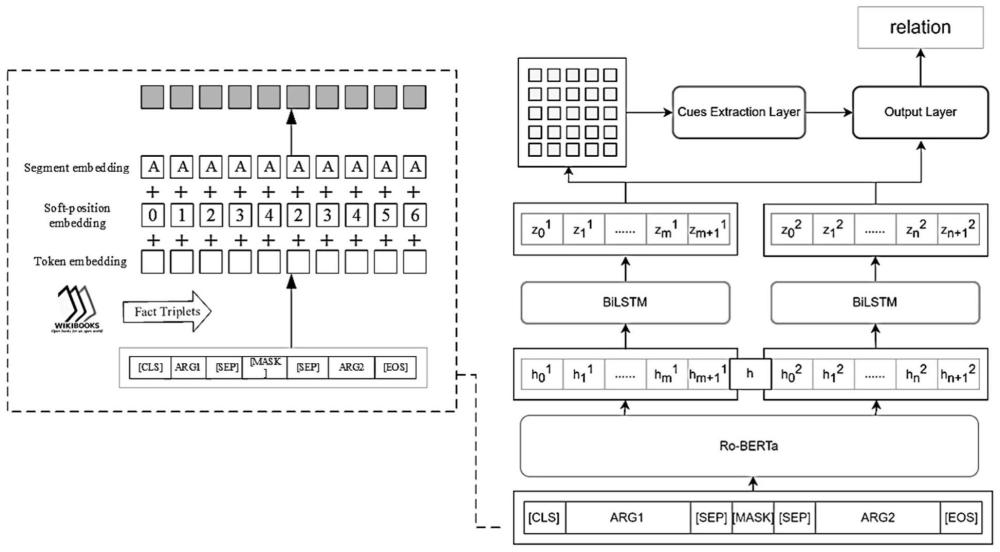
4、将论元拼接作为输入,使用roberta预训练模型进行编码,在外部知识融合时使用k-bert模型引入知识图谱信息辅助理解论元内实体,之后对两个论元的语义向量进行拆分,使用bi-lstm模型获取包含更多序列信息的各论元整体表示,得到融合了外部信息的论元;
5、仿照人类理解论元关系的过程,对论元间词汇两两配对计算细粒度线索分数,构建得到细粒度多角度线索矩阵,抽取对当前关系有用的线索特征进行篇章关系的类别判定;
6、结合整体语义与对当前关系有用的线索特征联合判断关系类别,通过将线索特征与整句语义综合,获取到综合表征,输出隐式篇章关系类别。
7、作为一种优选方案,所述将论元拼接作为输入,使用roberta预训练模型进行编码,在外部知识融合时使用k-bert模型引入知识图谱信息辅助理解论元内实体,之后对两个论元的语义向量进行拆分的步骤包括:
8、分别给定两个论元的数学表达式如下:
9、
10、
11、式中,arg1中包含m个词,是arg1中的第i个词;
12、arg2中包含n个词,是arg2中的第j个词;
13、对arg1和arg2进行拼接构建输入如下:
14、
15、式中,[cls]、[sep]、[mask]是roberta规定的特殊分隔符,[cls]用于表示两论元拼接输入的起始,[sep]用于对论元单位进行分割,[mask]用于对两论元间语句遮挡或对两论元间进行特定分割,在输入构建完成后,通过外部知识三元组对论元中的词汇进行补充表征;
16、将补充表征后的论元输入roberta模型中进行遍码,得到融合上下文信息的语义向量:
17、
18、式中,是arg1的向量部分,是arg2的向量部分;
19、将两个论元的语义向量拆分开得到两个论元各自的语义向量:
20、
21、
22、式中,h1是arg1的语义向量,h2是arg2的语义向量,得到的单个论元语义向量用于后续计算细粒度的逻辑线索。
23、作为一种优选方案,所述使用bi-lstm模型获取包含更多序列信息的各论元整体表示,得到融合了外部信息的论元计算表达式如下:
24、
25、
26、
27、式中,lstm(·)表示一个lstm单元的计算,具体表示为:
28、it=σ(whixt+wzizt-1+bi)
29、ft=σ(whfxt+wzfzt-1+bf)
30、
31、ot=σ(whoxt+wzozt-1+bo)
32、
33、zt=ot⊙tanh(ct)
34、式中,whi,wzi,bi分别是输入门的权重矩阵、隐藏状态的权重矩阵和偏置向量;
35、whf,wzf,bf分别是遗忘门的权重矩阵、隐藏状态的权重矩阵和偏置向量;
36、who,wzo,bo分别是输出门的权重矩阵、隐藏状态的权重矩阵和偏置向量;
37、whc,wzc,bc分别是候选状态的权重矩阵、隐藏状态的权重矩阵和偏置向量;
38、σ(·)表示sigmoid函数,tanh(·)表示双曲正切函数,⊙表示逐元素乘法操作;
39、最终得到两个论元的表征如下:
40、
41、作为一种优选方案,所述仿照人类理解论元关系的过程,对论元间词汇两两配对计算细粒度线索分数,构建得到细粒度多角度线索矩阵的步骤包括:
42、按下式计算细粒度线索分数:
43、
44、式中,为打分的目标词对,部分为词对在这一角度对比时所得线索分数,m为对比参数,为词对在这一角度下综合所得线索分数,v为综合参数,b为偏差向量,f为线索分数计算函数;
45、模拟人类从k个角度理解的过程,给出多角度下细粒度线索分数计算表达式如下:
46、
47、式中,μt∈rk是多角度的综合分数;
48、据此得到细粒度多角度线索矩阵如下:
49、
50、作为一种优选方案,所述抽取对当前关系有用的线索特征进行篇章关系的类别判定的步骤,将得到的细粒度多角度线索矩阵视作为黑白图片,按下式使用卷积神经网络抽取特征:
51、u=max(relu(conv1(g)))
52、u=max(relu(conv2(g)))
53、u=max(relu(conv3(g)))
54、c=flatten(u)
55、式中,c是从矩阵中抽取出的有助于判定当前类别的线索。
56、作为一种优选方案,所述结合整体语义与对当前关系有用的线索特征联合判断关系类别,通过将线索特征与整句语义综合,获取到综合表征,输出隐式篇章关系类别的计算表达式如下:
57、s=mc[a1;a2]
58、g=sigmoid(wgc+uss+bf)
59、v=g*c+(1-g)s
60、o=softmax(wo*v+bo)
61、式中,mc是映射矩阵,用于将论元表征投影到相同维度,s为投影后向量,通过s和c加权求和得到最后的融合线索与整句信息的综合表征v,之后使用softmax函数输出概率分布得到判别出的关系。
62、作为一种优选方案,还包括对模型使用交叉熵作为损失函数进行训练,损失函数的计算表达式如下:
63、
64、其中,c表示类别的个数,y是一个长度为c的向量,表示真实标签的概率分布,每个元素的取值为0或1,表示样本属于对应类别或不属于对应类别;是一个长度为c的向量,表示模型的预测结果的概率分布,每个元素的取值为0到1之间的实数,表示样本属于对应类别的概率;通过对所有类别的差异性进行求和,量化模型预测结果与真实标签之间的差异。
65、第二方面,提供一种文本隐式篇章关系识别系统,包括:
66、论元信息融合模块,用于将论元拼接作为输入,使用roberta预训练模型进行编码,在外部知识融合时使用k-bert模型引入知识图谱信息辅助理解论元内实体,之后对两个论元的语义向量进行拆分,使用bi-lstm模型获取包含更多序列信息的各论元整体表示,得到融合了外部信息的论元;
67、线索特征抽取模块,用于仿照人类理解论元关系的过程,对论元间词汇两两配对计算细粒度线索分数,构建得到细粒度多角度线索矩阵,抽取对当前关系有用的线索特征进行篇章关系的类别判定;
68、关系类别输出模块,结合整体语义与对当前关系有用的线索特征联合判断关系类别,通过将线索特征与整句语义综合,获取到综合表征,输出隐式篇章关系类别。
69、第三方面,提供一种电子设备,包括:存储器,存储至少一个指令;及处理器,执行所述存储器中存储的指令以实现所述的文本隐式篇章关系识别方法。
70、第四方面,提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述的文本隐式篇章关系识别方法。
71、相较于现有技术,本发明至少具有如下的有益效果:
72、在输入构建时,为了建模论元间深层次交互信息从而获取上下文语义,本发明将论元拼接作为输入,同时使用roberta模型进行编码,在外部知识融合时使用k-bert模型引入知识图谱信息辅助理解论元内实体,之后对两个论元的语义向量进行拆分,再使用bi-lstm模型获取进一步论元表征,进而在表征阶段得到融合了外部信息的论元。针对教育领域文本复杂的问题,本发明仿照人类理解论元关系的过程,对论元间词汇两两配对计算细粒度线索分数,构建得到细粒度多角度线索矩阵,抽取对当前关系有用的线索特征进行篇章关系的类别判定;在获取到有助于类别判定的线索后,结合整体论元协同判定隐式篇章关系输出。本发明通过外部知识融合解决了在教育领域文本上存在的专业名词表征困难问题,通过使用教育领域文本抽取三元组,使模型更好地理解专业名词,从而使模型在教育领域文本理解上有更好的表现。并且通过细粒度多角度模块对论元实现词对间交互,通过对词对细粒度关系的发掘,得到更深层次的论元交互表征结果,可以更好地对含义复杂的论元进行判别。最终实现在通用领域取得较好性能效果且教育领域数据集效果优于已有隐式篇章关系识别算法。
- 还没有人留言评论。精彩留言会获得点赞!