一种基于消融的大模型示例选择方法与流程
本发明涉及大规模语言模型,特别是涉及一种基于消融的大模型示例选择方法。
背景技术:
1、现有的大规模语言模型具有很令人吃惊的in-context learning (icl) 能力,即通过几个相似问题的回答示例(人工标注后的),就可以学习人类的行文特色或者思考方式,在大模型从未学习过的任务上获得一定的表现。但是,一般icl中,输入到模型的示例是在已有标注数据中人工选择出来的,对任意测试样本都是一样的。这很明显限制了大模型的icl表现。所以,我们需要对不同的测试样本,在已有标注数据中找到合适的示例数据,帮助大模型在回复用户问题时获得更优的表现。因此,设计一种基于消融的大模型示例选择方法是十分有必要的。
技术实现思路
1、本发明的目的是提供一种基于消融的大模型示例选择方法,能够在已有的数据库中获取合适的示例,帮助大模型生成更好的回复。
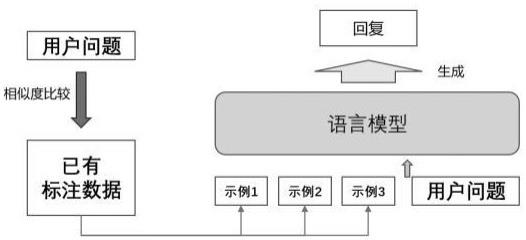
2、一种基于消融的大模型示例选择方法,包括如下步骤:
3、步骤1:搭建用户问题表征模型,并基于数据库对其进行训练;
4、步骤2:通过训练后的用户问题表征模型获取用户问题相关的示例;
5、步骤3:搭建第一语言模型及第二语言模型,并将用户问题及相关的示例输入第一语言模型中。
6、可选的,步骤1中,搭建用户问题表征模型,并基于数据库对其进行训练,具体为:
7、搭建用户问题表征模型m,从数据库中获取训练样本(,),其中,为训练样本的用户问题,为训练样本的问题答案,通过倒排索引,根据训练样本的问题答案在数据库中搜索得到一组候选示例集(,),对候选示例集(,)进行打分,获取前k个评分的示例集(,),将(,)作为正样例,获取评分为到的示例集(,),将(,)作为负样例,对每个训练样本均进行操作,通过每个训练样本得到的正样例及负样例对用户问题表征模型进行训练。
8、可选的,对候选示例集(,)进行打分,具体为:
9、通过 对每组候选示例集(,)进行打分,得到第一次排序,其中,是似然函数得分;
10、选取第一次排序中与(,)相邻的两个示例,记为(,), 和 (,),对其进行分数评估:
11、
12、得到所有候选示例集的评分。
13、可选的,步骤2中,通过训练后的用户问题表征模型获取用户问题相关的示例,具体为:
14、将用户问题输入训练后的用户问题表征模型中,得到相关的示例集,将示例集的问题以及用户问题表征为向量,计算其余弦相似度,获取相似度最高的前个示例集的问题,得到个与用户问题相关的示例。
15、可选的,步骤3中,搭建第一语言模型及第二语言模型,并将用户问题及相关的示例输入第一语言模型中,具体为:
16、搭建第一语言模型及第二语言模型,其中将用户问题及相关的示例输入第一语言模型,生成回复,第二语言模型用于计算候选示例集的似然函数得分。
17、根据本发明提供的具体实施例,本发明公开了以下技术效果:本发明提供的基于消融的大模型示例选择方法,该方法包括搭建用户问题表征模型,并基于数据库对其进行训练,通过训练后的用户问题表征模型获取用户问题相关的示例,搭建第一语言模型及第二语言模型,并将用户问题及相关的示例输入第一语言模型中,能够从已有的数据库中找出与用户问题相关的示例,并将其一同输入语言模型中,作为辅助资料,帮助语言模型生成更好的回复,提高了回复准确性。
技术特征:
1.一种基于消融的大模型示例选择方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的基于消融的大模型示例选择方法,其特征在于,步骤1中,搭建用户问题表征模型,并基于数据库对其进行训练,具体为:
3.根据权利要求2所述的基于消融的大模型示例选择方法,其特征在于,对候选示例集(,)进行打分,具体为:
4.根据权利要求3所述的基于消融的大模型示例选择方法,其特征在于,步骤2中,通过训练后的用户问题表征模型获取用户问题相关的示例,具体为:
5.根据权利要求4所述的基于消融的大模型示例选择方法,其特征在于,步骤3中,搭建第一语言模型及第二语言模型,并将用户问题及相关的示例输入第一语言模型中,具体为:
技术总结
本发明提供了一种基于消融的大模型示例选择方法,包括:搭建用户问题表征模型,并基于数据库对其进行训练,通过训练后的用户问题表征模型获取用户问题相关的示例,搭建第一语言模型及第二语言模型,并将用户问题及相关的示例输入第一语言模型中。本发明提供的基于消融的大模型示例选择方法,能够在已有的数据库中获取合适的示例,帮助大模型生成更好的回复。
技术研发人员:游世学,郭锐,王丙栋,乔亚飞,徐峰
受保护的技术使用者:北京中科汇联科技股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!