基于原型类中心的弱监督开放词汇语义分割方法及系统
本发明涉及计算机视觉和图像处理的,具体地,涉及基于原型类中心的弱监督开放词汇语义分割方法及系统。
背景技术:
1、语义分割是计算机视觉中的一个基本任务,涉及将图像分割成一些语义上有意义的区域。虽然已经取得了很大的进展,但现有的研究主要集中在封闭集情景下,即在训练和推理阶段内,对象类别保持不变的情况下。这种假设过于简单化了实际情况,限制了其实际应用。另一个问题是语义分割严重依赖于像素级别的图像语义标签标注,这种标注需要大量的人力和物力。因此一些研究考虑了一个更具挑战性的问题,需要视觉系统仅用类别标签处理更广泛的类别范围,包括推理过程中的新颖(未见过)类别。这个问题被称为弱监督开放词汇语义分割。
2、为了解决这个问题,视觉-语言预训练范式提供了一个初步但流行的想法。通过利用语言作为视觉识别的内部表示,并结合视觉特征和文本特征的交叉注意力图生成最终的分割图分割被定制类别。
3、专利文献cn116612281a(申请号:cn202310570960.0)公开了一种基于文本监督的开放词汇图像语义分割系统。该方法包括如下步骤:利用图像编码器对图像特征进行提取,同时使用可学习的类别中心对图像进行聚类;利用上亿数据训练得到的文本编码器针对图像描述进行编码,建立与群组表征的对齐关系;跨模态解码器使用交叉注意力机制将群组表征与屏蔽描述表征进行交互融合;所述学习优化模块,使得模型在仅使用文本监督条件下学习视觉-文本对齐,得到优化分割的网络模型。
4、专利文献cn116189190a(申请号:202310189395.3)公开了一种基于零样本学习的多类别零标签图像语义分割方法,s1对采集的多个图像样本进行预处理,消除未见过类别图像样本的干扰特征,得到像素级特征图;s2获取可见类别图像样本的文本信息,提取所述文本信息的语义特征;s3将所述像素级特征图和所述语义特征训练嵌入隐空间,并设置约束和损失函数对所述隐空间进行训练学习;s4对所述未见过类别图像样本进行s1、s2和s3步骤操作,并对图像样本进行逐像素的语义分类,完成零标签语义分割。
5、专利文献cn115761235a(申请号:202211472238.5)公开了一种基于知识蒸馏的零样本语义分割方法、系统、设备及介质,包括:利用预训练的图片编码器提取训练图片中各类的区域图片特征,将其作为语义分割模型提取得到的图片特征图的视觉监督,将图片编码器中的视觉知识蒸馏运用到语义分割模型的训练中;利用预训练的文本编码器提取转化成文本的类别名的文本特征,将其作为语义分割模型特征图的分类依据;语义分割模型根据每类的得分对图片的每个像素点进行分类。
6、专利文献cn115424014a(申请号:202210879677.1)公开了一种基于语义注意力机制的零样本语义分割方法。该方法包括如下步骤:通过背景提取模块提取背景掩码,将背景掩码与初始背景特征一起输入到背景更新模块中,输出学习得到的背景语义特征。通过像素特征提取模块得到语义注意力图和视觉特征图,利用语义特征图和语义注意力图得到适用于当前图片的语义特征,最后计算语义特征和视觉特征图的余弦相似度,根据最大的相似度实现语义分割。
7、但在现实世界的情况下,上述大部分现有技术都保持了一个成本高的假设,即仍需要获取像素级别的图像标注。现有技术研究仅利用文本标注的开放视觉系统需要依赖于用上亿数据规模进行训练,进一步增加了训练成本开销,并且通过引入可学习类中心生成分割图的方式缺少一定的正则引导。因此,存在三个主要问题。
8、第一,无像素级别标注情况下仅通过视觉编码器的内部聚类生成的分割图较为粗糙,无法到达精细的分割效果。第二,借助超大规模图像文本数据训练需要花费大量的训练成本,增加了视觉系统的训练成本。第三,用于内部聚类的可学习类中心缺少明确的监督方式,导致可学习类中心无法得到一定的引导。
9、因此,需要提出一种新的技术方案以改善上述技术问题。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种基于原型类中心的弱监督开放词汇语义分割方法及系统。
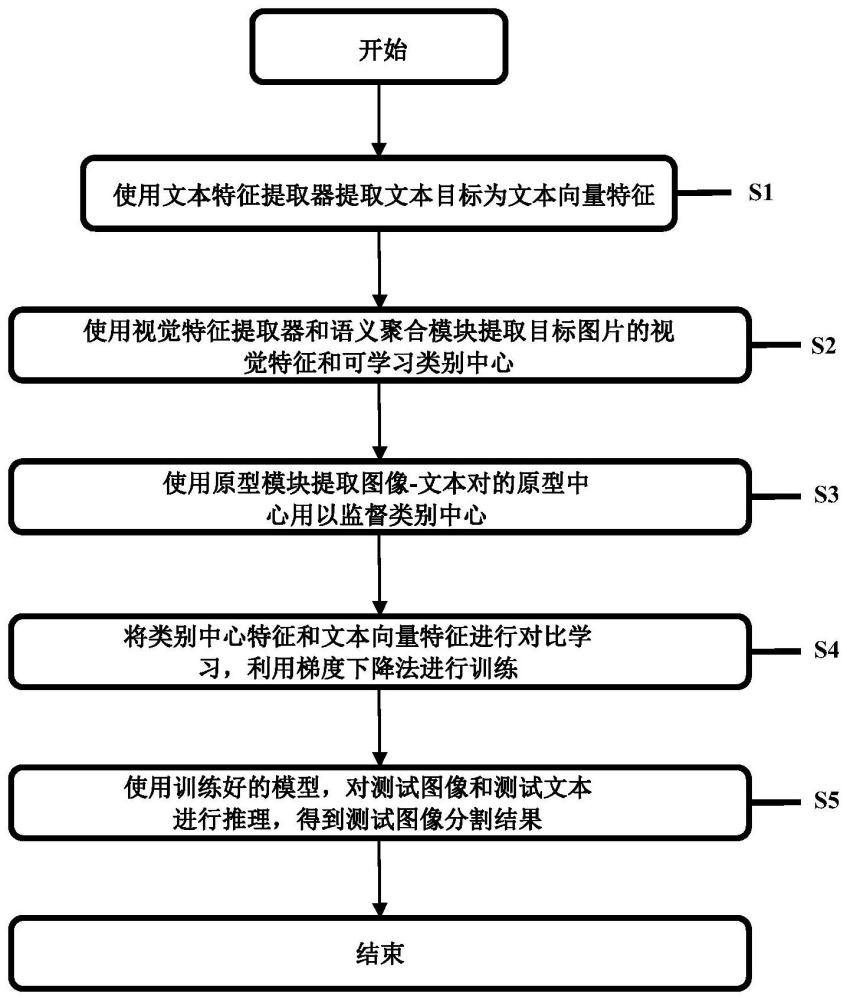
2、根据本发明提供的一种基于原型类中心的弱监督开放词汇语义分割方法,包括:
3、步骤s1:利用文本特征提取器提取文本目标为文本向量特征;
4、步骤s2:利用视觉特征提取器提取目标图片的视觉特征,并将视觉特征基于可学习类别中心进行聚类操作得到全局类别中心;
5、步骤s3:利用原型模型提取图像-文本对的原型类别中心用以监督全局类别中心;
6、步骤s4:将全局类别中心和文本向量特征进行对比学习,利用梯度下降法对文本特征提取器和视觉特征提取器进行训练;
7、步骤s5:利用训练好的文本特征提取器和视觉特征提取器对测试图像和测试文本进行推理得到测试图像分割结果;
8、所述原型模型是基于高斯混合模型通过融合底层图像和文本得到原型类别中心,从而共同监督可学习类别中心,增强类别中心的特征聚合能力,从而产生更好的待分割物体的特征描述。
9、优选地,所述步骤s1采用:
10、步骤s1.1:将文本t通过令牌解析器转化为长度为k的文本嵌入向量,t∈rk×c,其中,c代表文本向量特征维度;r表示实数空间;
11、步骤s1.2:将解析后的文本嵌入向量输入文本自注意力模型得到文本特征向量t∈r1×d;其中,d表示文本特征向量的向量特征维度。
12、优选地,所述步骤s2采用:
13、步骤s2.1:将图片x∈rh×w×3切成p×p的2d切片,每个切片输入卷积神经网络或多层感知器中得到总共p×p个通道数为d的特征,表示实数域;h表示图片的高度;w表示图片的宽度;
14、步骤s2.2:将p×p个通道数为d的特征与位置编码相加得到新图像的特征vo;
15、步骤s2.3:引入g个可学习类别中心,将和新图像特征vo∈rnv×d整合在一起形成新的整合图像输入特征;
16、步骤s2.4:将新的整合图像输入特征输入视觉自注意力模型得到目标图片编码的视觉特征其中,nv是图片的切片数量;
17、步骤s2.5:将目标图片编码的视觉特征输入语义聚合模块进行聚类操作得到由类中心学习到的全局类中心特征vg∈rg×d,其中,g是可学习的类别中心的数量。
18、优选地,所述步骤s3采用:
19、步骤s3.1:将新图像的特征vo通过原型模型输出视觉原型类别中心vi∈rg×d,其中,g是视觉原型类别中心的数量;
20、步骤s3.2:将文本特征向量t通过原型模型输出文本原型类别中心vt∈rg×d,其中,g是文本原型类别中心的数量;
21、步骤s3.3:将视觉原型类别中心和文本语原型类别中心分别对齐全局可学习类别中心vg∈rg×d,形成对可学习类别中心的多模态监督目标,分别得到损失函数lv(vg,vi)和lt(vg,vt)。
22、优选地,所述步骤s4采用:
23、步骤s4.1:将全局类别中心vg∈rg×d先后通过池化层和线性层映射成最终的视觉特征向量vf∈r1×d;
24、步骤s4.2:将得到的视觉特征向量vf∈r1×d和文本特征向量t∈r1×d通过对比学习的方式对齐得到损失函数lc(vf,t);
25、步骤s4.3:将所有的损失函数加和得到最终的用于网络训练的损失函数lall=lc(vf,t)+lv(vg,vi)+lt(vg,vt),使用梯度下降法对lall进行更新。
26、优选地,所述步骤s5采用:
27、步骤s5.1:将测试图像通过训练后的视觉特征提取器后,再通过语义聚合模块进行聚类操作得到特征it=crossattn(q=vg,k=vo,v=vo)+vg;
28、步骤s5.2:将测试文本输入训练后的文本特征提取器得到类别文本特征向量tt∈rk×d,其中,k代表测试类别数目;
29、步骤s5.3:求得可学习类别中心vg和测试文本特征向量tt∈rk×d的余弦相似度,选择it中对应相似度最大的类别标签生成最终分割图,并使用阈值法将其转化为最终结果。
30、根据本发明提供的一种基于原型类中心的弱监督开放词汇语义分割系统,包括:
31、模块m1:利用文本特征提取器提取文本目标为文本向量特征;
32、模块m2:利用视觉特征提取器提取目标图片的视觉特征,并将视觉特征基于可学习类别中心进行聚类操作得到全局类别中心;
33、模块m3:利用原型模型提取图像-文本对的原型类别中心用以监督全局类别中心;
34、模块m4:将全局类别中心和文本向量特征进行对比学习,利用梯度下降法对文本特征提取器和视觉特征提取器进行训练;
35、模块m5:利用训练好的文本特征提取器和视觉特征提取器对测试图像和测试文本进行推理得到测试图像分割结果;
36、所述原型模型是基于高斯混合模型通过融合底层图像和文本得到原型类别中心,从而共同监督可学习类别中心,增强类别中心的特征聚合能力,从而产生更好的待分割物体的特征描述。
37、优选地,所述模块m1采用:
38、模块m1.1:将文本t通过令牌解析器转化为长度为k的文本嵌入向量,t∈rk×c,其中,c代表文本向量特征维度;r表示实数空间;
39、模块m1.2:将解析后的文本嵌入向量输入文本自注意力模型得到文本特征向量t∈r1×d;其中,d表示文本特征向量的向量特征维度;
40、所述模块m2采用:
41、模块m2.1:将图片x∈rh×w×3切成p×p的2d切片,每个切片输入卷积神经网络或多层感知器中得到总共p×p个通道数为d的特征,表示实数域;h表示图片的高度;w表示图片的宽度;
42、模块m2.2:将p×p个通道数为d的特征与位置编码e={e1,e2,…,ep2}相加得到新图像的特征vo;
43、模块m2.3:引入g个可学习类别中心,将和新图像特征vo∈rnv×d整合在一起形成新的整合图像输入特征;
44、模块m2.4:将新的整合图像输入特征输入视觉自注意力模型得到目标图片编码的视觉特征其中,nv是图片的切片数量;
45、模块m2.5:将目标图片编码的视觉特征输入语义聚合模块进行聚类操作得到由类中心学习到的全局类中心特征vg∈rg×d,其中,g是可学习的类别中心的数量。
46、优选地,所述模块m3采用:
47、模块m3.1:将新图像的特征vo通过原型模型输出视觉原型类别中心vi∈rg×d,其中,g是视觉原型类别中心的数量;
48、模块m3.2:将文本特征向量t通过原型模型输出文本原型类别中心vt∈rg×d,其中,g是文本原型类别中心的数量;
49、模块m3.3:将视觉原型类别中心和文本语原型类别中心分别对齐全局可学习类别中心vg∈rg×d,形成对可学习类别中心的多模态监督目标,分别得到损失函数lv(vg,vi)和lt(vg,vt);
50、所述模块m4采用:
51、模块m4.1:将全局类别中心vg∈rg×d先后通过池化层和线性层映射成最终的视觉特征向量vf∈r1×d;
52、模块m4.2:将得到的视觉特征向量vf∈r1×d和文本特征向量t∈r1×d通过对比学习的方式对齐得到损失函数lc(vf,t);
53、模块m4.3:将所有的损失函数加和得到最终的用于网络训练的损失函数lall=lc(vf,t)+lv(vg,vi)+lt(vg,vt),使用梯度下降法对lall进行更新。
54、优选地,所述模块m5采用:
55、模块m5.1:将测试图像通过训练后的视觉特征提取器后,再通过语义聚合模块进行聚类操作得到特征it=grossattn(q=vg,k=vo,v=vo)+vg;
56、模块m5.2:将测试文本输入训练后的文本特征提取器得到类别文本特征向量tt∈rk×d,其中,k代表测试类别数目;
57、模块m5.3:求得可学习类别中心vg和测试文本特征向量tt∈rk×d的余弦相似度,选择it中对应相似度最大的类别标签生成最终分割图,并使用阈值法将其转化为最终结果。
58、与现有技术相比,本发明具有如下的有益效果:
59、1、本发明针对弱监督开放词汇语义分割,精心设计了一种基于原型类学习策略的框架,具体的,通过利用图像和文本低维特征进行聚类得到对可学习类中心的有效标签,促使最终框架产生更完整、更准确的分割结果;
60、2、本发明通过从低维特征提取有效原型类中心,解决了现有技术对于可学习类中心无正则引导的问题,实现了更精确的开放词汇语义分割;具体的,本发明引入高斯混合模型,利用图像的纹理特征的语义特征,可以增强可学习类中心对分割细节的捕捉能力,达到完备性对语义可辨识性;
61、3、通过从文本原型类中心监督可学习类别中心,本发明提高了对于不在视觉-语言预训练的词典中出现的词汇从而导致的粗糙分割的现象,实现了更鲁棒的开放词汇语义分割;具体的,本发明通过利用已有的多模态知识,增强模型对图像的语义理解;
62、4、本发明精心设计了基于原型知识的语义聚合模块,通过将原型类中心和可学习的类中心进行一比一的对齐操作,同时增强了可学习类中心的对图像纹理细节和语义信息捕捉能力,实现了更为精细准确的分割效果;
63、5、对于新的类别的图像,本发明通过利用文本原型类中心监督可学习类中心,增强对新语义的理解,实现更为精准的开放的语义分割;
64、6、通过对可学习类中心的有效监督信号研究,本发明增强了可学习类中心聚类过程的可解释性,实现了更为合理的语义分割效果;
65、7、由于基于可学习类别聚类方式聚合图像可能包含层次结构,为了更精准的利用这一点潜力,本发明通过一种层次聚合架构,设计了一种聚合模块对不同层次的属性进行聚合,实现了更加有效,精准的聚合效果。
- 还没有人留言评论。精彩留言会获得点赞!