一种基于多模态案例知识图的生产业务流程剩余时间预测方法
本发明属于业务流程管理,涉及业务流程的剩余时间预测方法。
背景技术:
1、在现代制造业中,有效的生产业务流程管理对于提高生产效率、降低成本以及优化资源利用至关重要。然而,由于生产环境的复杂性和不确定性,准确预测生产业务流程的剩余时间成为一个充满挑战的问题。在传统的生产业务流程中,涉及多种资源、设备、人员和环境因素,因此生产业务流程的实际执行时间往往与预期存在差异。这种差异可能导致生产计划的不准确性,进而影响交付时间、资源规划和成本控制等方面。生产业务流程剩余时间预测有助于制造企业更好地优化生产业务流程,提前做出调整以应对可能的延迟或变动。同时,准确的剩余时间预测有助于改善生产计划的制定,确保交付时间的可靠性,并支持更有效的资源分配和成本管理。
2、传统的知识图谱是一种结构化的知识表示方法,它通过三元组构建图结构,能够综合整合多源信息、支持复杂的关联分析和推理,实时动态更新以及不确定性建模。这种方法有助于为预测模型提供全面的上下文背景,从而提高预测的准确性。然而,在生产业务流程中,涉及到多种数据模态,例如生产业务流程图信息和日志记录的文本信息。与此同时,生产业务流程通常以案例的形式存在,而传统的知识图谱难以适应案例之间的动态变化。此外,生产业务中的许多活动是重复出现的,进一步增加了知识图谱建模的复杂性。因此,迫切需要一种新型的知识图谱,它能够融合多模态数据,并能够根据案例的顺序动态建模实体之间的关系。这类知识图谱要能够记录事件随着案例的发生顺序而变化的情况,支持时间上的推理和预测。这将有助于更好地应对生产业务流程中的时间动态性和多模态数据特点,从而更准确地预测流程的剩余时间。
技术实现思路
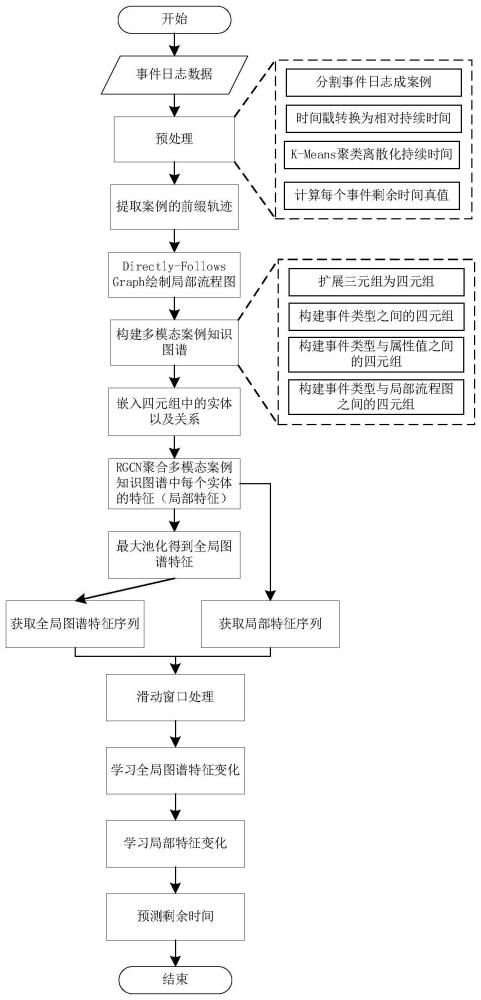
1、为了能够结合生产业务流程的多模态数据来准确预测现代制造业中复杂生产业务流程的剩余时间,本发明提出一种基于多模态案例知识图的生产业务流程剩余时间预测方法。首先,预处理日志信息,对日志数据进行案例划分,抽取额外的流程图模态信息;然后将多模态案例知识呈现为带有案例信息的节点(实体),形成多关系有向图的结构;接着使用关系图卷积网络(relation graph convolutional networks,rgcn)作为领域聚合器来聚合同一案例的事件信息;最后引入transformer的事件编码器汇总过去事件序列的信息用于预测剩余时间。
2、一种基于多模态案例知识图的生产业务流程剩余时间预测方法,包括以下步骤:
3、(1)预处理事件日志数据,包括分割事件日志成案例、将时间戳转换为相对持续时间、通过k-means聚类离散化时间间隔,并计算每个事件的剩余时间真值。
4、(2)局部流程图的提取和绘制。从事件日志中提取前缀轨迹,将其转化为directly-follows graph来表示事件间的直接关系,然后绘制局部流程图,以图像模态展示事件顺序。
5、(3)构建多模态案例知识图谱。在这个图中,案例的所有信息和局部流程图被表示为节点,而通过扩展原始三元组为四元组的方式来定义这些关系,从而实现了更丰富的信息表示。
6、(4)嵌入四元组中的不同实体(包括事件类型实体、不同属性类型的实体和局部流程图实体)以及关系。首先,本发明构建了独立的嵌入矩阵,分别用于事件类型和不同属性类型的实体,以确保它们在嵌入空间中具有独特的表示。这些嵌入矩阵的训练使本发明能够将各个实体映射到嵌入向量空间。对于关系,本发明建立了一个独立的嵌入矩阵,用于明确表示不同关系的特征。对于局部流程图实体,本发明采用卷积神经网络(cnn)的方法进行处理。这包括使用卷积层提取特征图,以捕获局部区域的相关信息,然后通过池化层来减小特征图的尺寸,同时保留关键特征。随后,本发明将这些特征图展平为一维向量,并通过全连接层进一步处理,最终得到局部流程图实体的嵌入向量。
7、(5)采用多关系图卷积网络(rgcn)来聚合多模态案例知识图谱中每个实体的特征,其中步骤(4)中获得的嵌入向量被用作初始嵌入。这种网络结构能够通过多层神经网络来聚合不同实体之间的关系,以获得更丰富的表示。以下是详细的聚合过程的方法:
8、对于每个实体s在案例c的图谱中,本发明通过以下公式来计算聚合后的特征:
9、
10、其中,表示案例c对应的图谱中实体s的特征;r是所有关系的集合;表示在案例c中头实体s在关系r的邻居集合;cs是一个正则化常量;是第l聚合层关系r的权重矩阵;是第l聚合层的权重矩阵;和在l=0时被设置为步骤(4)得到的初始嵌入向量。在公式中,本发明使用了多层神经网络来收集多跳邻居的特征,并结合权重矩阵进行线性变换。最后的结果通过激活函数σ进行非线性映射。为了获得案例c的全局图谱特征g(gc),对案例c中所有实体的特征进行最大池化作为表示整个案例c的图谱特征。
11、(6)学习全局图谱特征序列和局部节点特征序列的变化过程,根据学习到的局部节点特征变化过程对处在新案例下的事件的剩余时间进行预测。
12、进一步,步骤(1)由以下步骤组成:
13、(1.1)分割事件日志案例。将事件日志按案例进行分割,并确保每个案例中的事件按执行顺序排列,每个案例代表一个完整的业务流程。
14、(1.2)转换时间戳为持续时间。将每个案例中的时间戳转换为持续时间,即计算每个事件相对于案例开始时间的时间间隔。这个转换消除了绝对时间的影响,而只保留了事件之间的相对时间关系。这是为了在分析中关注事件之间的时间间隔,而不受实际时间点的影响。
15、(1.3)应用k-means聚类算法离散化持续时间。使用k-means聚类算法对转换后的持续时间数据进行聚类。这个步骤旨在将相似的持续时间归类到同一类别中。这种聚类有助于将持续时间离散化,将相似的时间间隔划分为不同的时间区间。
16、(1.4)计算剩余时间真值。为每个事件计算其与案例结束时间点之间的剩余时间,即事件的剩余时间真值。这表示了从当前事件发生时刻到整个案例结束的时间间隔,为后续预测剩余时间提供真实值。离散化的时间聚类结果和每个事件的剩余时间真值将保存以备后续分析和计算使用。
17、进一步,所述的步骤(2)由以下步骤组成:
18、(2.1)对于每个案例,从事件日志中提取前缀轨迹。前缀轨迹指的是从案例开始直到特定事件的一系列事件序列。这意味着,对于每个事件日志中的案例,从开头到案例中的每个事件,都可以形成一个前缀轨迹。
19、(2.2)将这些前缀轨迹转换为directly-follows graph(直接跟随图)。这是一种图结构,用于表示事件之间的直接关系。在这个图中,每个事件被表示为一个节点,而有向边则表示事件之间的顺序关系。如果事件a直接跟随事件b,那么就会有一条从节点b指向节点a的有向边。这种表示方式能够清晰地展示事件之间的顺序结构。
20、(2.3)绘制局部流程图。为了绘制这样的局部流程图,可以利用现有的工具和库,比如pm4py库中提供的directly-follows graph方法。该方法可以帮助将前缀轨迹转换为图像,其中节点代表事件,有向边表示事件之间的直接跟随关系。通过图像这种模态,可以更直观地观察和分析事件之间的流程演变。
21、进一步,所述的步骤(3)由以下步骤组成:
22、(3.1)扩展三元组为四元组。将传统的三元组(头实体,关系,尾实体)扩展为四元组(头实体,关系,尾实体,案例)。新加入的“案例”表示一个附加维度,表示所属于的案例,用于将图谱按照案例来分割和排序。
23、(3.2)构建事件类型之间的四元组。本发明将事件的不同类型都定义为一种实体。这些事件类型以及它们之间的关系被称为“下一事件”。以案例c为例,如果“事件类型1”直接后续“事件类型2”,本发明将这个关系表示为“下一事件”。这会形成一个四元组(s,r,o,c),其中s表示“事件类型1”,r表示关系“下一事件”,o表示“事件类型2”,而c表示所属的“案例c”。
24、(3.3)构建事件类型与属性值之间的四元组。本发明将事件的属性值也定义为实体。事件的属性名称则被视为一种关系。以案例c为例,如果事件类型1与事件资源1相关联,这会形成一个四元组(s,r,o,c),其中s表示“事件类型1”,r表示关系“事件资源名”,o表示“事件资源1”,而c表示所属的“案例c”。
25、(3.4)构建事件类型与局部流程图之间的四元组。局部流程图也被定义为一种实体。与局部流程图相关的关系被定义为“对应局部流程图”。在四元组(s,r,o,c)中,s代表事件类型实体,r表示关系“对应局部流程图”,o代表局部流程图,而c表示所属的案例c。
26、进一步,所述的步骤(6)由以下步骤组成:
27、(6.1)获取全局图谱特征序列。将从初始案例s到最终案例e的全局图谱特征序列表示为<g(gs),……,g(ge)>,这些特征是对整个图谱的汇总表示。
28、(6.2)获取局部特征序列。对每个节点<1,2,……,n>,将从初始案例s到最终案例e的局部特征序列表示为多个序列,如:
29、
30、(6.3)滑动窗口处理。由于事件日志包含了大量案例,这导致了特征序列变得非常长,难以完全输入到模型进行训练。此外,通常来说,预测任务不需要过于久远的历史信息。因此,本发明采用滑动窗口的方式来限制全局图谱特征序列和局部特征序列的长度。在滑动窗口尚未达到最大容量k之前,本发明会使用零向量进行填充。
31、(6.4)学习全局图谱特征变化。将案例c之前的窗口中的全局图谱特征序列输入transformer的编码器,以学习案例c之前全局图谱特征的变化过程hc,可以表示为:
32、hc=transformerencoder1(<g(gc-(k-1)),……,g(gc)>) 公式(2)
33、其中<g(gc-(k-1)),……,g(gc)>表示输入的序,transformerencoder1是一个transformer编码器。transformer编码器由多层编码器组成,每一层都包括两个主要组件:自注意力机制和前馈神经网络。自注意力机制用于计算一组键与查询的加权和,以生成自注意力输出。通常,每个编码器层包含多个独立的自注意力头部,它们分别计算自注意力输出,然后将这些头部的结果拼接在一起,并通过一个权重矩阵进行加权组合。在自注意力计算之后,还存在一个前馈神经网络,用于对多头自注意力输出进行非线性变换。
34、(6.5)学习局部实体特征变化。首先,针对实体n,提取在以案例c为结尾的窗口中的局部特征序列和已经学习到的全局序列<hc-(k-1),……,hc>。接着,将这两个序列拼接起来,形成一个新的序列最后将其作为输入,学习实体n在案例c之前的局部图谱特征序列变化过程可以表示为:
35、
36、其中,表示输入序列。
37、(6.6)预测剩余时间。若给定案例c+1的前缀轨迹,轨迹的最后为事件类型n,则根据以下公式预测案例的剩余时间(remaining time):
38、
39、其中,表示预测的剩余时间,en表示使用步骤(4)中方法得到的实体“事件类型n”的嵌入,“;”表示拼接,表示步骤(6.5)中得到的实体n在案例c之前的局部图谱特征序列变化过程,w1表示全连接层的权重矩阵。
40、本发明的技术构思是:首先构建一种多模态案例知识图谱,扩展三元组为四元组,并将结构化实体、关系和属性与文本和图像等多模态数据相结合。然后引入多关系图卷积网络来聚合多模态案例知识图谱得到每个实体的特征作为局部特征,多模态案例知识图谱的所有实体特征进行最大池化作为全局特征。最后将按照案例顺序排序的全局特征和局部特征使用transformer编码器来捕获案例和实体状态的动态变化。
41、本发明的优点是:多模态案例知识图谱整合了多种数据模态,包括结构化实体、关系和属性,以事件日志和图像等多模态数据。扩展了知识图谱的能力,使其能够记录实体之间的关系、事件顺序以及实体状态随案例的演变。引入多关系图卷积网络(rgcn)来学习图谱的结构化信息。这种方法增强了图谱分析的能力,使其能够更好地处理复杂的实体关系。采用transformer架构来捕获实体随案例变化的过程,有助于更好地理解案例的多模态信息。
- 还没有人留言评论。精彩留言会获得点赞!