基于大语言模型的知识图谱自动构建查询方法和系统与流程
本发明涉及知识图谱的应用领域,具体涉及基于大语言模型的期货尤其是金融期货的知识图谱自动构建查询方法和系统。
背景技术:
1、以大数据和人工智能为代表的高新技术在金融业的广泛应用,在为金融从业者提供了丰富决策手段的同时,也累积了大量的结构化和非结构化数据。
2、知识图谱,可以打通多元异构数据,解决数据孤岛化的问题。通过将结构化及非结构化数据抽象为结构化的三元组,使用者可以在统一的框架下利用不同数据进行分析。同时,知识图谱可用于凝练和迭代专家知识,其推理能力和判断能力,可用于厘清风险脉络,拆解风险来源,提升对风险的反应能力和处置能力。
3、然而,当前知识图谱的构建和使用仍然面对以下挑战:
4、在构建方面,知识图谱构建过程通常包括:本体构建、数据收集、数据标注、关系抽取、实体消歧等步骤。故而,一张知识图谱的构建成本主要来自于:专家和标注的人力成本,抽取和消歧的算力成本。
5、在使用方面,使用知识图谱时需要和图数据库进行交互。如果选择让业务人员通过图数据库查询语言和图数据库直接交互,会带来对业务人员的教育成本。如果选择让开发人员开发中间层进行交互,会带来额外的开发成本。
6、因此,如何在构建和使用方面,来降本增效,是目前业界亟待解决的问题。
技术实现思路
1、以下给出一个或多个方面的简要概述以提供对这些方面的基本理解。此概述不是所有构想到的方面的详尽综览,并且既非旨在指认出所有方面的关键性或决定性要素亦非试图界定任何或所有方面的范围。其唯一的目的是要以简化形式给出一个或多个方面的一些概念以为稍后给出的更加详细的描述之序。
2、本发明的目的在于解决上述问题,提供了一种基于大语言模型的知识图谱自动构建查询方法和系统,既能降低知识图谱的构建成本,又能降低知识图谱的使用成本。
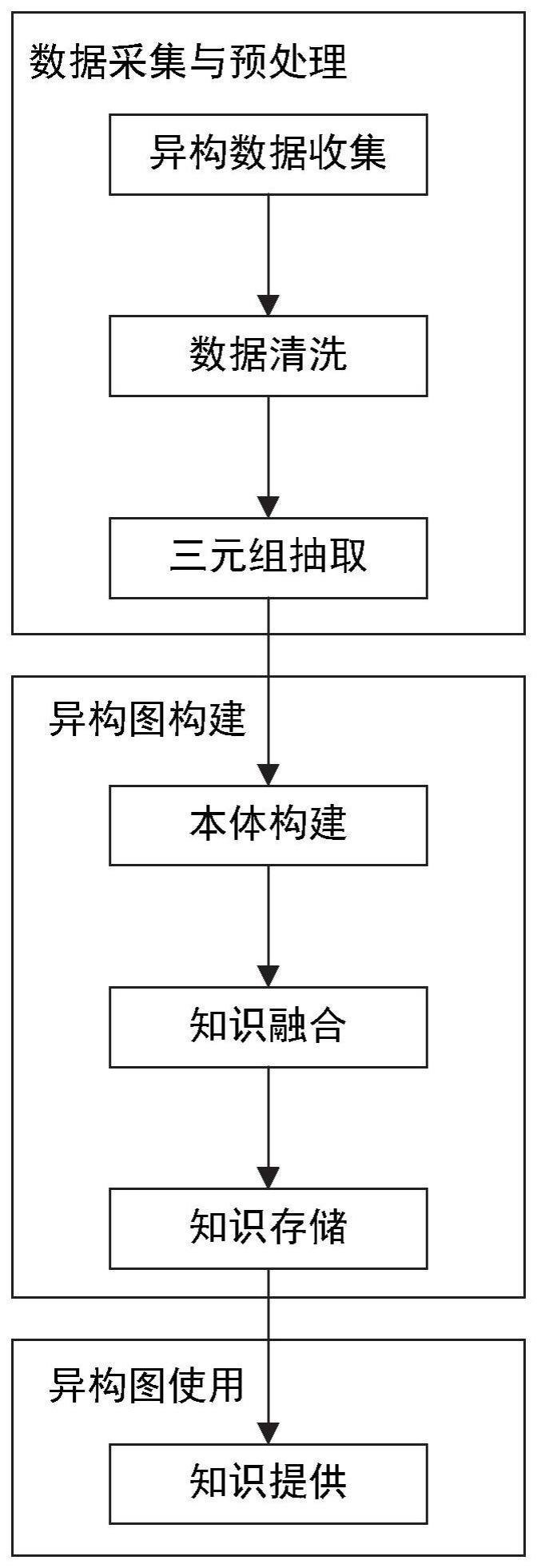
3、本发明的技术方案为:本发明揭示了一种基于大语言模型的知识图谱自动构建查询方法,方法包括:
4、步骤1:采集原始数据并对采集到的原始数据进行预处理;
5、步骤2:基于预处理的数据来构建异构图;
6、步骤3:使用步骤2所构建的异构图以获取查询结果。
7、根据本发明的基于大语言模型的知识图谱自动构建查询方法的一实施例,原始数据分为结构化数据和非结构化数据。
8、根据本发明的基于大语言模型的知识图谱自动构建查询方法的一实施例,步骤1中的结构化数据的预处理进一步包括:
9、结构化数据在首次从数据接口接入后,先抽取结构化数据的元数据;
10、再从结构化数据中抽取示例数据,以元数据及其示例数据为提示数据,指示大语言模型构造可能的三元组;
11、最后,对构造出的三元组,经业务修正后通过脚本批量自动构建。
12、根据本发明的基于大语言模型的知识图谱自动构建查询方法的一实施例,步骤1中的非结构化数据的预处理进一步包括:
13、非结构化数据在经过去除格式标签、特殊字符和去重算法的数据清洗后,在提示指引下,非结构化数据采用流式方式输入大语言模型,并返回三元组,其中提示指引是采用思维链模式。
14、根据本发明的基于大语言模型的知识图谱自动构建查询方法的一实施例,步骤2进一步包括:
15、首先,在本体构建时,知识图谱借助自动本体构建工具,采用自顶向下的方式构建;
16、然后,在确定本体后对三元组进行融合入图,其中在融合过程进行实体消歧和共指消解任务,以在文本中识别和区分不同实体,并定位代词所指的实体,其中在进行实体消歧和共指消解时,采用基于注意力机制的模型和大语言模型相结合的方式;
17、最后,在获取相似度和大语言模型建议后,采用加权方式计算出最终相似度,基于计算所得的最终相似度是否超过相似度阈值以获取最终的异构图谱,并存储在图数据库中。
18、根据本发明的基于大语言模型的知识图谱自动构建查询方法的一实施例,基于注意力机制的模型,首先采用双向门控循环单元对词语所在文本进行编码,再通过注意力机制对输入序列中不同位置的信息进行聚焦,最终注意力权重向量与编码器的输出进行加权求和,生成上下文向量即词义表示,对于获取的词义表示,通过余弦相似度进行相似度计算,得到第一相似度;
19、基于大语言模型的相似度判断,首先摘取实体存在的上下文,并构建提示,通过大语言模型得到第二相似度。
20、根据本发明的基于大语言模型的知识图谱自动构建查询方法的一实施例,步骤3进一步包括:
21、在异构图使用时,输入为人类自然语言问句,首先构造提示,再将所输入的问句所构造的提示输入给大语言模型,由大语言模型生成相应查询语句,获取所生成的查询语句后,经自动解析运行后获取到最终的查询结果。
22、本发明还揭示了一种基于大语言模型的知识图谱自动构建查询系统,系统包括:
23、数据采集和预处理模块,采集原始数据并对采集到的原始数据进行预处理;
24、异构图构建模块,基于预处理的数据来构建异构图;
25、异构图使用模块,使用异构图构建模块所构建的异构图以获取查询结果。
26、根据本发明的基于大语言模型的知识图谱自动构建查询系统的一实施例,原始数据分为结构化数据和非结构化数据。
27、根据本发明的基于大语言模型的知识图谱自动构建查询系统的一实施例,数据采集和预处理模块中的结构化数据的预处理进一步配置为:
28、结构化数据在首次从数据接口接入后,先抽取结构化数据的元数据;
29、再从结构化数据中抽取示例数据,以元数据及其示例数据为提示数据,指示大语言模型构造可能的三元组;
30、最后,对构造出的三元组,经业务修正后通过脚本批量自动构建。
31、根据本发明的基于大语言模型的知识图谱自动构建查询系统的一实施例,数据采集和预处理模块中的非结构化数据的预处理进一步包括:
32、非结构化数据在经过去除格式标签、特殊字符和去重算法的数据清洗后,在提示指引下,非结构化数据采用流式方式输入大语言模型,并返回三元组,其中提示指引是采用思维链模式。
33、根据本发明的基于大语言模型的知识图谱自动构建查询系统的一实施例,异构图构建模块进一步配置为:
34、首先,在本体构建时,知识图谱借助自动本体构建工具,采用自顶向下的方式构建;
35、然后,在确定本体后对三元组进行融合入图,其中在融合过程进行实体消歧和共指消解任务,以在文本中识别和区分不同实体,并定位代词所指的实体,其中在进行实体消歧和共指消解时,采用基于注意力机制的模型和大语言模型相结合的方式;
36、最后,在获取相似度和大语言模型建议后,采用加权方式计算出最终相似度,基于计算所得的最终相似度是否超过相似度阈值以获取最终的异构图谱,并存储在图数据库中。
37、根据本发明的基于大语言模型的知识图谱自动构建查询系统的一实施例,基于注意力机制的模型,首先采用双向门控循环单元对词语所在文本进行编码,再通过注意力机制对输入序列中不同位置的信息进行聚焦,最终注意力权重向量与编码器的输出进行加权求和,生成上下文向量即词义表示,对于获取的词义表示,通过余弦相似度进行相似度计算,得到第一相似度;
38、基于大语言模型的相似度判断,首先摘取实体存在的上下文,并构建提示,通过大语言模型得到第二相似度。
39、根据本发明的基于大语言模型的知识图谱自动构建查询系统的一实施例,异构图使用模块进一步配置为:
40、在异构图使用时,输入为人类自然语言问句,首先构造提示,再将所输入的问句所构造的提示输入给大语言模型,由大语言模型生成相应查询语句,获取所生成的查询语句后,经自动解析运行后获取到最终的查询结果。
41、本发明对比现有技术有如下的有益效果:本发明针对构建成本,基于大语言模型(大语言模型是一种通过大规模的训练数据和参数来构建的深度神经网络模型,可以完成回答问题、提供信息、进行对话等任务)的归纳能力可以从海量非结构化数据中抽取实体和三元组;大语言模型的推理能力可以用于本体构建及实体消歧。本发明针对使用成本,基于大语言模型的文本生成能力,将业务人员输入的自然语言转化成机器可以理解的查询语言。
42、具体而言,本发明的技术方案存在以下几方面的创新:
43、1、本发明利用大语言模型替代传统知识图谱中的数据清洗、本体构建工作,通过大语言模型训练中累积的知识和归纳能力,替代专家工作,通过大语言模型的文本理解能力,替代劳动密集的标注工作。
44、2、本发明利用大语言模型的推理能力,辅助加强知识图谱的实体消歧和共指消解工作,增加了知识图谱的可靠性和准确性。
45、3、本发明利用大语言模型的文本生成能力,生成结构化知识图谱查询语句,降低开发和使用成本,提高知识图谱的可用性。
46、4、本发明构建的知识图谱,综合动态舆情信息和静态实体信息,综合流式和跑批更新方法,具有自我更新和修正能力。
- 还没有人留言评论。精彩留言会获得点赞!