一种可解释类深度神经网络条件规则错误定位方法与流程
本技术属于错误定位,特别涉及一种可解释类深度神经网络条件规则错误定位方法。
背景技术:
1、人工智能类的场景决策方法主要包括基于规则的专家系统和基于深度神经网络的自演进机器学习类方法。其中,基于深度神经网络的自演进机器学习类方法主要以深度学习和深度强化学习两种形式为主。深度强化学习一般被形式化为马尔可夫决策过程求解问题,智能体从当前环境获取观测,产生决策动作并与环境进行交互,环境根据智能体的表现反馈奖赏给智能体,智能体收到奖赏后不断修正自己的行为,好的奖赏将会激励智能体继续做出一致行为,相反,则将惩罚智能体使其避免做出类似行为。在深度强化学习中,智能体通过不断地与环境交互,以最大化累积奖赏的方式进行学习和进化,从而获取最优策略。
2、与之类似,空中博弈智能体也可以在仿真环境中通过与乙方不断地自博弈对抗,演化出足以匹敌人类飞行员甚至超越人类顶尖水平的空中博弈技术。深度强化学习通过和空中博弈环境的持续交互,可以开展自我对弈从而生成全新的战术模式,甚至是人类从未见过的全新技术。基于深度强化学习算法训练的空中博弈智能体由于其策略一般由深度神经网络拟合,因此深度强化学习空中博弈算法的工程化落地必须解决一系列关键技术,如现有基于数据驱动的神经网络模型学习,由于数据的不连续性,常常会导致模型脆弱,存在预期外的输出以及容易被攻击等弱点。
3、由于神经网络的黑盒性,很难直接对出现错误的神经网络模型进行错误定位。基于频谱的软件错误定位技术(spectrum-based fault localization,sfl)被认为是一种典型的错误定位技术。程序频谱是记录在执行配置文件中的程序动态信息,其详细地说明了程序运行期间的动态行为。它可用于指示程序的某些组件,例如语句,条件分支和方法,在特定的环境中被执行的情况。大多数情况下在失败的执行中频繁执行的代码比在传递的执行中执行的代码更可疑。换句话说,这些可疑代码几乎就是程序失效的根本原因。通过分析成功和失败运行的程序频谱的差异,sfl可以帮助测试人员定位到在失败测试用例中的可疑代码。然而由于传统的sfl错误定位技术对语句覆盖矩阵内所包含的信息没有充分挖掘,其对于一些程序效果不是很理想。
4、因此,希望有一种技术方案来克服或至少减轻现有技术的至少一个上述缺陷。
技术实现思路
1、本技术的目的是提供了一种可解释类深度神经网络条件规则错误定位方法,以解决现有技术存在的至少一个问题。
2、本技术的技术方案是:
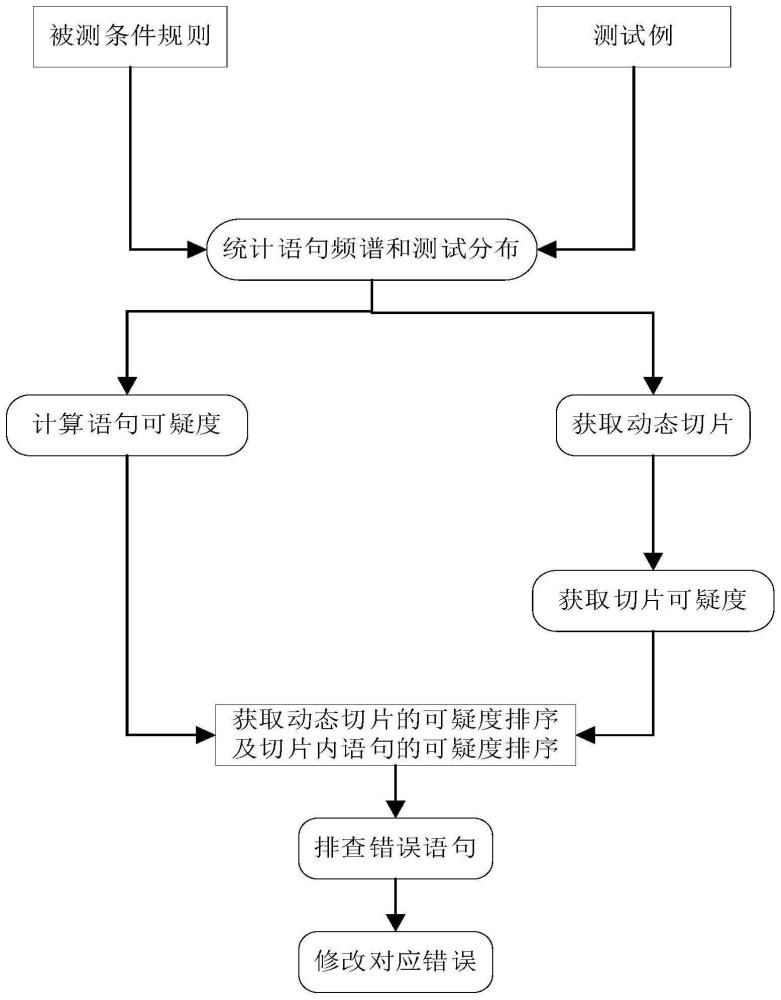
3、一种可解释类深度神经网络条件规则错误定位方法,包括:
4、步骤一、获取条件规则中的所有语句,计算每条语句的可疑度值,并根据语句的可疑度值的大小对所述语句进行排序;
5、步骤二、获取条件规则中的所有失效执行切片,计算每个失效执行切片的动态失效执行块的可疑度值,并根据动态失效执行块的可疑度值的大小对所述失效执行切片进行排序;
6、步骤三、根据所述语句以及所述失效执行切片的排序,逐一排查所述失效执行切片的动态失效执行块中的语句,得到错误语句;
7、步骤四、根据所述错误语句生成补丁规则,并将所述补丁规则前置于可解释类深度神经网络条件规则模型。
8、在本技术的至少一个实施例中,步骤一中,所述获取条件规则中的所有语句,计算每条语句的可疑度值,并根据语句的可疑度值的大小对所述语句进行排序,包括:
9、s11、获取条件规则的频谱信息,并从所述频谱信息中提取的语句覆盖矩阵以及执行结果向量;
10、s12、根据所述语句覆盖矩阵以及所述执行结果向量计算出每条语句的可疑度计算变量;
11、s13、根据每条语句的可疑度计算变量计算出对应语句的可疑度值;
12、s14、根据语句的可疑度值的大小对所有语句进行排序。
13、在本技术的至少一个实施例中,s12中,所述根据所述语句覆盖矩阵以及所述执行结果向量计算出每条语句的可疑度计算变量,包括:
14、条件规则pg={s1,s2,...,sm}在测试用例集ts={t1,t2,...,tn}下的语句覆盖矩阵为m×n维矩阵,矩阵元素ci,j表示语句si在测试用例tj下的覆盖结果,如果si在tj下被执行,则ci,j=1,否则ci,j=0;
15、条件规则pg={s1,s2,...,sm}在测试用例集ts={t1,t2,...,tn}下的执行结果向量为长度为n的向量,向量元素rj表示条件规则在测试用例tj下的程序执行结果,如果条件规则执行失败,则rj=1,否则rj=0;
16、可疑度计算变量包括:n0、n1、n10、n11、n00、n01,其中,
17、
18、
19、
20、
21、
22、
23、其中,n0表示成功测试用例的数目,n1表示失败测试用例的数目,n10表示成功同时执行语句si的测试用例数目,n11表示失败同时执行语句si的测试用例数目,n00表示成功且未执行语句si的测试用例数目,n01表示失败且未执行语句si的测试用例数目。
24、在本技术的至少一个实施例中,s13、根据每条语句的可疑度计算变量计算出对应语句的可疑度值,包括
25、采用jaccard公式计算出语句的可疑度值:
26、
27、或,采用cpm公式计算出语句的可疑度值:
28、
29、或,采用tarantula公式计算出语句的可疑度值:
30、
31、其中,sus(s)为可疑度值。
32、在本技术的至少一个实施例中,步骤二中,所述获取条件规则中的所有失效执行切片,计算每个失效执行切片的动态失效执行块的可疑度值,并根据动态失效执行块的可疑度值的大小对所述失效执行切片进行排序,包括:
33、s21:获取条件规则中的所有失效执行切片,确定每个所述失效执行切片中的动态失效执行块;
34、s22、获取条件规则的频谱信息,并从所述频谱信息中提取的动态失效执行块覆盖矩阵以及执行结果向量;
35、s23、根据所述动态失效执行块覆盖矩阵以及所述执行结果向量计算出每个动态失效执行块的可疑度计算变量;
36、s24、根据每个动态失效执行块的可疑度计算变量计算出对应动态失效执行块的可疑度值;
37、s25、根据动态失效执行块的可疑度值的大小对所有失效执行切片进行排序。
38、在本技术的至少一个实施例中,步骤三、根据所述语句以及所述失效执行切片的排序,逐一排查所述失效执行切片的动态失效执行块中的语句,得到错误语句,包括:
39、根据所述失效执行切片的排序依次排查所有失效执行切片,在每个所述动态失效执行块中,根据语句的排序依次排查所有语句,得到错误语句。
40、在本技术的至少一个实施例中,构建用于存储已经排查过的语句的语句池p(s),在排查时,先判断该语句是否在所述语句池p(s)中,若是,则跳过该语句,并排查下一条语句;若否,则排查该语句,并将该语句存储到所述语句池p(s)中。
41、发明至少存在以下有益技术效果:
42、本技术的可解释类深度神经网络条件规则错误定位方法,基于动态失效执行块实现错误定位,将所有的失效执行切片中的代码块作为计算其可疑性的颗粒度,在语句颗粒度级别上具有高度可疑性的一些正确语句可以被代码块排除在外,能够减少干扰语句的排查数量,还能在多错误的程序中包含所有错误语句,因此动态失效执行块所包含的信息可以提高其错误定位的效率和性能,这种新的颗粒度能够在一定程度上提高错误定位效率,从而可以对神经网络转化后的条件规则进行很好的错误定位及修改,非常具有实用性。
- 还没有人留言评论。精彩留言会获得点赞!