一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法与流程
本申请涉及行为检测识别的领域,尤其是涉一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法。
背景技术:
1、自动扶梯作为公共场所重要的交通工具,遍布商城、车站、天桥等公共场所。然而,自动扶梯上的一些危险行为不及时制止容易引发安全事故,造成严重的社会影响和人身伤害。
2、目前扶梯出入口处大都配有摄像机,可借助摄像机并分析扶梯上实时分析发生的危险行为。现有的通过深度学习提取人体关键点的位置姿态来判别是否摔倒,但此种方式由于图像清晰度较低,且人与人之间经常出现互相遮挡的情况,使得提取人体关键点位置容易出现偏差,经常出现识别不准的情况,从而导致对危险行为的判断缺乏准确性。
技术实现思路
1、为了实现更加准确地对自动扶梯上乘客的危险行为进行识别和判断,划分乘客行为的安全和危险姿态,以及时采取必要措施,本申请提供一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法。
2、本申请提供的一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法,采用如下的技术方案:
3、一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法,包括:
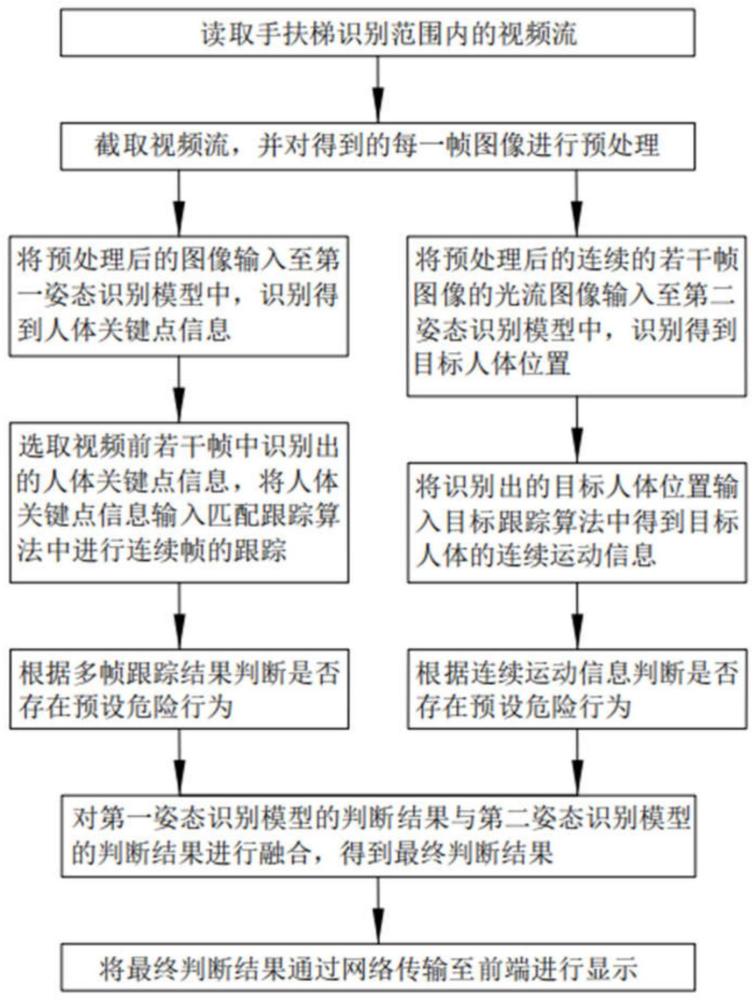
4、读取手扶梯识别范围内的视频流;
5、截取视频流,并对得到的每一帧图像进行预处理;
6、将预处理后的图像输入至第一姿态识别模型中,识别得到人体关键点信息;
7、选取视频前若干帧中识别出的人体关键点信息,将识别出的人体关键点信息输入匹配跟踪算法中进行连续帧的跟踪;
8、根据多帧跟踪结果判断是否存在预设危险行为;
9、将预处理后的连续的若干帧图像的光流图像输入至第二姿态识别模型中,识别得到目标人体位置;
10、将识别出的目标人体位置输入目标跟踪算法中得到目标人体的连续运动信息;
11、根据连续运动信息判断是否存在预设危险行为;
12、对第一姿态识别模型的判断结果与第二姿态识别模型的判断结果进行融合,得到最终判断结果;
13、将最终判断结果通过网络传输至前端进行显示。
14、可选的,所述预设危险行为包含摔倒、逆行、拥堵、越界其中一种或多种。
15、可选的,所述第一姿态识别模型的建立过程包括:以openpose模型为基础,由vgg-19网络的前10层对输入样本图像进行人体关键点特征提取,并将提取的人体关键点特征作为输入进行迭代,且在迭代过程中将前一阶段的预测与提取的人体关键点特征进行串联,迭代后得到人体关键点信息矩阵。
16、可选的,所述对输入样本图像进行人体关键点特征提取,包括:输入样本图像为同一时刻不同视角的样本图像,并对不同视角的样本图像分别进行人体关键点特征提取,并将不同视角提取的人体关键点特征进行融合,在融合过程中加入注意力模块进行注意力权重融合,得到最终的人体关键点特征,然后将最终的人体关键点特征输入至循环递归的卷积神经网络中得到人体关键点信息。
17、可选的,所述根据多帧跟踪结果判断是否存在预设危险行为,以及所述根据连续运动信息判断是否存在预设危险行为,均包括:
18、对人体关键点信息矩阵或目标人体位置提取坐标信息并分析是否超出划定的界限区域,若超出则存在预设危险行为,且危险行为为越界;
19、分析当前帧和上一帧头部到膝盖、肩部到膝盖、腰部到膝盖的距离差的变化是否超出预设范围,若超出则存在预设危险行为,且危险行为为摔倒;
20、分析脚部当前帧和10帧前的移动距离是否小于预设界定值,若小于,则存在预设危险行为,且危险行为为拥堵;
21、分析连续3秒内有多少次相邻两帧的人体关键点距离差值小于预设值,若大于两次则存在预设危险行为,且危险行为为逆行。
22、可选的,当存在所述预设危险行为为摔倒时,对相关的多帧图像进行再次判断。
23、可选的,对所述预设危险行为为摔倒进行再次判断时,分析膝盖、腰部、肩部三个点形成的角度是否超出预设范围,若超出则确定存在预设危险行为,且危险行为为摔倒。
24、可选的,所述第二姿态识别模型的建立过程包括:以ssd主干网络为基础,将光流图像经cnn处理提取特征图并将特征图分割为固定数目的单元,对每个单元生成一系列固定大小的候选框,再通过网络同时对候选框进行物体类别的分类和边界偏移的回归,得到目标人体位置;并将识别出中目标人体位置输入kcf目标跟踪算法中得到目标的连续运动信息。
25、可选的,所述将光流图像经cnn处理提取特征图包括:将光流图像分别进行普通卷积和扩张率为2的空洞卷积,然后将普通卷积的特征图与空洞卷积的特征图进行拼接并通过1*1卷积进行通道匹配,并经过通道注意力模块后得到最终的加强特征图。
26、可选的,所述对第一姿态识别模型的判断结果与第二姿态识别模型的判断结果进行融合,得到最终判断结果,包括:对第一姿态识别模型和第二姿态识别模型分别采用softmax函数计算出相应分类的得分,再采用融合分类网络将第一姿态识别模型的判断结果与第二姿态识别模型的判断结果进行融合,得到最终判断结果。
27、综上所述,本申请包括以下至少一种有益技术效果:
28、1.同时通过第一姿态识别模型的人体关键信息识别和跟踪以及第二姿态识别模型的光流图像中目标人体的识别和跟踪对危险行为进行判断,再将两种判断结果进行融合得到最终判断结果,提出了全新的融合判别网络,有效提高了对危险行为的判断准确性,以便于根据不同的危险行为采取必要的应急措施;
29、2.通过对不同视角的人体关键点特征进行融合,在融合过程中加入注意力模块,能够对人体关键点信息进行补充和完善,并提高人体关键点信息的准确性;
30、3.当存在所述预设危险行为为摔倒时,将相关的多帧图像输入至vgg网络进行再次判断,能够提高对于摔倒行为的判断准确性;
31、4.通过将光流图像分别进行普通卷积和空洞卷积后的特征图进行融合得到最终的特征图,从而加强了识别过程中不同大小、方向的目标人体的适配性能,有效提升了识别效果。
技术特征:
1.一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法,其特征在于,包括:
2.根据权利要求1所述的一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法,其特征在于,所述第一姿态识别模型的建立过程包括:以openpose模型为基础,由vgg-19网络的前10层对输入样本图像进行人体关键点特征提取,并将提取的人体关键点特征作为输入进行迭代,且在迭代过程中将前一阶段的预测与提取的人体关键点特征进行串联,迭代后得到人体关键点信息矩阵;
3.根据权利要求1所述的一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法,其特征在于,
4.根据权利要求1所述的一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法,其特征在于,所述预设危险行为包含摔倒、逆行、拥堵、越界其中一种或多种。
5.根据权利要求2所述的一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法,其特征在于,所述根据多帧跟踪结果判断是否存在预设危险行为,以及所述根据连续运动信息判断是否存在预设危险行为,均包括:
6.根据权利要求3所述的一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法,其特征在于,当存在所述预设危险行为为摔倒时,对相关的多帧图像进行再次判断。
7.根据权利要求4所述的一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法,其特征在于,对所述预设危险行为为摔倒进行再次判断时,分析膝盖、腰部、肩部三个点形成的角度是否超出预设范围,若超出则确定存在预设危险行为,且危险行为为摔倒。
8.一种电子设备,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,其中,所述处理器执行所述程序时可实现如权利要求1-5所述的方法。
9.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令在被处理器调用和执行时,计算机可执行指令促使处理器实现权利要求1-5所述的方法。
技术总结
本申请涉及一种基于图像跟踪和深度学习的乘客手扶梯危险行为识别方法,涉及行为检测识别的领域,其包括读取视频流;对每一帧图像进行预处理;将预处理后的连续视频若干帧图像输入至第一姿态识别模型中识别得到人体关键点信息,再进行连续帧的跟踪,判断是否存在预设危险行为;将预处理后的连续若干帧图像的光流图像输入至第二姿态识别模型中识别得到目标人体位置,再跟踪得到目标人体的连续运动信息,判断是否存在预设危险行为;对第一姿态识别模型的判断结果与第二姿态识别模型的判断结果进行融合,得到最终判断结果;将最终判断结果通过网络传输至前端进行显示。本申请具有更加准确地对自动扶梯上乘客的危险行为进行识别和判断的效果。
技术研发人员:王晓辉,柏阳,单洪伟,杨少辉,程万年,丁佳
受保护的技术使用者:无锡八英里电子科技有限公司
技术研发日:
技术公布日:2024/3/24
- 还没有人留言评论。精彩留言会获得点赞!