一种语音驱动面部动画方法、装置、设备及介质与流程
本发明涉及音频处理与模式识别,具体涉及一种语音驱动面部动画方法、装置、设备及介质。
背景技术:
1、当前,基于深度跨模态交互感知的语音驱动面部动画方法是一种先进的技术,它结合了语音信号处理、面部表情识别和情感分析等领域的知识。在过去几年中,深度学习在计算机视觉和自然语言处理等任务上取得了巨大成功,这也为语音驱动表情预测提供了有力支持。人类在进行交流时,语音和面部表情往往是密不可分的。通过深度学习技术,可以训练模型来解析语音信号,并将其与对应的面部表情联系起来;这种技术的背后主要依赖于神经网络的强大能力。通过构建复杂的深度神经网络架构,可以从语音数据中提取特征,并预测出相应的面部表情。
2、为了实现语音驱动的面部表情预测,研究人员需要大量的数据集,其中包括同时记录语音和面部表情的样本。这些数据被用于训练深度神经网络,使其能够理解语音信号与表情之间的关系。此外,还需要一些预处理步骤,例如声音分析和面部关键点检测,以帮助网络更好地理解输入数据。但是,现有的基于深度跨模态交互感知的语音驱动面部动画方法存在弥合音频单模态面部驱动动画不精准的问题。
3、有鉴于此,提出本申请。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种语音驱动面部动画方法、装置、设备及介质,使其在适用于不同场景、不同语言下的音频流的情况下,能够保证高精度实时混合形状动画系数推理结果,进而实时驱动角色面部动画,能够有效解决现有技术中的基于深度跨模态交互感知的语音驱动面部动画方法存在弥合音频单模态面部驱动动画不精准的问题。
2、本发明公开了一种语音驱动面部动画方法,包括:
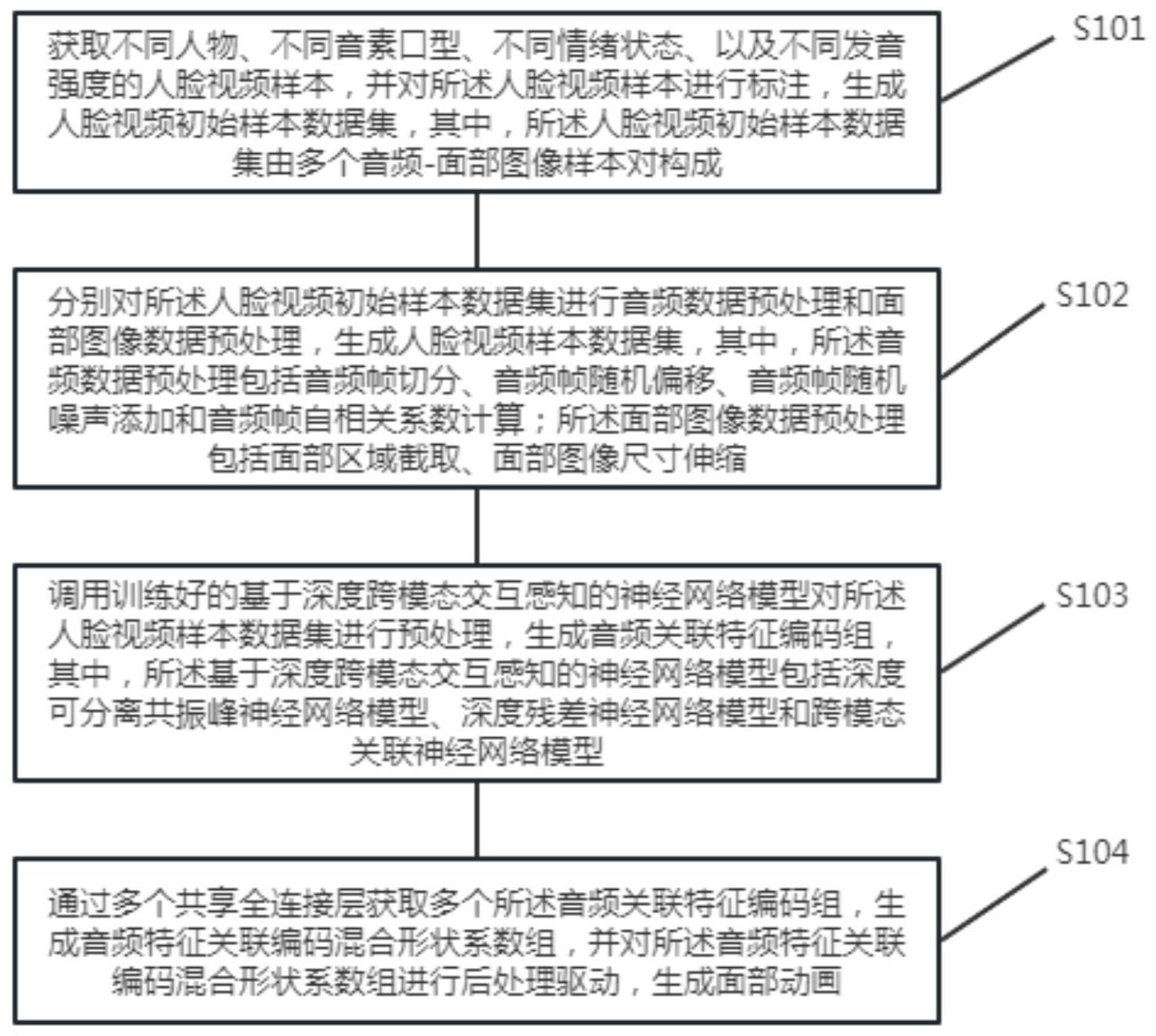
3、获取不同人物、不同音素口型、不同情绪状态、以及不同发音强度的人脸视频样本,并对所述人脸视频样本进行标注,生成人脸视频初始样本数据集,其中,所述人脸视频初始样本数据集由多个音频-面部图像样本对构成;
4、分别对所述人脸视频初始样本数据集进行音频数据预处理和面部图像数据预处理,生成人脸视频样本数据集,其中,所述音频数据预处理包括音频帧切分、音频帧随机偏移、音频帧随机噪声添加和音频帧自相关系数计算;所述面部图像数据预处理包括面部区域截取、面部图像尺寸伸缩;
5、调用训练好的基于深度跨模态交互感知的神经网络模型对所述人脸视频样本数据集进行预处理,生成音频关联特征编码组,其中,所述基于深度跨模态交互感知的神经网络模型包括深度可分离共振峰神经网络模型、深度残差神经网络模型和跨模态关联神经网络模型;
6、通过多个共享全连接层获取多个所述音频关联特征编码组,生成音频特征关联编码混合形状系数组,并对所述音频特征关联编码混合形状系数组进行后处理驱动,生成面部动画。
7、本发明还公开了一种语音驱动面部动画装置,包括:
8、样本获取单元,用于获取不同人物、不同音素口型、不同情绪状态、以及不同发音强度的人脸视频样本,并对所述人脸视频样本进行标注,生成人脸视频初始样本数据集,其中,所述人脸视频初始样本数据集由多个音频-面部图像样本对构成;
9、数据预处理单元,用于分别对所述人脸视频初始样本数据集进行音频数据预处理和面部图像数据预处理,生成人脸视频样本数据集,其中,所述音频数据预处理包括音频帧切分、音频帧随机偏移、音频帧随机噪声添加和音频帧自相关系数计算;所述面部图像数据预处理包括面部区域截取、面部图像尺寸伸缩;
10、神经网络模型处理单元,用于调用训练好的基于深度跨模态交互感知的神经网络模型对所述人脸视频样本数据集进行预处理,生成音频关联特征编码组,其中,所述基于深度跨模态交互感知的神经网络模型包括深度可分离共振峰神经网络模型、深度残差神经网络模型和跨模态关联神经网络模型;
11、面部动画生成单元,用于通过多个共享全连接层获取多个所述音频关联特征编码组,生成音频特征关联编码混合形状系数组,并对所述音频特征关联编码混合形状系数组进行后处理驱动,生成面部动画。
12、本发明还公开了一种语音驱动面部动画设备,包括处理器、存储器以及存储在存储器中且被配置由处理器执行的计算机程序,处理器执行计算机程序时实现如上任意一项的一种语音驱动面部动画方法。
13、本发明还公开了一种可读存储介质,其特征在于,存储有计算机程序,计算机程序能够被该存储介质所在设备的处理器执行,以实现如上任意一项的一种语音驱动面部动画方法。
14、综上所述,本实施例提供的一种语音驱动面部动画方法、装置、设备及介质,分别获取音频数据和面部图像数据并进行逐帧预处理操作;接下来提取音频帧内自相关系数作为音频特征以及通过seresnet50网络获得面部图像发音特征; 将音频特征输入到深度可分离共振峰神经网络获取音频共振峰发音特征,进一步分别通过全连接映射获取音频和面部对应的音素特征、跨模态差异特征、跨模态共享特征、情绪特征及音频强度特征组,最后通过跨模态交互感知和对齐方法获取音频和面部图像动画相关系数编码,并通过roc 曲线阈值限定和平滑操作对音频驱动面部动画相关系数编码进行后处理获得驱动面部动画的关键帧混合形状动画系数权重。本发明在适用于不同场景、不同语言下的音频流,能够保证高精度实时混合形状动画系数推理结果,进而实时驱动角色面部动画。从而解决现有技术中的基于深度跨模态交互感知的语音驱动面部动画方法存在弥合音频单模态面部驱动动画不精准的问题。
技术特征:
1.一种语音驱动面部动画方法, 其特征在于,包括:
2.根据权利要求1所述的一种语音驱动面部动画方法, 其特征在于,对所述人脸视频初始样本数据集进行音频数据预处理,具体为:
3.根据权利要求2所述的一种语音驱动面部动画方法, 其特征在于,对所述人脸视频初始样本数据集进行面部图像数据预处理,具体为:
4.根据权利要求3所述的一种语音驱动面部动画方法, 其特征在于,调用训练好的基于深度跨模态交互感知的神经网络模型对所述人脸视频样本数据集进行预处理,生成音频关联特征编码组,具体为:
5.根据权利要求4所述的一种语音驱动面部动画方法, 其特征在于,调用训练好的基于深度跨模态交互感知的神经网络模型对所述人脸视频样本数据集进行预处理,生成音频关联特征编码组,还包括:
6.根据权利要求1所述的一种语音驱动面部动画方法, 其特征在于,通过多个共享全连接层获取多个所述音频关联特征编码组,生成音频特征关联编码混合形状系数组,具体为:
7.根据权利要求1所述的一种语音驱动面部动画方法, 其特征在于,在调用训练好的基于深度跨模态交互感知的神经网络模型对所述人脸视频样本数据集进行预处理之前,还包括:
8.一种语音驱动面部动画装置,其特征在于,包括:
9.一种语音驱动面部动画设备,其特征在于,包括处理器、存储器以及存储在存储器中且被配置由处理器执行的计算机程序,处理器执行计算机程序时实现如权利要求1至7任意一项的一种语音驱动面部动画方法。
10.一种可读存储介质,其特征在于,存储有计算机程序,计算机程序能够被该存储介质所在设备的处理器执行,以实现如权利要求1至7任意一项的一种语音驱动面部动画方法。
技术总结
本发明提供了一种语音驱动面部动画方法、装置、设备及介质,获取音频和面部图像数据进行逐帧预处理;提取音频帧内自相关系数作为音频特征,通过SEResNet50网络获得面部图像发音特征;将音频特征输入深度可分离共振峰神经网络获取音频共振峰发音特征,通过全连接映射获取音频和面部对应的音素特征、跨模态差异特征、跨模态共享特征、情绪特征及音频强度特征组,通过跨模态交互感知和对齐方法获取音频和面部图像动画相关系数编码,通过ROC曲线阈值限定和平滑操作以获得驱动面部动画的关键帧混合形状动画系数权重。在适用于不同场景、不同语言下的音频流,能够保证高精度实时混合形状动画系数推理结果,进而实时驱动角色面部动画。
技术研发人员:柳欣,胡众旺,张力洋,徐素文,黄忠湖
受保护的技术使用者:天度(厦门)科技股份有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!