一种项目数据安全信息分级处理方法与流程
本发明涉及数据安全信息分级,特别是一种项目数据安全信息分级处理方法。
背景技术:
1、早期主要依靠人工进行数据安全分级,效率低下;2000年代开始引入规则引擎等半自动化技术;2010年代随着机器学习和nlp的发展,开始应用自然语言处理、深度学习等技术实现智能化安全分级;当前基于nlp和知识图谱的语义分析技术已较成熟,可以有效抽取文本语义特征;基于机器学习和深度学习的安全关联判断模型也日臻完善。
2、现有基于知识图谱的方法,安全关联推理主要局限在单跳范围,无法进行多跳复杂推理,对隐含关联的探测能力较弱;且当前方法由于依赖数据驱动,缺乏对安全分类决策过程的清晰解释,一定程度上降低了用户的信任感。
技术实现思路
1、鉴于上述数据安全分级中存在的问题,提出了本发明。
2、因此,本发明所要解决的问题在于如何提供一种提高数据安全分级的智能化水平,减少人工工作量,提升数据处理效率的方法。
3、为解决上述技术问题,本发明提供如下技术方案:
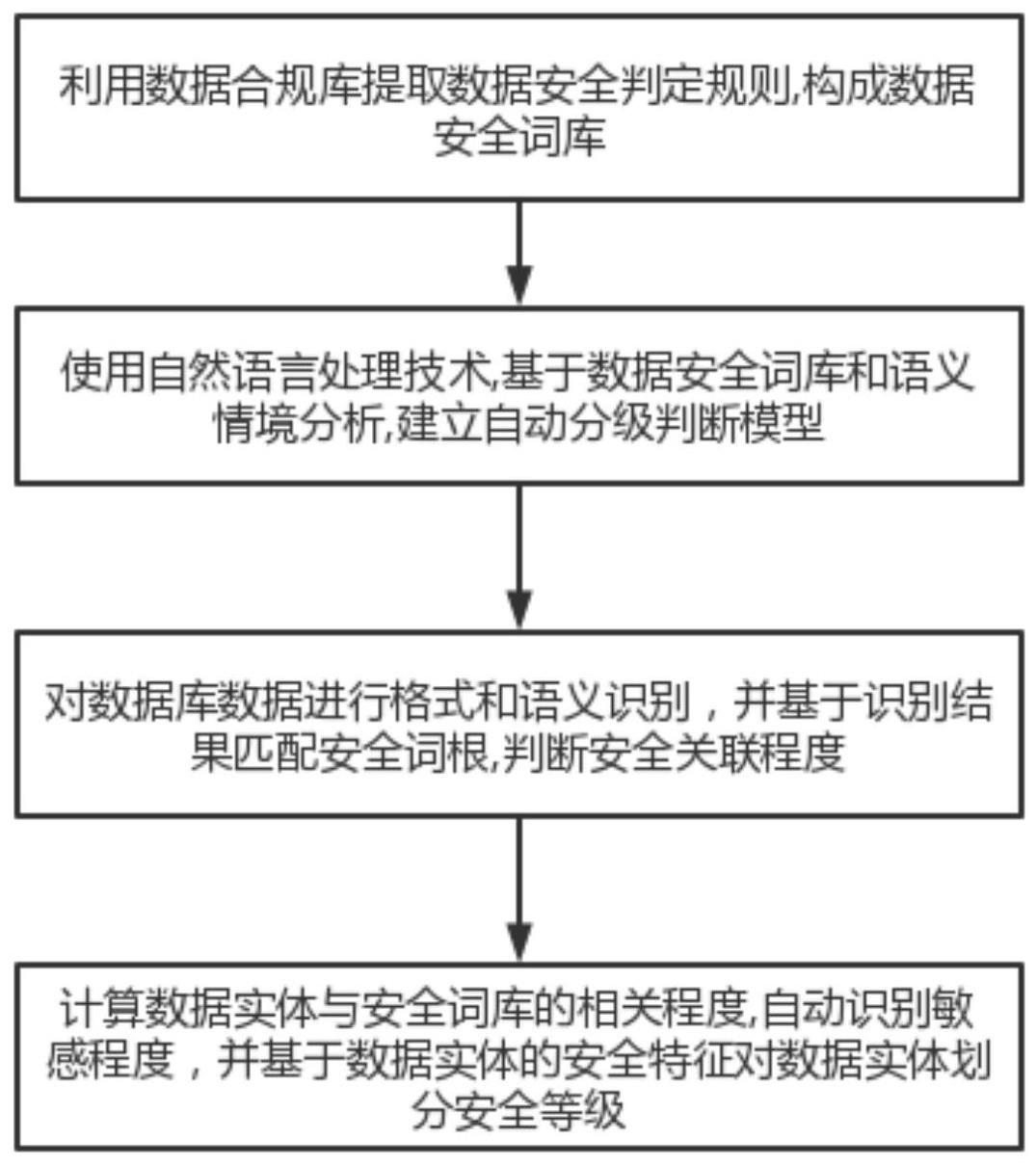
4、第一方面,本发明实施例提供了一种项目数据安全信息分级处理方法,包括利用数据合规库提取数据安全判定规则,构成数据安全词库;使用自然语言处理技术,基于数据安全词库和语义情境分析,建立自动分级判断模型;对数据库数据进行格式和语义识别,并基于识别结果匹配安全词根,判断安全关联程度;计算数据实体与安全词库的相关程度,自动识别敏感程度,并基于数据实体的安全特征对数据实体划分安全等级。
5、作为本发明所述项目数据安全信息分级处理方法的一种优选方案,其中:所述数据安全词库的构成过程包括以下步骤:采集相关行业数据合规库,使用文本分析合规库,提取合规规定中的数据安全和风险控制关键词;对关键词进行处理,提取词根,合并同义词,构建数据安全词库;词库中包含数据安全判断的关键词汇总;构建安全词向量空间,计算词汇安全关联度,过滤低关联词汇。
6、作为本发明所述项目数据安全信息分级处理方法的一种优选方案,其中:所述构建安全词向量空间包括使用word2vec技术,训练词向量模型,将每个词映射为一个高维向量;采集安全领域词汇表,包含不同安全分类标签;对每个安全类别词汇,在词向量空间中取均值,得到该类别的词向量代表;对新词汇,计算向量与各类别代表向量的余弦相似度,公式如下:
7、
8、其中,a为词汇的词向量,a∈rn,为n维向量;b为安全类别i的代表词向量,b∈rn,为n维向量;a·b为a和b的点积;||a||为词向量a的l2范数;||b||为向量b的l2范数;a和b间角度的余弦值,取值范围[-1,1],余弦值越大,表示两向量方向越接近,相似度越高;设定相似度阈值,大于相似度阈值则认为该词汇与对应的安全类别高度相关;对于相关度低于相似度阈值的词汇,进行人工审核判断其安全关联性;反馈人工判断结果,调整相关类别的代表向量;循环上述计算、校验和调整过程,至安全关联计算准确。
9、作为本发明所述项目数据安全信息分级处理方法的一种优选方案,其中:所述相似度阈值的设置过程为:采集验证词汇样本,且这些词汇的安全类别已知;对每个验证词汇,计算与各类别代表向量的余弦相似度;将余弦相似度排序,取前k个最相似类别;比较前k个类别与词汇实际类别的匹配情况;调整相似度阈值,目标为最大化前k个匹配的准确率;构建验证样本的roc曲线,横轴为假正率,即fpr,纵轴为真正率,即tpr,将曲线中tpr高于平均值的点划为预备点集1,将曲线中fpr低于平均值的点划分为预备点集2;取同一垂直线上预备点集1和2中的差值最大的值所在的点设为阈值点。
10、作为本发明所述项目数据安全信息分级处理方法的一种优选方案,其中:所述判断安全关联程度的步骤如下:构建安全关联知识图谱;对语句实体,在图谱中进行搜索,并返回所有匹配的实体节点;对多义实体,利用上下文过滤掉不相关义项;标记语句中匹配到的实体节点;从标记节点开始,深度优先搜索图谱;遍历节点边缘,推理出多跳关联路径,并设置最大跳数,避免无限遍历循环;返回连接语句实体的所有多跳关联路径;计算路径中关系的可信权重,并累加路径中的关系权重,并输出每个关联路径的可信度;训练神经网络对路径可信度进行判断,设路径i的可信度为ri,路径长度为li,则输入为[ri,li],使用带标签的路径数据训练网络,标签表示路径的安全关联程度y∈[0,1],优化损失函数为:
11、
12、其中,为预测输出;使预测输出逼近实际标签y,对新路径,输入其[ri,li]到网络,获得预测的安全关联概率汇总所有路径的获得语句的安全关联程度。
13、作为本发明所述项目数据安全信息分级处理方法的一种优选方案,其中:所述计算数据实体与安全词库的相关程度的过程为:综合数据格式、语义特征与安全词根的匹配程度、根据综合判断结果,匹配预定义的安全等级;所述综合数据格式、语义特征与安全词根的匹配程度的过程如下:对数据格式进行检查:若为结构化数据,则提取字段名称进行判断,若非结构化数据,则进行文本分词提取关键词;对提取的字段名称或关键词进行语义分析,判断它们是否符合名称构成规范;计算它们与预定义安全词根的语义相似度,根据语义相似度,确定字段名称或关键词的安全等级;对字段内容进行样本抽取,进行进一步判断:使用nlp技术对样本内容进行关键词提取;对提取出的关键词计算其在样本文本中的词频tf;对样本内容进行语义分析,判断是否包含敏感信息,若不包含,则维持原安全等级;若少量敏感关键词的阈值≤包含的敏感信息<大量敏感关键词的阈值,则提升一个安全等级;若包含的敏感信息≥大量敏感关键词的阈值,则提升两个安全等级。
14、作为本发明所述项目数据安全信息分级处理方法的一种优选方案,其中:所述匹配预定义的安全等级的过程如下:对数据格式进行判断:结构化数据:安全系数s1=2;半结构化数据:安全系数s1=1;非结构化数据:安全系数s1=0;对字段名称或关键词的语义相似度进行判断:低相似度时,安全系数s2=1;中相似度时,安全系数s2=2;高相似度时,安全系数s2=3;安全系数s的计算公式为:
15、s=s1+s2
16、对样本内容敏感词频进行判断:敏感词频<少量敏感词频阈值时,安全系数s不变;少量敏感词频阈值≤敏感词频<大量敏感词频阈值时,安全系数s+1;敏感词频≥大量敏感词频阈值时,安全系数s+2;根据安全系数s匹配对应安全等级;若安全系数存在冲突,则优先级为样本内容>语义相似度>数据格式。
17、第二方面,本发明为进一步解决数据安全分级中存在的问题,实施例提供了项目数据安全信息分级处理系统,其包括:数据采集模块,用于从数据合规库中采集相关文本数据,提取安全关键词;安全词库构建模块,用于对采集的安全关键词进行处理,构建安全词库;校验安全关联度,调整词向量空间,优化词库;数据判断模块,用于对数据源进行格式、语义分析,提取特征匹配安全词库计算安全关联程度,用于应用训练的判断模型,评估数据敏感程度,并最终划分数据的安全等级。
18、第三方面,本发明实施例提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其中:所述计算机程序被处理器执行时实现如本发明第一方面所述的项目数据安全信息分级处理方法的任一步骤。
19、第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,其中:所述计算机程序被处理器执行时实现如本发明第一方面所述的项目数据安全信息分级处理方法的任一步骤。
20、本发明有益效果为,本发明提高数据安全分级的智能化水平,减少人工工作量,提升数据处理效率;应用自然语言处理和深度学习技术,提升对非结构化数据的理解和处理能力;通过构建安全词向量空间,可以更准确判定词汇间的安全关联度;基于知识图谱的多跳关联推理,可以揭示隐含的数据安全关联;综合多种特征进行评估,提高了安全分级的准确性和完整性;动态计算相似度阈值和敏感词频阈值,避免了人为指定的主观性;本发明提供了可靠的安全分级依据,有助于企业更好地遵循数据合规要求。
- 还没有人留言评论。精彩留言会获得点赞!