基于查询大数据量结果集实时数据统计的性能优化方法与流程
本发明涉及对查询大量结果集实时统计分析方面的数据优化方法,具体涉及一种分表es聚合分页查询方法。
背景技术:
1、在写操作频率较低的业务下,mysql大数据量表的聚合查询能够通过建立合适的联合索引优化查询速度,但实际工作中的复杂聚合查询业务使得查询sql语句往往使用不上索引,比如like%keyword%group by yyy,zzz的形式就会导致查询sql语句全表扫描,查询速度缓慢。
2、可以将mysql大数据量表根据聚合字段的排列组合构建多个子表,预先将根据某种聚合字段组合后的聚合数据导入子表,用户根据具体聚合字段排列类型直接定位到某个子表查询数据。但这种方法只是暂时缓解查询速度缓慢的问题,随着时间流逝,每个子表中的数据不断增加,并且每个子表数据量的差距会越来越大,造成数据倾斜问题,也会导致查询速度缓慢。
3、elasticsearch是一个分布式、restful风格的搜索和数据分析引擎,它的查询速度极快,能够应对各种复杂聚合业务的场景,现在很多企业和团队都在使用elasticsearch。但在大数据量实际业务中,通过elasticsearch实时查询再聚合的方法对于需要快速响应的系统来说也是不理想的。
技术实现思路
1、本发明要解决的技术问题是:现有通过mysql进行聚合查询和通过elasticsearch实时查询再聚合的方法,在600万条数据量下平均响应时间均在300ms以上,并且即使是通过elasticsearch实时查询再聚合的方法,在缓存失效的情况下平均响应时间也可能在秒级以上。
2、为了解决上述技术问题,本发明的技术方案是提供了一种基于查询大数据量结果集实时数据统计的性能优化方法,其特征在于,包括以下步骤:
3、步骤1、创建存储多种不同聚合类型的mysql数据库表;
4、步骤2、通过定时任务服务每隔一段时间从源业务数据表中根据不同聚合类型进行聚合查询计算,在备份并清空每张聚合数据结果表之后,将最新的聚合结果导入到对应的聚合数据结果表中;
5、步骤3、在elasticsearch中创建与每张聚合数据结果表相对应的mapping和索引,作为存储mysql向elasticsearch导入数据的容器,其中:
6、elasticsearch中的文档存储实际的数据记录,mysql数据库表中的一条记录对应一个文档,并且mysql数据库表的主键与文档id一一对应的,则:索引为用于存储和搜索文档的数据结构,mapping用于定义索引中文档的字段类型、属性和相关设置的过程,描述文档的结构和属性;
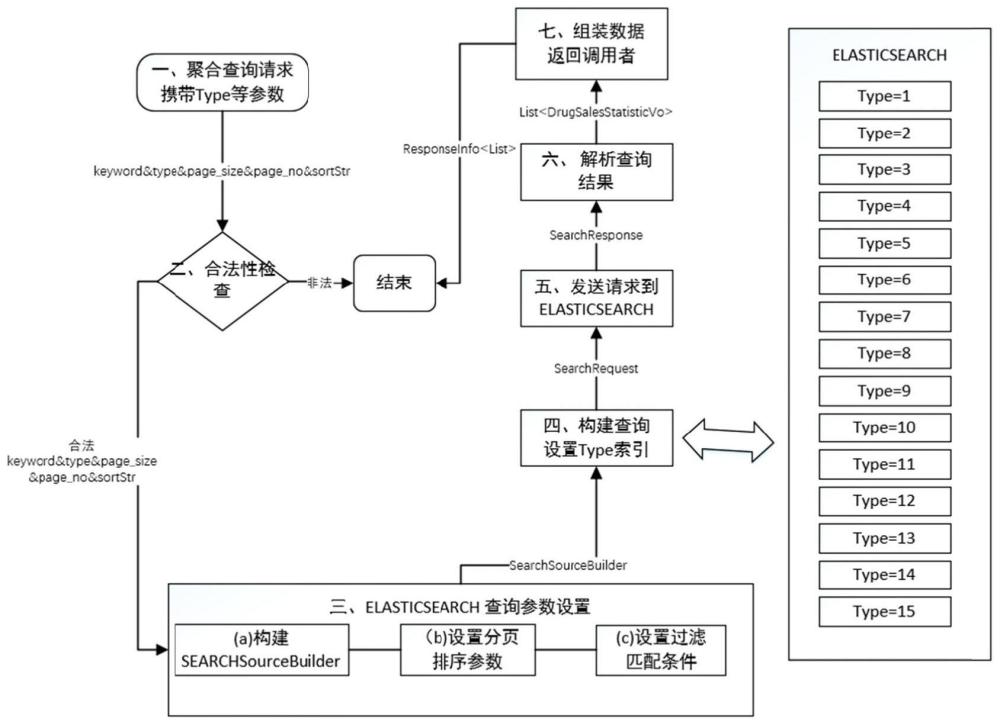
7、步骤4、javaapi构建查询条件进行查询,具体包括以下步骤:
8、步骤401、服务提供带有聚合类型参数的查询统计接口,查询调用者调用该查询统计接口时提供相关查询参数,该查询参数包括查询的关键字keyword、查询统计的elasticsearch模型type、具体的分页相关参数page_size和page_no、查询结果的排序需求sortstr;
9、步骤402、查询调用者在前端选择聚合字段,然后发起聚合查询请求,服务接受聚合查询请求后,进行查询参数的相关安全合理性检查,通过检查后,进入下一步;
10、步骤403、基于查询参数构造查询elasticsearch的查询参数对象searchsourcebuilder;
11、步骤404、将查询参数对象searchsourcebuilder设置到elasticsearch的查询请求对象searchrequest上,同时设置具体的查询索引
12、步骤405、发送查询请求到elasticsearch,elasticsearch将查询结果集作为searchresponse的对象返回;
13、步骤406、将elasticsearch返回的searchresponse数据结构进行解析和数据提取,将其json形式的数据集,解析成为java的list对象,并将处理后的结果组装到自定义的标准回复对象,返回查询调用者。
14、优选地,步骤1中,创建存储多种不同聚合类型的mysql数据库表时,根据具体业务需求进行分析,得到若干需要在查询时聚合的字段后,对这些字段进行排列组合,创建所述mysql数据库表,每个mysql数据库表中包含必须的字段以及排列组合生成的聚合字段。
15、优选地,步骤2中,在java中使用quarz框架搭建所述定时任务服务。
16、优选地,步骤3中,在mapping中设置字段的type属性以及字段的analyzer属性,其中:
17、若字段为聚合字段,那么将字段的type属性设置为keyword;若字段为文本字段,那么将字段的type属性设置为text;若字段为数字或日期字段,那么将字段的type属性设置为对应的数字类型和日期类型;
18、通过设置字段的analyzer属性来指定elasticsearch使用何种分词器对该字段进行有效的分词,提高模糊查询的效率。
19、优选地,步骤3中,若当前字段中涉及较多的中文或者中英文混合,则在设置字段的analyzer属性时,使用ik分词器和pinyin分词器结合的方式设定分词器,包括以下步骤:
20、步骤301、在elasticsearch集群的每个节点目录中安装ik分词器和pinyin分词器的插件;
21、步骤302、重启elasticsearch集群,在kibana控制台配置自定义分词器,自定义分词器的过滤条件结合ik分词的特点以及pinyin分词的特点;
22、步骤303、设置字段的analyzer属性时,将字段的analyzer属性设定为自定义分词器名。
23、优选地,步骤402中,相关安全合理性检查包括以下方面:
24、若查询参数type未传递,或者传递的查询参数type值不存在对应的索引名称,则查询结束;
25、分页相关参数page_size和page_no不合理,参数超过100或者为负数,则查询结束,或者所查询的页码数据超过实际或者对应数据不存在,则查询结束;
26、对查询结果的排序需求sortstr进行检查,sortstr中的字段必须是实际存在的数据字段,并且其字段内容支持排序,如果相应字段不满足排序要求,则查询结束;
27、对请求的权限进行检查,若有权限,则查询结束。
28、优选地,步骤405包括以下步骤:
29、获得resthighlevelclient的缓存实例对象;
30、将步骤404获得的查询请求对象searchrequest绑定到resthighlevelclient,发送请求到elasticsearch的具体索引上;
31、elasticsearch将查询结果集作为searchresponse的对象返回。
32、优选地,还包括mysql与elasticsearch数据同步的步骤,由java中的quarz定时任务框架服务提供mysql与elasticsearch的数据同步,具体包括以下内容:
33、在所有不同聚合数据结果表中建立触发器,当聚合数据结果表中的数据发生增加、删除以及修改操作时,产生触发并将此次操作写入mysql的日志表中;每隔一段时间,源业务数据表中的数据经过不同类型的聚合后导入到对应的聚合数据结果表中,导入的操作记录到mysql的日志表中,通过java中的quarz定时任务框架服务定时将elasticsearch指定索引下的数据进行备份,然后清空后将mysql的日志表中记录的全部操作同步到elasticsearch中,完成同步后备份并清空日志表。
34、本发明公开的技术方案能够保证在较低频率写操作的业务中,在600万数据量下进行业务多字段聚合查询接口的平均响应时间在300ms以下,实现查询接口的快速响应。
35、与现有技术方案相比,本发明具体具有如下有益效果:
36、1)有效保持接口平均响应时间在毫秒级别
37、本发明中使用的elasticsearch是一种专门用于搜索和分析的分布式引擎,它将数据分布在多个节点上进行分布式搜索。在大数据量的情况下,elasticsearch可以进行更快地搜索和匹配数据。本发明在600万数据量下对几个常用但是基数大的关键字和聚合字段进行多轮次的模糊聚合查询,排除网络波动的情况下,无论是首次查询或是通过多轮elasticsearch缓存查询,测试得到的平均响应时间均在300ms以下,有效地将接口平均访问时间控制在毫秒级别。
38、2)接口只做查询而不做实时聚合,提高系统吞吐量
39、本发明对比使用elasticsearch实时查询并聚合后返回的方案而言,将查询与聚合解耦,聚合在一段时间内只需要自动化执行一次后即可复用,这使得系统可以处理更多的查询请求,提高系统的吞吐量。
40、3)支持分词查询,提高关键字模糊搜索的效率
41、业务接口不仅支持聚合查询,也支持模糊查询。mysql的模糊查询功能相对较弱,需要使用like等关键字进行查询,而like关键字配合%进行模糊查询的方法经常会导致mysql索引失效,导致查询数据缓慢,进一步导致接口的平均响应时间过高。本发明中的elasticsearch在索引结构中可以对每个文本字段指定相关的分词器,提取文本字段的相关词项,建立词项与文档之间的映射关系,然后在查询的时候通过倒排索引的方式进行模糊搜索,这使得elasticsearch的模糊搜索效率比mysql要高。
42、4)有效降低查询代码复杂度,易于扩展到相似查询业务
43、本发明所公开的技术方案现已在本公司的医院销售数据查询业务中完成落地应用,使用elasticsearch提供的简便javaapi接口代码代替原本方案中复杂的sql语句xml文件,有效降低了查询代码的复杂度。本发明的整体架构和请求流程十分便捷,方便扩展到其他相似的查询业务场景。
- 还没有人留言评论。精彩留言会获得点赞!