一种关于中文语法纠错的误纠过滤器的建立方法与流程
本技术属于中文文本纠错领域,具体涉及一种关于中文语法纠错的误纠过滤器的建立方法。
背景技术:
1、目前中文文本语法纠错方法主要包括基于规则的方法、基于统计机器翻译的方法和基于深度学习的方法。其中,基于深度学习的方法在中文语法纠错中具有很大的优势,能够在大范围的错误类型和句子结构上实现较高的纠错准确率,并且在不断的研究和优化中不断提升性能。基于深度学习的中文语法纠错模型中,效果最显著的是bart模型。
2、虽然bart在中文文本纠错方面有出色表现,但它也可能存在一些缺陷,导致错误纠正的情况时有发生。如bart模型倾向于更改句子的结构,避免歧义导致的过于保守的修正误纠;在正确的部分进行不必要的更改导致的正误判断模糊;模型认为自己进行正确的修改实则产生错误纠正的模型过度自信;稀有词汇和短语在预训练阶段没有充分学习导致对其处理不足,导致不正确的纠正;训练数据不足或偏差引起的模型拟合这些模式导致的误纠等,为了克服上述错误纠正的缺点,需要一种针对中文语法纠错结果的过滤策略,以应对bart模型为代表的基于深度学习的中文语法纠正模型的误纠问题,旨在在最终的纠正结果中仅保留准确的纠正建议,所以针对上述存在的问题,需要建立一种有效地减少误纠的过滤器,本发明针对这一技术问题进行解决。
技术实现思路
1、本发明提供了一种关于中文语法纠错的误纠过滤器的建立方法,可以通过建立后的过滤器对纠正后的结果进行过滤,鉴别并排除纠正中的误纠,确保仅保留正确的纠正建议,提升了纠错结果的可靠性和准确性,有效地减少误纠。
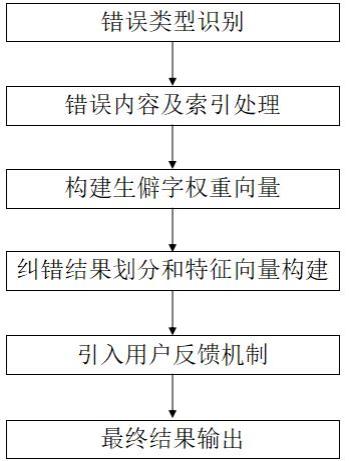
2、一种关于中文语法纠错的误纠过滤器的建立方法,包括以下步骤:
3、s1、错误类型识别:通过rnn和cnn,对模型纠正输出的错误类型进行分类,将语法纠错相关的错误类型从中筛选出来,仅保留属于语法纠错的错误类型,上述中的rnn为循环神经网络,cnn为卷积神经网络;
4、s2、错误内容及索引处理:使用深度模型进行文本语法纠错后,对输出结果进行格式调整,以错误内容、纠正内容、错误内容加前后字、纠正内容加前后字、错误句子以及纠正句子的形式呈现,将每一条输出结果表示为一条向量;
5、s3、构建生僻字权重向量:在进行深度模型中文语法纠错后的结果过滤处理时,采取引入由若干个不同生僻字构成的权重向量的策略,以实现对包含生僻字内容误纠结果的去除,确保只保留准确的语法纠正;每个生僻字都被赋予特定权重,并设定一个阈值,权重高于该阈值的情况下,纠正结果不包含生僻字的内容不予纠正,权重低于阈值时,对含有生僻字的内容进行纠正;
6、s4、纠错结果的划分和特征向量构建:将深度模型纠错后输出的纠错结果分为含有'的'的错误和其他错误两类,对每种错误类型,提取其特征向量,并进行特征向量的计算和比较,对于含有'的'的错误,将其纠正结果与原文前后字组合,形成新文本;
7、随后,通过比较纠错结果的特征向量与设定的阈值,判定其相似度,若特征向量相似度低于阈值,即认为该结果为误纠,进行过滤处理,只保留经过特征向量计算和过滤的纠正结果;
8、s5、引入用户反馈机制:在实际应用中,引入用户反馈机制,让用户对模型提供的修改进行确认或调整,形成一个反馈数据集,将这些反馈数据用于模型更新和迭代,可以不断优化模型的纠错能力,并且能够根据用户的反馈不断优化模型;
9、s6、最终结果输出:通过上述步骤的处理,最终输出经过错误类型分类、特征向量计算、生僻字权重过滤以及用户反馈优化的中文文本语法纠错结果。
10、进一步的,所述步骤s1具体包括如下过程:
11、s11、数据准备:准备标注数据集,所述标注数据集包含模型纠正输出的句子、原始句子以及相应的错误类型标签,用于指示不同的错误类型;
12、s12、模型训练:使用准备好的标注数据来训练rnn和cnn模型,输入数据为模型纠正后的句子和原始句子,目标是预测错误类型标签,训练过程中,模型通过反向传播来学习特征表示和分类决策;
13、s13、错误类型分类:分类模型训练完成后,将纠正输出的句子和原始句子送入训练好的模型,模型将输出一个错误类型的预测结果,用于指示该句子中存在的错误类型;
14、s14、阈值设置:设定适当的阈值,用于判断哪些错误类型被认为是存在的,用于确保仅保留与语法纠错相关的错误类型,而过滤掉其他错误类型;
15、s15、错误类型过滤:基于模型的预测结果和设定的阈值,将纠正结果中被预测为语法纠错相关的错误类型筛选出来,最终输出的结果只包含语法纠错建议,从而完成语法纠错任务的筛选。
16、进一步的,所述步骤s2具体包括如下过程:
17、s21、内容和索引提取:从深度模型纠正前、后的文本中提取错误内容、纠正内容以及相应的错误索引;
18、s22、前后字添加:对错误内容和纠正内容进行文本处理,在文本前、后分别添加字,以提供上下文信息;
19、s23、输出格式调整:调整输出结果的格式,使其以错误内容、纠正内容、错误内容加前后字、纠正内容加前后字、错误句子和纠正句子的形式呈现;
20、s24、向量表示:将每条输出结果分别表示为一个向量,方便后续处理和分析。
21、进一步的,所述步骤s3具体包括如下过程:
22、s31、权重向量准备:创建一个包含若干个不同生僻字的权重向量,为每个生僻字赋予特定的权重,这些权重基于生僻字的频率、重要性等因素进行设置;
23、s32、生僻字检测:对每个深度模型输出的纠正结果,逐字检查是否包含生僻字,如果包含生僻字,则进入下一步;
24、s33、权重比较:对包含生僻字的纠正结果,获取其中每个生僻字在权重向量中的权重值;
25、s34、阈值设定:设置一个阈值,用于区分高权重和低权重的生僻字,并用于决定何时对含生僻字的内容进行纠正或过滤;
26、s35、过滤与纠正:根据权重值和阈值,判断是否对纠正结果进行过滤或纠正,如果权重高于设定的阈值,则不予纠正,保留原样;如果权重低于阈值,则进行纠正;
27、s36、结果输出:最终,只保留通过过滤和纠正的纠正结果,这些结果不含高权重的生僻字或类似的复杂字。
28、进一步的,所述步骤s4具体包括如下过程:
29、s41、错误分类和特征向量提取:对深度模型输出的纠错结果进行分类,一类是错误内容中含有'的'字的错误,另一类是其它错误,对于每种错误结果,提取其特征向量;
30、s42、特征向量计算:对每个纠错结果,计算其对应的特征向量;
31、s43、加原文前后字:对于错误内容中含有'的'字的错误,将其纠正结果加上原文前后的字,形成新的文本,用于在过滤时,考虑上下文信息;
32、s44、特征向量比较:对每个纠错结果的特征向量,与预先设定的阈值、标准特征向量进行比较,所述阈值用于判断特征向量的相似程度;
33、s45、过滤处理:根据特征向量的比较结果,当某个纠错结果的特征向量与标准特征向量相似度低于阈值时,则认为它是误纠结果,将其过滤掉,对于错误内容中含有'的'字的错误,需要额外考虑加原文前后字的文本;
34、s46、纠正结果输出:最终,只保留通过特征向量计算和过滤处理后的纠正结果,其他误纠结果被过滤掉。
35、进一步的,所述步骤s5具体包括如下过程:
36、s51、用户界面嵌入:在实际应用中,为用户提供一个界面,展示由模型提供的纠正建议,用于在用户编辑的过程中显示,允许用户看到并干预模型的建议;
37、s52、用户确认和调整:用户能够选择确认模型的建议,也能够进行调整、修改,形成用户对纠正建议的反馈;
38、s53、反馈数据收集:用户的确认和调整操作会生成反馈数据,这些数据记录了用户对不同纠正建议的反应,包括哪些被接受、哪些被修改,以及具体的修改内容;
39、s54、反馈数据整理:将收集到的反馈数据整理成一个反馈数据集,这个数据集包括原始文本、模型纠正、用户操作、修改后的文本等信息;
40、s55、模型更新和迭代:利用反馈数据集,对模型进行更新和迭代,并通过监督学习、强化学习等方法,将用户反馈融入模型的训练中,以优化模型的纠错能力;
41、s56、主动学习策略:利用反馈数据,设计主动学习策略,选择模型最不确定、最容易出错的样本,向用户询问反馈,以进一步改进模型;
42、s57、模型评估与持续改进:使用反馈数据进行模型评估,计算误纠率和准确率,确定模型更新的效果,持续地根据用户反馈进行模型改进,不断提升模型的纠错能力。
43、本发明的技术效果如下:
44、(1)通过使用rnn和cnn,可以使本方案的过滤器更精确地对纠错模型输出的错误类型进行识别和分类,尤其是针对语法纠错相关的错误,有助于准确地筛选出需要纠正的错误类型,并减少误纠情况,实现了对错误类型的精准识别和分类;
45、(2)通过错误内容、纠正内容、前后字等形式的呈现,不仅使得该过滤器的输出结果更易读,而且还丰富了错误信息和纠正建议,为用户提供更全面的纠错参考,使呈现的结果更加丰富;
46、(3)引入了生僻字权重向量,针对深度模型对生僻字处理不足的问题,通过权重和阈值的调整,有效地过滤了含有生僻字的误纠结果,提升了纠错的准确性;
47、(4)区分含有“的”字的错误和其他错误,分别进行处理,考虑上下文信息,针对含有“的”字的错误,将其与原文前后字组合,进一步提高了纠错的精确度,从而针对特定错误进行处理;
48、(5)引入了用户反馈机制,通过用户反馈,不断优化模型的纠错能力,从而实现一个持续改进的过程,这种循环反馈机制不仅改善了误纠过滤,还能够让模型从实际使用场景中学习,进一步提升了纠错质量和系统性能。
- 还没有人留言评论。精彩留言会获得点赞!