用于相似堆垛的三维点云语义分割方法、装置及存储介质
本发明涉及危化品仓库监测,具体涉及用于相似堆垛的三维点云语义分割方法、装置及存储介质。
背景技术:
1、危化品仓库场景点云语义分割是感知周边环境安全监控的基础性工作,危化品仓库中堆垛外观相似,且摆放有严格的距离要求。
2、语义分割技术是工厂进行安全监控的重要步骤,该技术使用特定的语义类别将场景中的每个像素或点云划分为几个区域,为后续的异常监测报警、堆垛间距计算等工作起到支撑作用。目前在2d图像分割领域较为成熟的算法主要有全卷积神经网络(fullyconvolutional networks,fcn)、u-net等基于深度学习的算法,但普通摄像机仅能获取仓库的二维图像信息,无法获取全局堆垛的信息。三维点云(3d point cloud)是含有三维空间位置的点的集合,现有三维点云语义分割方法主要包括逐点mlp(multilayerperceptron)方法、基于点卷积的方法、循环神经网络(recurrent neural network,rnn)方法和基于图卷积的方法。
3、传统的三维点云分割技术主要应用于自动驾驶、三维建模等领域,但上述领域对近距离相似物品的分割要求不高,然而危化品仓库中有不同种类的危险化学品之间要保持着严格的距离要求,以减少潜在的事故风险和最小化损害,所以精细地语义分割技术在危化品仓库安全监控、库存管理和应对紧急情况等方面具有重要意义,具体地:由于危化品仓储空间内存在着相似度很高的堆垛等,所以通过语义分割算法进行预测时,对于精准度有着很高的要求,而目前的点云语义分割算法由于局部特征提取不足,难以精确地对相似近距离堆垛进行分割,同时还存在着危化品仓储场景中不同类别的堆垛空间点云数量差异大,现有的语义分割算法才用的损失函数更关注数量问题,对近距离相邻堆垛之间的少量特殊点云的关注度不够,导致分割结果倾向于多数据的样本问题,导致预测结果不够精准的问题。
技术实现思路
1、有鉴于此,本发明的目的在于提供用于相似堆垛的三维点云语义分割方法、装置及存储介质,以解决以解决现有算法的由于局部特征提取信息不足,导致预测结果不够精准的问题,同时解决对于不同类别的堆垛空间点云数量差异较大的情况下,关注多数量点云特征导致分割错误的问题。
2、根据本发明实施例的第一方面,提供用于相似堆垛的三维点云语义分割方法,所述方法包括:
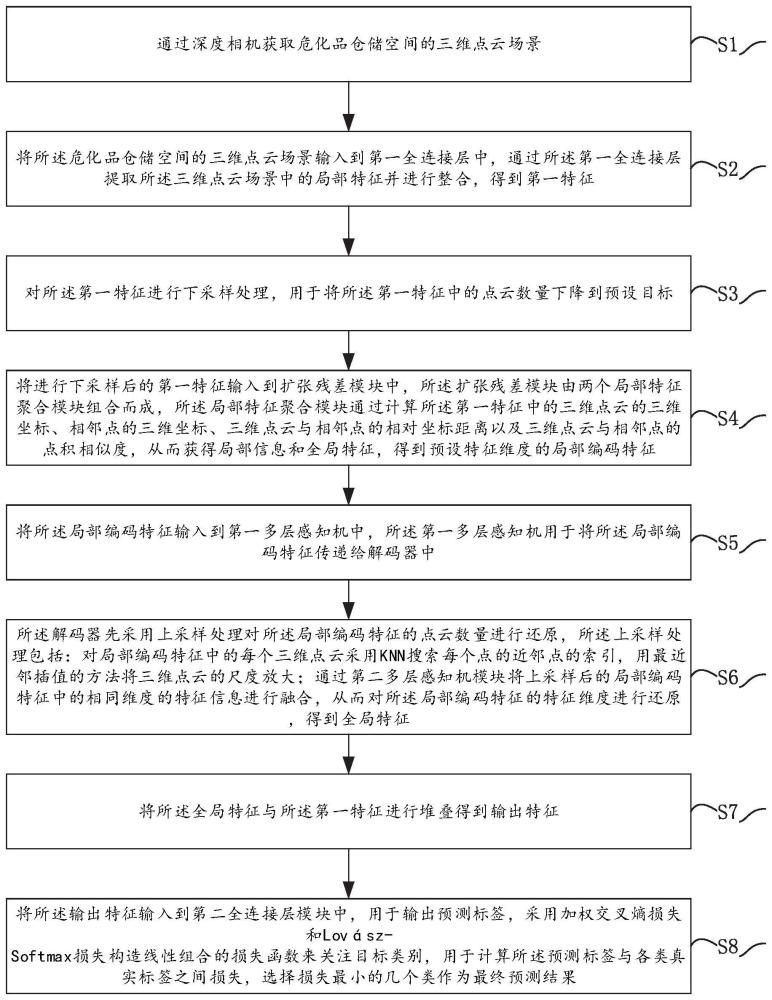
3、通过深度相机获取危化品仓储空间的三维点云场景;
4、将所述危化品仓储空间的三维点云场景输入到第一全连接层中,通过所述第一全连接层提取所述三维点云场景中的局部特征并进行整合,得到第一特征;
5、对所述第一特征进行下采样处理,用于将所述第一特征中的点云数量下降到预设目标;
6、将进行下采样后的第一特征输入到扩张残差模块中,所述扩张残差模块由两个局部特征聚合模块组合而成,所述局部特征聚合模块通过计算所述第一特征中的三维点云的三维坐标、相邻点的三维坐标、三维点云与相邻点的相对坐标距离以及三维点云与相邻点的点积相似度,从而获得局部信息和全局特征,得到预设特征维度的局部编码特征;
7、将所述局部编码特征输入到第一多层感知机中,所述第一多层感知机用于将所述局部编码特征传递给解码器中;
8、所述解码器先采用上采样处理对所述局部编码特征的点云数量进行还原,所述上采样处理包括:对局部编码特征中的每个三维点云采用knn搜索每个点的近邻点的索引,用最近邻插值的方法将三维点云的尺度放大;通过第二多层感知机模块将上采样后的局部编码特征中的相同维度的特征信息进行融合,从而对所述局部编码特征的特征维度进行还原,得到全局特征;
9、将所述全局特征与所述第一特征进行堆叠得到输出特征;
10、将所述输出特征输入到第二全连接层模块中,用于输出预测标签,采用加权交叉熵损失和lovász-softmax损失构造线性组合的损失函数来关注目标类别,用于计算所述预测标签与各类真实标签之间损失,选择损失最小的几个类作为最终预测结果。
11、优选地,
12、所述将进行下采样后的第一特征输入到扩张残差模块中,所述扩张残差模块由两个局部特征聚合模块组合而成,所述局部特征聚合模块通过计算所述第一特征中的三维点云的点积相似度获得局部信息和全局特征,得到局部编码特征包括:
13、将所述第一特征进行下采样处理,将所述第一特征的n个点云数量保留n/4的点云数量;
14、将进行下采样处理后的第一特征输入到第一扩张残差模块中,所述第一扩张残差模块用于将所述第一特征的8个特征维度变为32个特征维度,得到第一局部编码特征;
15、对所述第一局部编码特征进行下采样处理,将所述第一局部编码特征的n/4的点云数量变为n/16的点云数量;
16、将进行下采样处理后的第一局部编码特征输入到第二扩张残差模块中,所述第二扩张残差模块将所述第一局部编码特征的32个特征维度变为128个特征维度,得到第二局部编码特征;
17、对所述第二局部编码特征进行下采样处理,将所述第二局部编码特征的n/16的点云数量变为n/64的点云数量;
18、将进行下采样处理后的第二局部编码特征输入到第三扩张残差模块中,所述第三扩张残差模块用于将第二局部编码特征的128个特征维度变为256个特征维度,得到第三局部编码特征;
19、对所述第三局部编码特征进行下采样处理,将所述第三局部编码特征的n/64的点云数量变为n/256的点云数量;
20、将进行下采样处理后的第三局部编码特征输入到第四扩张残差模块中,所述第四局部编码特征用于将第三局部编码特征的256个特征维度变为512个特征维度,得到第四局部编码特征。
21、优选地,
22、所述将所述全局特征与所述第一特征进行堆叠得到输出特征包括:
23、将所述第四局部编码特征输入到第一多层感知机中,所述第一多层感知机将所述第四局部编码特征传递给第二多层感知机;
24、传递给所述第二多层感知机前,对所述第四局部编码特征进行上采样处理,将所述第四局部编码特征的点云数量还原到n/64;
25、所述第二多层感知机将所述第四局部编码特征的特征维度还原到256个特征维度,得到第一全局特征;
26、将所述第一全局特征与其对应的具有相同点云数量以及特征维度的所述第三局部编码特征进行堆叠,得到第一输出特征;
27、对所述第一输出特征进行上采样处理,将所述第一输出特征的点云数量还原到n/16;
28、将进行上采样处理后的第一输出特征输入到第三多层感知机中,所述第三多层感知机将所述第一输出特征的特征维度还原到128个特征维度,得到第二全局特征;
29、将所述第二全局特征与其对应的具有相同点云数量以及特征维度的所述第二局部编码特征进行堆叠,得到第二输出特征;
30、对所述第二输出特征进行上采样处理,将所述第二输出特征的点云数量还原到n/4;
31、将进行上采样处理后的第二输出特征输入到第四多层感知机中,所述第四多层感知机将所述第二输出特征的特征维度还原到32个特征维度,得到第三全局特征;
32、将所述第三全局特征与其对应的具有相同点云数量以及特征维度的所述第一局部编码特征进行堆叠,得到第三输出特征;
33、对所述第三输出特征进行上采样处理,将所述第三输出特征的点云数量还原到n;
34、将进行上采样处理后的第三输出特征输入到第五多层感知机中,所述第五多层感知机将所述第三输出特征的特征维度还原到8个特征维度,得到第四全局特征;
35、将所述第四全局特征与其对应的具有相同点云数量以及特征维度的所述第一特征进行堆叠,得到第四输出特征。
36、优选地,
37、所述将所述输出特征输入到第二全连接层模块中包括:
38、将所述第四输出特征输入到第二全连接层中,所述第二全连接层将所述第四输出特征的8个特征维度变为64个特征维度,得到第五输出特征;
39、将所述第五输出特征输入到第三全连接层中,所述第三全连接层将所述第五输出特征的64个特征维度变为32个特征维度,得到第六输出特征;
40、将所述第六输出特征输入到所述第四全连接层中,所述第四全连接层输出第六输出特征的预测标签。
41、优选地,
42、所述扩张残差模块由两个局部特征聚合模块组合而成,所述局部特征聚合模块通过计算所述第一特征中的三维点云的三维坐标、相邻点的三维坐标、三维点云与相邻点的相对坐标距离以及三维点云与相邻点的点积相似度,从而获得局部信息和全局特征,得到预设特征维度的局部编码特征包括:
43、所述扩张残差模块将输入特征中的三维点云的坐标信息和邻域索引相结合,引入三维点云之间的相对位置信息,得到f_xyz特征,通过共享mlp1使用一个二维卷积对f_xyz特征进行降维操作,将通道数减半为dout/2,所述dout为输入的特征的特征维度数;
44、引入一个点云数量为n,特征维度为3的点云数据,取所述点云数据的最后一列的颜色信息,基于所述颜色信息使用gather_neighbour函数采用邻域索引从输入特征中收集相邻点的特征,基于相邻点的特征采用reshape函数将输入特征转换为点云数量为n,特征维度为dout/2的f_neighbours特征;
45、将所述降维操作后的f_xyz特征与所述f_neighbours特征做一个级联操作得到f_concat特征,所述f_concat特征的点云数量为n,特征维度为dout;
46、将所述f_concat特征通过第一个局部特征聚合模块中的注意力池化操作将点云特征做最大池化处理,通过二维卷积将所述f_concat特征的维度从dout变换为dout/2,得到第一局部聚合特征;
47、再次引入一个点云数量为n,特征维度为3的点云数据,取所述点云数据的最后一列的颜色信息,基于所述颜色信息使用gather_neighbour函数采用邻域索引从所述第一局部聚合特征中收集相邻点的特征,基于相邻点的特征采用reshape函数将所述第一局部聚合特征转换为点云数量为n,特征维度为dout的第二f_neighbours特征;
48、将所述降维操作后的f_xyz特征与所述第二f_neighbours特征做一个级联操作得到第二f_concat特征,所述第二f_concat特征的点云数量为n,特征维度为dout;
49、将所述第二f_concat特征通过第二个局部特征聚合模块中的注意力池化操作将第二f_concat特征做最大池化处理,得到第二局部聚合特征,所述第第二局部聚合特征的特征维度不变,为dout;
50、将所述第二局部聚合特征输入到共享mlp2中,所述共享mlp2经过一个二维卷积操作,将通道数增加2倍,将所述第二局部聚合特征的特征维度变为2dout;
51、将所述输入特征还一并输入到共享mlp3中,所述mlp3对所述输入特征执行一个二维卷积的操作,将输入的点云特征的通道数扩展为原来的两倍,得到第三f_concat特征,所述第三f_concat特征的特征维度为2dout;
52、将所述第三f_concat特征以及第二f_concat特征相加,将相加之后的特征应用leaky relu激活函数,得到特征维度为2dout,点云数量为n的局部编码特征。
53、优选地,
54、所述局部特征聚合模块包括局部空间编码模块以及注意力池化模块;
55、所述局部空间编码模块用于获取输入特征的任意点云q的三维坐标,利用k最近邻算法搜索点q的k个近邻点的三维坐标;
56、采用点的内积的方法获取点云q分别与k个近邻点的相对坐标距离;
57、采用点积相似度计算点云q与k个近邻点的点积距离,将所述点云q的三维坐标、k个近邻点的三维坐标、点云q分别与k个近邻点的相对坐标距离以及点云q与k个近邻点的点积距离进行拼接,得到空间位置编码结果;
58、将所述空间位置编码结果与输入特征的点云通道数特征进行级联,得到点云q的局部特征;
59、将所述点云q的局部特征输入到所述注意力池化模块中,所述注意力池化模块通过定义一个g()函数,基于学习权值来学习点云q的局部特征的注意得分,将输入特征所有的局部特征与相应的注意分数加权和,得到局部聚合特征。
60、根据本发明实施例的第二方面,提供用于相似堆垛的三维点云语义分割装置,所述装置包括:
61、三维点云获取模块:用于通过深度相机获取危化品仓储空间的三维点云场景;
62、第一特征获取模块:用于将所述危化品仓储空间的三维点云场景输入到第一全连接层中,通过所述第一全连接层提取所述三维点云场景中的局部特征并进行整合,得到第一特征;
63、下采样模块:用于对所述第一特征进行下采样处理,用于将所述第一特征中的点云数量下降到预设目标;
64、局部编码特征获取模块:用于将进行下采样后的第一特征输入到扩张残差模块中,所述扩张残差模块由两个局部特征聚合模块组合而成,所述局部特征聚合模块通过计算所述第一特征中的三维点云的三维坐标、相邻点的三维坐标、三维点云与相邻点的相对坐标距离以及三维点云与相邻点的点积相似度,从而获得局部信息和全局特征,得到预设特征维度的局部编码特征;
65、传递模块:用于将所述局部编码特征输入到第一多层感知机中,所述第一多层感知机用于将所述局部编码特征传递给解码器中;
66、多层感知机模块:用于所述解码器先采用上采样处理对所述局部编码特征的点云数量进行还原,所述上采样处理包括:对局部编码特征中的每个三维点云采用knn搜索每个点的近邻点的索引,用最近邻插值的方法将三维点云的尺度放大;通过第二多层感知机模块将上采样后的局部编码特征中的相同维度的特征信息进行融合,从而对所述局部编码特征的特征维度进行还原,得到全局特征;
67、堆叠连接模块:用于将所述全局特征与所述第一特征进行堆叠得到输出特征;
68、预测模块:用于将所述输出特征输入到第二全连接层模块中,用于输出预测标签,采用加权交叉熵损失和lovász-softmax损失构造线性组合的损失函数来关注目标类别,用于计算所述预测标签与各类真实标签之间损失,选择损失最小的几个类作为最终预测结果。
69、根据本发明实施例的第三方面,提供一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被主控器执行时,实现所述的上述方法中的各个步骤。
70、本发明的实施例提供的技术方案可以包括以下有益效果:
71、本技术应用于危化品仓储空间的监测,由于危化品仓储空间中存在着相似性较高的堆垛,所以对检测结果的精准度有着较高的要求,针对现有语义分割算法存在的局部特征信息提取不足的问题,本方案在空间编码部用点积相似度替代欧式距离,构造局部特征聚合模块,而点积相似度相较于欧式距离以及余弦相似度来说,更适用于危化品仓储中的高维数据处理,可以更好地捕获点云之间的相似度和局部特征信息,从而提高语义分割的准确度、计算效率和性能;针对危化品仓库场景中堆垛类别间点云数量差异大的问题,集成了两种不同的权重计算方法,采用加权交叉熵损失和lovász-softmax损失构造线性组合的损失函数,使网络在训练过程中更加关注相似堆垛间的少量特殊点,解决了现有的神经网络学习中由于危化品类别点云数量差异大,导致大目标点云过拟合问题,实现近距离相似堆垛的点云精细分割。
72、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
- 还没有人留言评论。精彩留言会获得点赞!