一种基于空间感知Retinex分解的微光图像多通路并行增强方法
本发明属于计算机视觉、工业视觉、微光图像增强、图像去噪领域,涉及retinex理论、机器学习、图像处理和人工智能的方法,适用于各种需要微光图像增强的计算机视觉领域。
背景技术:
1、现有的微光增强技术主要分为基于像素值的映射增强方法、基于retinex理论的增强方法和基于深度学习的增强方法。基于像素值的映射增强方法以直方图均衡化(he)及后续延伸方法和伽玛矫正(gc)方法为代表。但基于像素值的映射增强方法是一种全局增强技术,非常容易增强图像中隐藏的噪声,也容易忽略像素点与邻域像素的关系,造成过度曝光或者图像细节丢失的情况。retinex理论第一次提出彩色图像能分解为照明分量和反射分量的假设。反射分量代表了图像除光照信息外的本质属性,包含图像的所有边缘细节颜色等信息。照明分量包含了图像大致的轮廓和亮度分布。最大领域差异的方法被用于生成图像的结构感知图和纹理感知图,通过感知图引导图像进行retinex分解能保留图像的纹理与轮廓。然而,基于处理结构感知图和纹理感知图的方法很难去除隐藏在黑暗中的噪声。稀疏梯度理论被引入retinex分解方法以保留边缘信息并消除噪声。但是面对高噪声图像,基于稀疏梯度理论的处理方法会导致增强结果产生颜色失真的问题。
2、随着深度学习技术的不断发展,深度学习的方法最先由llnet引入微光图像增强领域,其通过学习微光图像到高照度图像的映射并利用堆叠稀疏去噪自编码器对微光图像进行增强和去噪,但面对极低照明水平的图像,llnet会引入伪影并导致增强效果不自然。retinex-net是一种集合图像分解和光照水平估计的深度学习网络。retinex-net在retinex理论的基础上采用数据驱动的方式学习如何进行图像分解并利用去噪方法完成去噪任务,但会产生图像模糊和细节丢失的情况。为了使经过增强后的图像达到自然的效果,一种权重共享的级联照明学习自校正模块被应用于微光增强领域,虽然能使色彩重建自然度增加,但对于极低光照条件下的图像并不能获得良好的增强效果。
3、因此,提出一种基于空间感知retinex分解的微光图像多通路并行增强方法,来提高微光增强系统的性能和泛化能力,优化去噪和色彩恢复的过程,很好地抑制了伪影的出现,使增强效果能兼顾人眼感知水平与自然结构分布。
技术实现思路
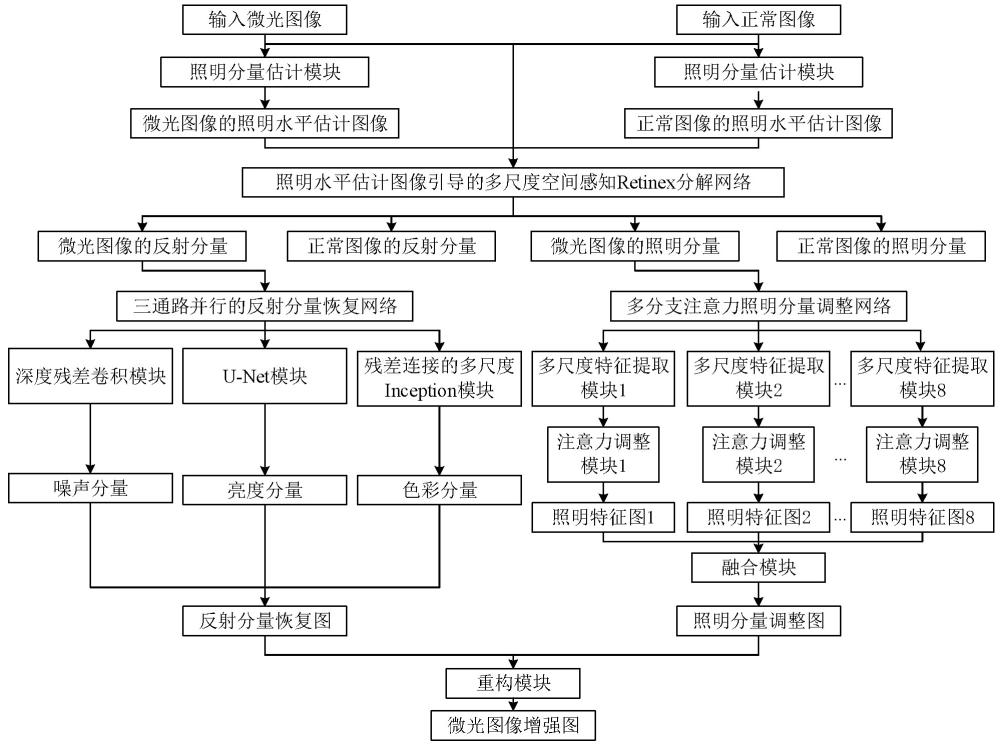
1、本发明提出一种基于空间感知retinex分解的微光图像多通路并行增强方法,将多尺度空间感知retinex图像分解方法、三通路并行的反射分量恢复网络和多分支高效卷积注意力照明分量调整网络进行结合,用于微光图像的增强,具有消除网络深度造成的特征图语义差异的功能,增强效果兼顾人眼感知水平和自然场景分布,优化去除噪声和色彩恢复的过程,提高增强系统性能和泛化能力;在使用过程中的步骤为:
2、步骤(1):通过微光增强领域的公开数据集获得像素大小为600×400×3的成对的微光图像和正常光照图像,微光图像每个像素点为llow(i,j,k),i=1,2,...,600;j=1,2,...,400;k=1,2,3;正常光照图像每个像素点为lhigh(i,j,k),i=1,2,...,600;j=1,2,...,400;k=1,2,3;将图像输入照明分量估计模块获得照明估计图为:
3、iestimat(i,j)=max[l(i,j,1),l(i,j,2),l(i,j,3)],i=1,2,...,600,j=1,2,...,400(1)
4、式中,iestimat(i,j)为照明估计图像;max[*]表示取最大值;l(i,j,1)表示输入图像第1通道的像素值;l(i,j,2)表示输入图像第2通道的像素值;l(i,j,3)表示输入图像第3通道的像素值;
5、步骤(2):通过利用照明估计图iestimat(i,j)引导图像进行retinex分解以获取准确真实的分解结果;将照明估计图iestimat(i,j)和对应图像l(i,j)合并一同作为输入特征图finput(i,j)输入照明水平预测图像引导的多尺度空间感知分解网络获得微光图像的反射分量rlow(i,j)和照明分量ilow(i,j)与正常光照图像的反射分量rhigh(i,j)和照明分量ihigh(i,j);照明水平预测图像引导的多尺度空间感知分解网络由多个多尺度残差卷积模块、语义深度相关的残差跳跃连接模块和混合像素空间感知上采样模块构成,消除由网络深度造成的语义差异,从而保留丰富的色彩信息与细节结构;输出的反射分量r(i,j)为:
6、r(i,j)=conv1(msrconv5(finput(i,j))) (2)
7、式中,conv1表示进行1次卷积操作;msrconv5表示进行5次多尺度残差卷积操作,finput(i,j)为输入特征图;
8、输出的照明分量i(i,j)为:
9、i(i,j)=conv1(msrconv2(finput(i,j))) (3)
10、式中,msrconv2表示进行2次多尺度残差卷积操作;
11、为了解决反射分量色彩失真和照明分量细节丢失的问题,照明水平预测图像引导的多尺度空间感知分解网络在损失函数的约束下进行训练;由重构损失反射一致性损失和照明平滑度损失三部分组成:
12、
13、式中,λre和λis分别为反射一致性损失和照明平滑度损失的系数;为重构损失;为反射一致性损失;为照明平滑度损失
14、重构损失为:
15、
16、式中,λlow,low和λlow,low为微光图像和正常光照图像重建损失系数;λlow,high和λhigh,low为混合重建损失函数;||*||1为l1损失函数;ri(i,j)为输入图像的反射分量;ij(i,j)为输入图像的照明分量;lj(i,j)为输入图像;⊙为矩阵的点乘运算;为i从微光图像到正常光照图像对应像素值的求和运算;为j从微光图像到正常光照图像对应像素值的求和运算;
17、反射一致性损失为:
18、
19、式中,h和w分别为输入图像的高和宽;c为输入图像的通道数;||*||char为charbonnier损失;ε为小于0.001的稳定常量;rlow(h,w,c)为输入微光图像的反射分量;rhigh(h,w,c)为输入正常光照图像的反射分量;
20、照明平滑度损失为:
21、
22、式中,表示图像的梯度,包括水平梯度和垂直梯度e为指数函数;λk为平衡结构与纹理细节信息的强度系数;
23、照明水平预测图像引导的多尺度空间感知分解网络框架为:
24、进入多尺度空间感知分解网络模块,分为两路,第二路进入照明分量估计模块,将第一路和第二路的输出合并;
25、进入多尺度残差卷积模块;
26、分为两路,第一路经过最大池化层,进入多尺度残差卷积模块,分为两路:
27、第一路经过最大池化层,进入多尺度残差卷积模块,分为两路:
28、第一路进入混合像素空间感知上采样模块;
29、第二路进入语义深度相关的残差跳跃连接模块;
30、将第一路和第二路合并,进入多尺度残差卷积模块,进入混合像素空间感知上采样模块;
31、第二路进入语义深度相关的残差跳跃连接模块;
32、将第一路和第二路合并,进入多尺度残差卷积模块;
33、经过一个1×1卷积层;
34、经过一个sigmoid激活层,输出反射分量;
35、第二路进入多尺度残差卷积模块,
36、经过一个1×1卷积层;
37、经过一个sigmoid激活层,输出照明分量;
38、每个模块的具体内容为:
39、进入多尺度残差卷积模块,分为两路:
40、第一路,经过第一个3×3卷积层,经过第一个prelu激活层,经过第一个批归一化层;经过第二个3×3卷积层,经过第二个prelu激活层,经过第二个批归一化层;经过第三个3×3卷积层,经过第三个prelu激活层,经过第三个批归一化层;第一个批归一化层的输出、第二个批归一化层的输出和第三个批归一化层的输出合并;
41、第二路,经过一个1×1卷积层,经过一个prelu激活层,经过一个批归一化层;
42、第一路和第二路合并;
43、进入语义深度相关的残差跳跃连接模块,分为两路:
44、第一路,经过一个3×3卷积层,经过一个prelu激活层;
45、第二路,经过一个1×1卷积层,经过一个prelu激活层;
46、第一路和第二路合并;
47、分为两条路,第一路经过一个3×3卷积层,经过一个prelu激活层;
48、第二路,经过一个1×1卷积层,经过一个prelu激活层;
49、第一路和第二路合并;
50、分为两条路,第一路经过一个3×3卷积层,经过一个prelu激活层;
51、第二路,经过一个1×1卷积层,经过一个prelu激活层;
52、第一路和第二路合并;
53、进入混合像素空间感知上采样模块,分为两路:
54、第一路,经过一个双线性邻域插值层,经过一个1×1卷积层,经过一个prelu激活层;
55、第二路,经过一个亚像素卷积层;
56、第一路和第二路合并;
57、步骤(3):微光图像的反射分量rlow(i,j)与正常光照图像的反射分量rhigh(i,j)存在映射关系,rlow(i,j)包含大量的噪声和颜色失真退化,映射关系为:
58、rhigh(i,j)=rlow(i,j)+c(i,j)-n(i,j)+d(i,j) (8)
59、式中,c(i,j)为颜色失真退化分量;n(i,j)为噪声分量;d(i,j)为亮度分量;
60、将微光图像的反射分量rlow(i,j)输入三通路并行的反射分量恢复网络能完成去除噪声、色彩恢复和细节结构保持的任务以获得微光图像反射分量的恢复图像rres(i,j);三通路并行的反射分量恢复网络由深度残差卷积模块、u-net模块和三个残差连接的多尺度inception模块组成;深度残差卷积模块能提取出微光图像的反射分量rlow(i,j)中含有的噪声分量n(i,j),噪声分量为:
61、n(i,j)=drcnn(rlow(i,j),rhigh(i,j)) (9)
62、式中,drcnn为深度残差卷积运算;
63、u-net模块能提取出微光图像的反射分量rlow(i,j)与正常光照图像的反射分量rhigh(i,j)之间缺少的亮度分量d(i,j),亮度分量为:
64、d(i,j)=unet(rlow(i,j),rhigh(i,j)) (10)
65、式中,unet为亮度分量估计运算;
66、残差连接的多尺度inception模块能提取出微光图像的反射分量rlow(i,j)的颜色失真退化分量c(i,j),颜色失真退化分量为:
67、c(i,j)=mirb(rlow(i,j),rhigh(i,j)) (11)
68、式中,mirb为颜色失真退化分量运算;
69、为了将微光图像的反射分量rlow(i,j)恢复至与正常光照图像的反射分量rhigh(i,j)相同的色彩水平,三通路并行的反射分量恢复网络在损失函数的约束下进行训练;由相似度损失结构损失感知内容损失和细节梯度损失四部分组成:
70、
71、式中,为三通路并行的反射分量恢复网络的损失函数;为相似度损失;为结构损失;为感知内容损失;为细节梯度损失;
72、相似度损失计算反射分量恢复图像与正常光照图像反射分量之间的l1损失,保证图像宏观层面的相似度,相似度损失为:
73、
74、式中,rres(i,j)为微光图像的反射分量恢复图像;
75、结构损失通过计算反射分量恢复图像与正常光照图像反射分量之间的结构衡量指标损失,以避免恢复过程中图像产生结构扭曲和畸变;结构衡量指标损失通过计算两张图片的结构衡量指标,考虑图像亮度、对比度和结构三个关键特征;结构损失为:
76、
77、式中,μres和σres分别为反射分量恢复图像各像素点像素值的均值和方差;μhigh和σhigh分别为正常光照图像各像素点像素值的均值和方差;σres,high为反射分量恢复图像和正常光照图像各像素点像素值的协方差;c1和c2为两个小于0.001的常数;ssim为结构衡量指标损失函数;
78、为了使用高级信息来提高恢复图像的视觉质量,感知内容损失将反射分量恢复图像与正常光照图像的反射分量分别输入预训练的vgg19网络,并计算网络输出的绝对差值作为两张图像的内容损失,感知内容损失为:
79、
80、式中,wi、hi和ci分别为预训练vgg19网络对应的特征图的宽、高和通道数;φi(*)表示vgg19网络第i层卷积层的输出;
81、为了保留图像边缘细节信息,细节梯度损失通过分别计算恢复结果图与正常光照图像反射分量在水平和垂直方向上梯度的l2损失,细节梯度损失为:
82、
83、式中,表示图像水平方向的梯度;表示图像垂直方向的梯度;||*||2表示l2损失函数;三通路并行的反射分量恢复网络框架为:
84、进入反射分量恢复网络模块,分为两路:
85、第一路,经过一个3×3卷积层,经过一个sigmoid激活层,进入高效卷积注意力模块;
86、第二路,经过一个7×7卷积层,经过一个leakyrelu激活层,进入高效卷积注意力模块;
87、第一路和第二路合并;
88、进入一个1×1卷积层,经过一个leakyrelu激活层,分为三路:
89、第一路,进入三个残差连接的多尺度inception模块;第一个残差连接的多尺度inception模块的输出、第二个残差连接的多尺度inception模块的输出和第三个残差连接的多尺度inception模块的输出合并,经过一个1×1卷积层,进入高效卷积注意力模块;
90、第二路,进入深度残差卷积模块,经过一个1×1卷积层,进入高效卷积注意力模块;
91、第三路,进入u-net模块,经过一个1×1卷积层,进入高效卷积注意力模块;
92、第一路、第二路和第三路合并;
93、进入一个1×1卷积层;
94、输出微光图像反射分量的恢复图像;
95、每个模块的具体内容为:
96、进入残差连接的多尺度inception模块,分为四路:
97、第一路,直接输出;
98、第二路,经过一个最大池化层,经过一个3×3卷积层,经过一个leakyrelu激活层,经过一个上采样层,经过一个3×3卷积层,经过一个leakyrelu激活层;
99、第三路,经过一个3×3卷积层,经过一个leakyrelu激活层,分为两小路;
100、第四路,经过一个5×5卷积层,经过一个leakyrelu激活层,分为两小路;
101、第三路的第一小路与第四路的第一小路合并,第三路的第二小路与第四路的第二小路合并,经过一个3×3卷积层,经过一个leakyrelu激活层;
102、第一路、第二路、第三路和第四路合并,经过一个1×1卷积层;
103、进入深度残差卷积模块;
104、经过一个3×3卷积层,经过一个leakyrelu激活层,分为两路:
105、第一路,经过一个3×3卷积层,经过一个leakyrelu激活层;
106、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
107、第一路和第二路合并;
108、经过一个3×3卷积层,经过一个leakyrelu激活层,分为两路:
109、第一路,经过一个3×3卷积层,经过一个leakyrelu激活层;
110、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
111、第一路和第二路合并;
112、经过一个3×3卷积层,经过一个leakyrelu激活层,分为两路:
113、第一路,经过一个3×3卷积层,经过一个leakyrelu激活层;
114、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
115、第一路和第二路合并;
116、经过一个3×3卷积层,经过一个leakyrelu激活层,分为两路:
117、第一路,经过一个3×3卷积层,经过一个leakyrelu激活层;
118、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
119、第一路和第二路合并;
120、经过一个3×3卷积层,经过一个leakyrelu激活层,分为两路:
121、第一路,经过一个3×3卷积层,经过一个leakyrelu激活层;
122、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
123、第一路和第二路合并;
124、进入u-net模块;
125、经过第一个3×3卷积层,经过第一个leakyrelu激活层;经过一个最大池化层;
126、经过第二个3×3卷积层,经过第二个leakyrelu激活层;经过一个最大池化层;
127、经过第三个3×3卷积层,经过第三个leakyrelu激活层;
128、经过一个上采样层,与第二个leakyrelu激活层的输出合并;
129、经过第四个3×3卷积层,经过第四个leakyrelu激活层;
130、经过一个上采样层,与第一个leakyrelu激活层的输出合并;
131、经过第五个3×3卷积层,经过第五个leakyrelu激活层;
132、进入高效卷积注意力模块,分为两路:
133、第一路,分为两路:
134、第一路,经过一个全局平均池化层,经过一个1×1卷积层,经过一个leakyrelu激活层,经过一个1×1卷积层;
135、第二路,经过一个全局最大池化层,经过一个1×1卷积层,经过一个leakyrelu激活层,经过一个1×1卷积层;
136、第一路与第二路合并;
137、经过一个sigmoid激活层;
138、第二路,直接输出;
139、第一路和第二路合并,分为两路:
140、第一路,分为两路:
141、第一路,经过一个全局平均池化层;
142、第二路,经过一个全局最大池化层;
143、第一路和第二路合并;
144、经过一个7×7卷积层;
145、经过一个sigmoid激活层;
146、第二路,直接输出;
147、第一路和第二路合并;
148、步骤(4):将微光图像的照明分量ilow(i,j)输入多分支注意力照明分量调节网络进行调整,获得与正常光照图像照明分量ihigh(i,j)相同光照水平的照明分量调节图iadj(i,j);多分支注意力照明分量调节网络由多尺度特征提取模块、注意力调整模块和融合模块组成;三通路并行的反射分量恢复网络在损失函数的约束下进行训练;损失函数为:
149、
150、式中,iadj(i,j)为微光图像的照明分量调节图;
151、多分支注意力照明分量调节框架为:
152、进入多尺度特征提取模块,分为两路:
153、第一路,进入高效卷积注意力模块,分为两路:
154、第一路,进入注意力调整模块;
155、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
156、第一路和第二路合并;
157、第二路,进入多尺度特征提取模块,分为两路:
158、第一路,进入高效卷积注意力模块,分为两路:
159、第一路,进入注意力调整模块;
160、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
161、第一路和第二路合并;
162、第二路,进入多尺度特征提取模块,分为两路:
163、第一路,进入高效卷积注意力模块,分为两路:
164、第一路,进入注意力调整模块;
165、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
166、第一路和第二路合并;
167、第二路,进入多尺度特征提取模块,分为两路:
168、第一路,进入高效卷积注意力模块,分为两路:
169、第一路,进入注意力调整模块;
170、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
171、第一路和第二路合并;
172、第二路,进入多尺度特征提取模块,分为两路:
173、第一路,进入高效卷积注意力模块,分为两路:
174、第一路,进入注意力调整模块;
175、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
176、第一路和第二路合并;
177、第二路,进入多尺度特征提取模块,分为两路:
178、第一路,进入高效卷积注意力模块,分为两路:
179、第一路,进入注意力调整模块;
180、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
181、第一路和第二路合并;
182、第二路,进入多尺度特征提取模块,分为两路:
183、第一路,进入高效卷积注意力模块,分为两路:
184、第一路,进入注意力调整模块;
185、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
186、第一路和第二路合并;
187、第二路,进入多尺度特征提取模块,分为两路:
188、第一路,进入高效卷积注意力模块,分为两路:
189、第一路,进入注意力调整模块;
190、第二路,经过一个1×1卷积层,经过一个leakyrelu激活层;
191、第一路和第二路合并;
192、第一路和第二路合并;
193、第一路和第二路合并;
194、第一路和第二路合并;
195、第一路和第二路合并;
196、第一路和第二路合并;
197、第一路和第二路合并;
198、第一路和第二路合并;
199、每个模块的具体内容为:
200、进入多尺度特征提取模块;
201、经过第一个3×3卷积层,经过第一个prelu激活层,经过第一个批归一化层;经过第二个3×3卷积层,经过第二个prelu激活层,经过第二个批归一化层;经过第三个3×3卷积层,经过第三个prelu激活层,经过第三个批归一化层;第一个批归一化层的输出、第二个批归一化层的输出和第三个批归一化层的输出合并;
202、进入注意力调整模块,分为两路:
203、第一路,经过第一个3×3卷积层,经过第一个prelu激活层,经过第一个批归一化层;经过第二个3×3卷积层,经过第二个prelu激活层,经过第二个批归一化层;经过第三个3×3卷积层,经过第三个prelu激活层,经过第三个批归一化层;第一个批归一化层的输出、第二个批归一化层的输出和第三个批归一化层的输出合并;
204、第二路,经过一个1×1卷积层,经过一个prelu激活层,经过一个批归一化层;
205、第一路和第二路合并,分为两路:
206、第一路,经过第一个3×3卷积层,经过第一个prelu激活层,经过第一个批归一化层;经过第二个3×3卷积层,经过第二个prelu激活层,经过第二个批归一化层;经过第三个3×3卷积层,经过第三个prelu激活层,经过第三个批归一化层;第一个批归一化层的输出、第二个批归一化层的输出和第三个批归一化层的输出合并;
207、第二路,经过一个1×1卷积层,经过一个prelu激活层,经过一个批归一化层;
208、第一路和第二路合并,分为两路:
209、第一路,经过第一个3×3卷积层,经过第一个prelu激活层,经过第一个批归一化层;经过第二个3×3卷积层,经过第二个prelu激活层,经过第二个批归一化层;经过第三个3×3卷积层,经过第三个prelu激活层,经过第三个批归一化层;第一个批归一化层的输出、第二个批归一化层的输出和第三个批归一化层的输出合并;
210、第二路,经过一个1×1卷积层,经过一个prelu激活层,经过一个批归一化层;
211、第一路和第二路合并;
212、经过一个反卷积层,经过一个prelu激活层;
213、经过一个反卷积层,经过一个prelu激活层;
214、步骤(5):所有图像l(i,j)均可分解为反射分量r(i,j)和照明分量i(i,j),图像为:
215、l(i,j)=r(i,j)⊙i(i,j)(18)将三通路并行的反射分量恢复网络输出的反射分量的恢复图像rres(i,j)和多分支注意力照明分量调节网络输出的照明分量调节图iadj(i,j)进行重构就能获得微光图像的增强图像lenhance(i,j),增强图像为:
216、lenhance(i,j)=rres(i,j)⊙iadj(i,j) (19)
217、式中,lenhance(i,j)为微光图像的增强图像。
218、本发明相对于现有技术具有如下的优点及效果:
219、(1)本发明通过一种基于空间感知retinex分解的微光图像多通路并行增强方法对微光图像进行增强,增强结果在6个公共数据集上取得了有参考评价指标得分最优值和无参考评价指标综合得分最优值。实验结果表明本研究方法具有优越性与强大的泛化能力。
220、(2)现有使用u-net网络架构的retinex分解方法没有考虑不同深度网络特征图之间的语义差异,十分容易丢失色彩和细节信息。本发明通过照明水平预测图像引导的多尺度空间感知分解网络完成图像的retinex分解,通过采用多级编码器-解码器的结构与语义深度相关的残差跳跃连接模块,能消除由网络深度造成的语义差异,能提取输入图像多尺度的特征信息以保留丰富的色彩信息与细节结构
221、(3)现有基于深度学习的反射分量恢复网络具有训练时间慢、去噪性能和色彩恢复能力差、细节结构易模糊的缺点。而本发明通过使用三通路并行的反射分量恢复网络,充分发挥深度残差卷积网络、u-net和残差连接的多尺度inception模块的网络性能并结合起来进行综合运用,使恢复结果接近正常光照图像的反射分量,能很好地完成去噪、色彩恢复和细节边缘结构保持的任务,极大提升了恢复网络的性能。
222、(4)现有基于像素值的映射增强方法具有亮度估计不准确、容易产生伪影和过曝现象的缺点。而本发明通过使用多分支注意力照明分量调节网络结构,在特征提取层添加高效卷积注意力机制并在照明水平调整层进行多尺度特征增强以获得符合真实情况和人眼感知的光照水平估计。
223、(5)现有多尺度特征提取模块多采用不同大小卷积核,由于使用了大卷积核卷积层,会导致计算速度变慢、计算资源消耗增加。本发明通过与google-net的inception模块的结合,使用多个小卷积核卷积层替代大卷积核卷积层,从而减少参数量并提高训练速度。
- 还没有人留言评论。精彩留言会获得点赞!