基于回复增强的对话查询生成模型的训练方法及装置
本技术涉及人机对话,特别涉及一种基于回复增强的对话查询生成模型的训练方法、一种计算机可读存储介质、一种计算机设备和一种基于回复增强的对话查询生成模型的训练装置。
背景技术:
1、相关技术中,对话查询生成任务是搜索引擎知识辅助对话系统的关键模块;模型预测的对话查询,将用于从搜索引擎等知识源中获取相关外部知识文档,辅助后续的对话回复生成;现有对话查询生成模型的训练通常是采用人工标注的对话查询数据,微调预训练语言模型以获得最终的对话查询生成模型;但是,人工标注的对话查询数据仍然较为稀缺,而大量公开的无标注对话数据未得到充分利用;并且人工标注数据集的领域受限,模型跨领域泛化能力较弱,导致训练得到的对话查询生成模型的质量一般。
技术实现思路
1、本技术旨在至少在一定程度上解决上述技术中的技术问题之一。为此,本技术的一个目的在于提出一种基于回复增强的对话查询生成模型的训练方法,通过三阶段的模型训练框架,充分利用了对话回复的知识,给予查询生成模型多粒度的训练指导,从而适用于跨领域和低资源场景的对话查询生成,得到更准确的对话查询。
2、本技术的第二个目的在于提出一种计算机可读存储介质。
3、本技术的第三个目的在于提出一种计算机设备。
4、本技术的第四个目的在于提出一种基于回复增强的对话查询生成模型的训练装置。
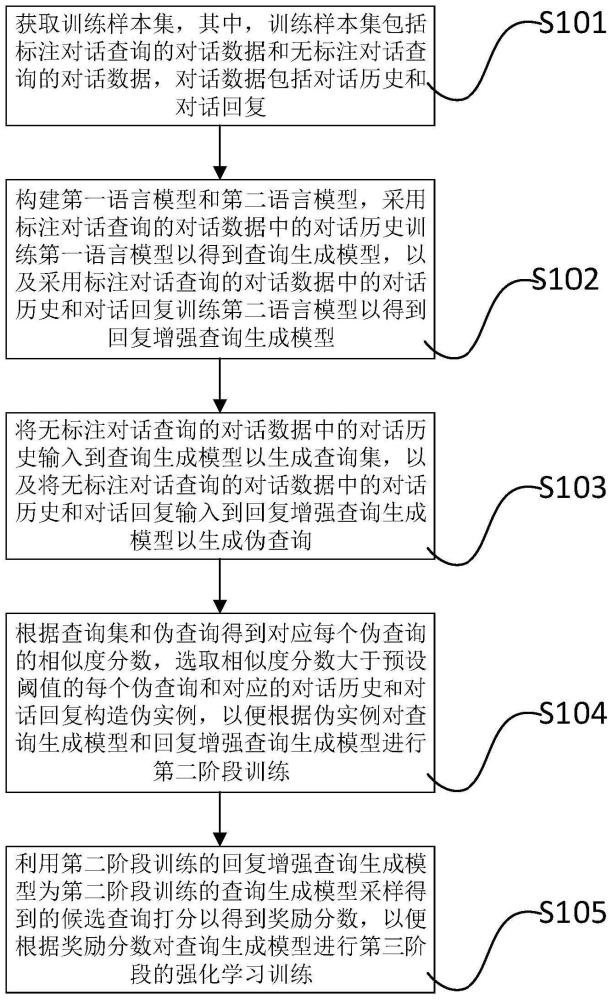
5、为达到上述目的,本技术第一方面实施例提出了一种基于回复增强的对话查询生成模型的训练方法,包括以下步骤:获取训练样本集,其中,所述训练样本集包括标注对话查询的对话数据和无标注对话查询的对话数据,所述对话数据包括对话历史和对话回复;构建第一语言模型和第二语言模型,采用标注对话查询的对话数据中的对话历史训练所述第一语言模型以得到查询生成模型,以及采用标注对话查询的对话数据中的对话历史和对话回复训练所述第二语言模型以得到回复增强查询生成模型;将所述无标注对话查询的对话数据中的对话历史输入到所述查询生成模型以生成查询集,以及将所述无标注对话查询的对话数据中的对话历史和对话回复输入到所述回复增强查询生成模型以生成伪查询;根据所述查询集和所述伪查询得到对应每个伪查询的相似度分数,选取相似度分数大于预设阈值的每个伪查询和对应的对话历史和对话回复构造伪实例,以便根据所述伪实例对所述查询生成模型和所述回复增强查询生成模型进行第二阶段训练;利用所述第二阶段训练的回复增强查询生成模型为所述第二阶段训练的查询生成模型采样得到的候选查询打分以得到奖励分数,以便根据所述奖励分数对所述查询生成模型进行第三阶段的强化学习训练。
6、根据本技术实施例的基于回复增强的对话查询生成模型的训练方法,首先,获取训练样本集,其中,训练样本集包括标注对话查询的对话数据和无标注对话查询的对话数据,对话数据包括对话历史和对话回复;然后,构建第一语言模型和第二语言模型,采用标注对话查询的对话数据中的对话历史训练第一语言模型以得到查询生成模型,以及采用标注对话查询的对话数据中的对话历史和对话回复训练第二语言模型以得到回复增强查询生成模型;接着,将无标注对话查询的对话数据中的对话历史输入到查询生成模型以生成查询集,以及将无标注对话查询的对话数据中的对话历史和对话回复输入到回复增强查询生成模型以生成伪查询;再接着,根据查询集和伪查询得到对应每个伪查询的相似度分数,选取相似度分数大于预设阈值的每个伪查询和对应的对话历史和对话回复构造伪实例,以便根据伪实例对查询生成模型和回复增强查询生成模型进行第二阶段训练;最后,利用第二阶段训练的回复增强查询生成模型为第二阶段训练的查询生成模型采样得到的候选查询打分以得到奖励分数,以便根据奖励分数对查询生成模型进行第三阶段的强化学习训练;由此,通过三阶段的模型训练框架,充分利用了对话回复的知识,给予查询生成模型多粒度的训练指导,从而适用于跨领域和低资源场景的对话查询生成,得到更准确的对话查询。
7、另外,根据本技术上述实施例提出的基于回复增强的对话查询生成模型的训练方法还可以具有如下附加的技术特征:
8、可选地,根据以下公式得到每个伪查询的相似度分数:
9、
10、其中,fsim表示文本相似度函数,表示伪查询,表示查询集中的第x个查询,表示由n个查询构成的查询集,
11、可选地,利用所述第二阶段训练的回复增强查询生成模型为所述第二阶段训练的查询生成模型采样得到的候选查询打分以得到奖励分数,包括:将所述无标注对话查询的对话数据中的对话历史输入到所述第二阶段训练的查询生成模型以生成候选查询集;根据所述候选查询集得到每个候选查询的长度归一化对数概率,对所有候选查询的长度归一化对数概率进行归一化处理,以得到预测概率分布,并将其作为强化学习随机采样策略;将所述无标注对话查询的对话数据中的对话历史和对话回复输入到第二阶段训练的回复增强查询生成模型,以便计算得到每个候选查询对应的长度归一化对数概率,并将所述长度归一化对数概率作为奖励分数。
12、可选地,利用所述第二阶段训练的回复增强查询生成模型为所述第二阶段训练的查询生成模型采样得到的候选查询打分以得到奖励分数,包括:将所述无标注对话查询的对话数据中的对话历史输入到所述第二阶段训练的查询生成模型以生成候选查询集;根据所述候选查询集得到每个候选查询的长度归一化对数概率,对所有候选查询的长度归一化对数概率进行归一化处理,以得到预测概率分布,并将其作为强化学习随机采样策略;将所述无标注对话查询的对话数据中的对话历史和对话回复输入到第二阶段训练的回复增强查询生成模型,以便计算得到每个候选查询对应的长度归一化对数概率;根据所述长度归一化对数概率对所有候选查询进行降序排列,以得到奖励分数。
13、为达到上述目的,本技术第二方面实施例提出了一种计算机可读存储介质,其上存储有基于回复增强的对话查询生成模型的训练程序,该基于回复增强的对话查询生成模型的训练程序被处理器执行时实现如上述的基于回复增强的对话查询生成模型的训练方法。
14、根据本技术实施例的计算机可读存储介质,通过存储基于回复增强的对话查询生成模型的训练程序,以使得处理器在执行该基于回复增强的对话查询生成模型的训练程序时,实现如上述的基于回复增强的对话查询生成模型的训练方法,由此,通过三阶段的模型训练框架,充分利用了对话回复的知识,给予查询生成模型多粒度的训练指导,从而适用于跨领域和低资源场景的对话查询生成,得到更准确的对话查询。
15、为达到上述目的,本技术第三方面实施例提出了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时,实现如上述的基于回复增强的对话查询生成模型的训练方法。
16、根据本技术实施例的计算机设备,通过存储器对基于回复增强的对话查询生成模型的训练进行存储,以使得处理器在执行该基于回复增强的对话查询生成模型的训练程序时,实现如上述的基于回复增强的对话查询生成模型的训练方法,由此,通过三阶段的模型训练框架,充分利用了对话回复的知识,给予查询生成模型多粒度的训练指导,从而适用于跨领域和低资源场景的对话查询生成,得到更准确的对话查询。
17、为达到上述目的,本技术第四方面实施例提出了一种基于回复增强的对话查询生成模型的训练装置,包括:第一获取模块,用于获取训练样本集,其中,所述训练样本集包括标注对话查询的对话数据和无标注对话查询的对话数据,所述对话数据包括对话历史和对话回复;第一训练模块,用于构建第一语言模型和第二语言模型,采用标注对话查询的对话数据中的对话历史训练所述第一语言模型以得到查询生成模型,以及采用标注对话查询的对话数据中的对话历史和对话回复训练所述第二语言模型以得到回复增强查询生成模型;第二获取模块,用于将所述无标注对话查询的对话数据中的对话历史输入到所述查询生成模型以生成查询集,以及将所述无标注对话查询的对话数据中的对话历史和对话回复输入到所述回复增强查询生成模型以生成伪查询;第二训练模块,用于根据所述查询集和所述伪查询得到对应每个伪查询的相似度分数,选取相似度分数大于预设阈值的每个伪查询和对应的对话历史和对话回复构造伪实例,以便根据所述伪实例对所述查询生成模型和所述回复增强查询生成模型进行第二阶段训练;第三训练模块,用于利用所述第二阶段训练的回复增强查询生成模型为所述第二阶段训练的查询生成模型采样得到的候选查询打分以得到奖励分数,以便根据所述奖励分数对所述查询生成模型进行第三阶段的强化学习训练。
18、根据本技术实施例的基于回复增强的对话查询生成模型的训练装置,通过三阶段的模型训练框架,充分利用了对话回复的知识,给予查询生成模型多粒度的训练指导,从而适用于跨领域和低资源场景的对话查询生成,得到更准确的对话查询。
19、另外,根据本技术上述实施例提出的基于回复增强的对话查询生成模型的训练装置还可以具有如下附加的技术特征:
20、可选地,根据以下公式得到每个伪查询的相似度分数:
21、
22、其中,fsim表示文本相似度函数,表示伪查询,表示查询集中的第x个查询,表示由n个查询构成的查询集,
23、可选地,第三训练模块还用于将所述无标注对话查询的对话数据中的对话历史输入到所述第二阶段训练的查询生成模型以生成候选查询集;根据所述候选查询集得到每个候选查询的长度归一化对数概率,对所有候选查询的长度归一化对数概率进行归一化处理,以得到预测概率分布,并将其作为强化学习随机采样策略;将所述无标注对话查询的对话数据中的对话历史和对话回复输入到第二阶段训练的回复增强查询生成模型,以便计算得到每个候选查询对应的长度归一化对数概率,并将所述长度归一化对数概率作为奖励分数。
24、可选地,第三训练模块还用于将所述无标注对话查询的对话数据中的对话历史输入到所述第二阶段训练的查询生成模型以生成候选查询集;根据所述候选查询集得到每个候选查询的长度归一化对数概率,对所有候选查询的长度归一化对数概率进行归一化处理,以得到预测概率分布,并将其作为强化学习随机采样策略;将所述无标注对话查询的对话数据中的对话历史和对话回复输入到第二阶段训练的回复增强查询生成模型,以便计算得到每个候选查询对应的长度归一化对数概率;根据所述长度归一化对数概率对所有候选查询进行降序排列,以得到奖励分数。
- 还没有人留言评论。精彩留言会获得点赞!