具有隐私保护激励的空中计算网络用联邦学习方法及系统
本发明属于联邦学习,特别涉及具有隐私保护激励的空中计算网络用联邦学习方法及系统。
背景技术:
1、随着5g的大规模商业化,无线网络的用户数量和服务需求不断增加。为了满足对覆盖范围、服务质量和通信速度的高要求,研究人员已经开始探索未来6g天地一体化网络的新兴技术和应用。与云计算、边缘计算、大数据、人工智能相结合,网络的传输速率、端到端延迟、可靠性、频谱效率和能耗将显著提高。6g天地一体化网络显示出实现真正意义上的全球覆盖、无处不在的智能和可靠服务的巨大前景。空中计算由于其方便的移动访问、分布式计算、高灵活性和可扩展性,被认为是实现无缝全球覆盖的关键推动者。由互联的无人机(uav)作为空域基础设施和具有强大计算能力和充足资源的云组成的空中网络。空中网络可以为地面网络提供增强的通信和计算服务,特别是在战时通信和灾后救援等极端领域。此外,借助人工智能模型,可以预测网络动态,实现智能决策。例如,当地面基站在灾难发生后被摧毁时,配备ai模型的无人机可以合作提供通信中继服务。然而,在动态和复杂的空中计算网络中构建人工智能模型面临挑战。一方面,无人机的能量和计算资源有限,无法独立完成模型训练。另一方面,在无人机上建立模型——来自网络的海量数据,在传输过程中面临隐私泄露的风险。
2、联邦学习可以在有效构建人工智能模型的同时保护隐私。衡量用户学习质量所需的信息(如数据集分布、位置、计算能力等)在传输过程中可能会被窃听,且这些信息都对隐私敏感。用户的真实成本对于确定激励中的支付是必不可少的,可能会受到推理攻击从而影响激励机制的真实性。为了保护用户隐私并提高联邦学习模型的准确性,本发明研究了空中计算网络中联邦学习的隐私保护和质量感知激励。
技术实现思路
1、本发明的目的在于提供具有隐私保护激励的空中计算网络用联邦学习方法及系统,以解决上述问题。
2、为实现上述目的,本发明采用以下技术方案:
3、第一方面,本发明提供具有隐私保护激励的空中计算网络用联邦学习方法,包括:
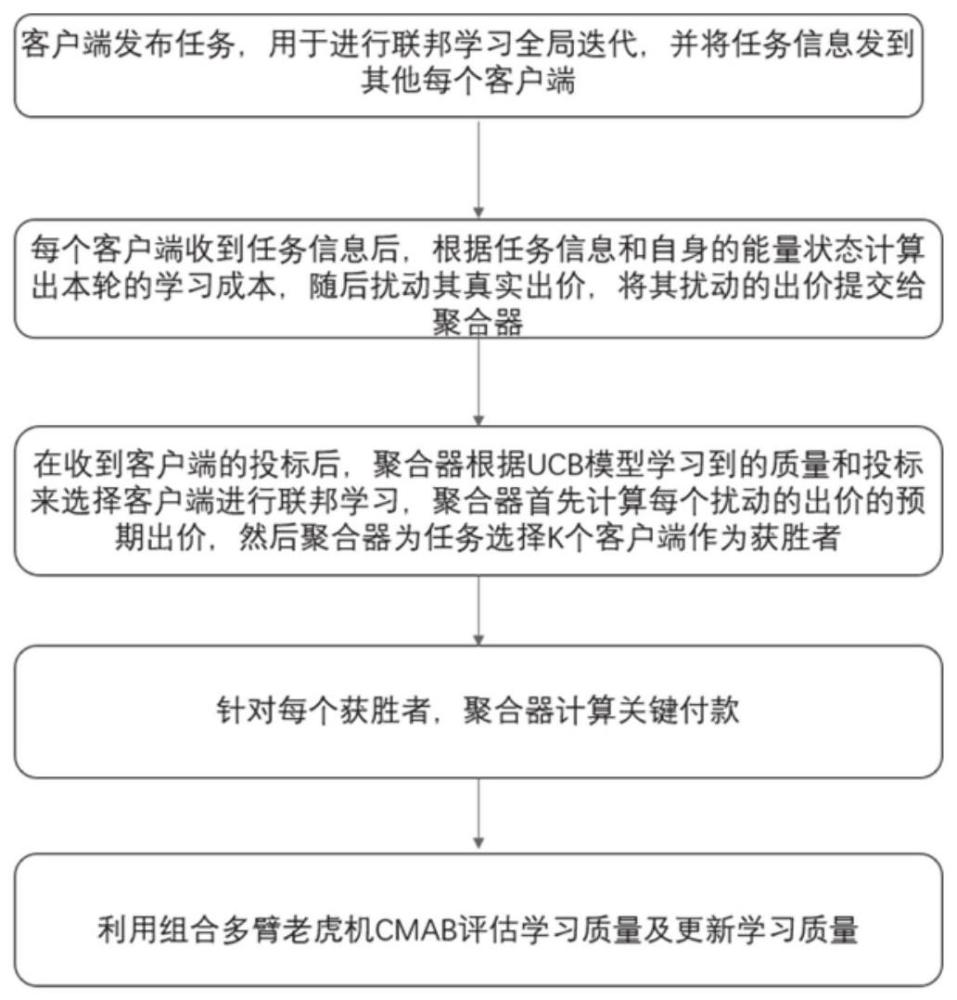
4、客户端发布任务,用于进行联邦学习全局迭代,并将任务信息发到其他每个客户端;
5、每个客户端收到任务信息后,根据任务信息和自身的能量状态计算出本轮的学习成本,随后扰动其真实出价,将其扰动的出价提交给聚合器;
6、在收到客户端的投标后,聚合器根据ucb模型学习到的质量和投标来选择客户端进行联邦学习,聚合器首先计算每个扰动的出价的预期出价,然后聚合器为任务选择k个客户端作为获胜者;
7、针对每个获胜者,聚合器计算关键付款;
8、利用组合多臂老虎机cmab评估学习质量及更新学习质量。
9、可选的,客户端发布任务π(t),对于任务π(t),其任务信息为i(t)={l(t),b(t)},其中l(t)为π(t)所需的数据集类型,b(t)是π(t)的预算。
10、可选的,随后扰动其真实出价,将其扰动的出价提交给聚合器:
11、采用基于差分隐私dp的指数机制来扰动投标,假设对于投标分配空间c,无人机拥有其先验知识;对于任何真实出价cn(t)∈c,指数机制将cn(t)概率映射到c′n(t)∈c,概率为:
12、
13、这里,∈表示分配给扰动投标的隐私预算,g(cn(t),c′n(t))是用于测量cn(t)和c′n(t)之间距离的函数;函数g的灵敏度用δq表示;随着cn(t)和c′n(t)变得更接近,概率增加,g(c′n(t)|cn(t))是关于|cn(t)-c′n(t)|的单调递减函数;
14、将g(c′n(t)|cn(t))定义为:
15、g(cn(t),c′n(t))=-|cn(t)-c′n(t)|1/2
16、灵敏度表示为其中δcn(t)=cn(t)max-cn(t)min是c的范围.对于任何cn(t)∈c,聚合器通过以下等式计算映射概率p(c′n(t)|cn(t)):
17、
18、然后以概率选择随机出价c′n(t)∈c作为扰动出价,并将其提交给聚合器。
19、可选的,聚合器根据ucb模型学习到的质量和投标来选择客户端进行联邦学习,聚合器首先计算每个扰动的出价的预期出价,然后聚合器为任务选择k个客户端作为获胜者:
20、在收到来自参与者的扰动投标后,聚合器以具有成本效益的方式选择一组具有高学习质量的客户;
21、对于任何客户n,使用预期出价来近似估计真实出价cn(t):
22、
23、其中,是投标cn(t)在c中的比例,f(cn(t))是投标cn(t)的频率;
24、然后聚合器根据预期出价和当前学习到的学习质量选择k个客户作为获胜者;k的值由预算b(t)和
25、可选的,具体来说,聚合器将接收到的候选集根据βn(t)的值进行降序排序,得到排序后的候选集:
26、
27、其中,
28、
29、然后客户端在预算约束b(t)下选择n(t)中的前k个客户端作为获胜者集合φ(t),即:
30、
31、可选的,针对每个获胜者,聚合器计算关键付款:
32、每个获胜者n应获得临界值如果任何出价的价值则必须赢得拍卖,否则不会获胜。
33、那么φ(t)中每个获胜者的支付由以下规则确定:
34、
35、可选的,利用组合多臂老虎机cmab评估学习质量及更新学习质量:
36、假设客户n在前t轮中已经被选择了sn(t)次来执行学习任务π;sn(t)的更新规则定义为:
37、
38、其中,使用表示客户端n直到第t轮的样本平均学习质量;的更新规则表示为:
39、
40、其中qn(t)是本轮学习到的质量;客户n的学习质量根据ucb区间来估计
41、
42、
43、其中μn(t)是解决学习质量动态问题的ucb指数;在初始阶段,即t=1时,聚合器将每个客户端n的初始质量设置为1。
44、第二方面,本发明提供具有隐私保护激励的空中计算网络用联邦学习系统,包括:
45、任务发布模块,用于客户端发布任务,用于进行联邦学习全局迭代,并将任务信息发到其他每个客户端;
46、投标确定和扰乱模块,用于每个客户端收到任务信息后,根据任务信息和自身的能量状态计算出本轮的学习成本,随后扰动其真实出价,将其扰动的出价提交给聚合器;
47、获胜者选择模块,用于在收到客户端的投标后,聚合器根据ucb模型学习到的质量和投标来选择客户端进行联邦学习,聚合器首先计算每个扰动的出价的预期出价,然后聚合器为任务选择k个客户端作为获胜者;
48、付款决定模块,用于针对每个获胜者,聚合器计算关键付款;
49、学习质量更新模块,用于利用组合多臂老虎机cmab评估学习质量及更新学习质量。
50、第三方面,本发明提供一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现具有隐私保护激励的空中计算网络用联邦学习方法的步骤。
51、第四方面,本发明提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现具有隐私保护激励的空中计算网络用联邦学习方法的步骤。
52、与现有技术相比,本发明有以下技术效果:
53、本发明提出了一种基于拍卖的激励方案,具有隐私保护和学习质量意识,用于航空计算网络中有效的联邦学习。引入组合多臂老虎机来评估用户的学习质量,无需任何私人信息。此外,本发明使用差异隐私来保护真实的客户端成本免受推断攻击。本发明进一步从理论上证明了所提出的隐私保护激励机制满足真实性、个体理性、预算平衡和cmab的收敛性。仿真结果表明,本发明的方案可以很好地平衡隐私保护和学习准确性提高之间的权衡。
54、本发明提出了一种具有学习质量意识的隐私保护激励机制campra,用于空中计算网络中的联邦学习。在每一轮中,无人机作为聚合器,仅根据用户的学习成本信息自适应地选择高质量的客户端进行学习任务。
55、1.利用组合多臂老虎机(cmab)在没有任何参与者信息的情况下评估学习质量,并实现人工智能模型的高性能。此外,本发明使用差异隐私来保护客户的真实成本隐私。
56、2.从理论上证明了所提出的campra满足真实性、个人理性、预算平衡和cmab遗憾的收敛性。数值结果表明,本发明的campra在隐私保护、学习准确性和学习成本方面优于其他方法。
- 还没有人留言评论。精彩留言会获得点赞!