基于深度学习的藏文古籍多字体文字识别系统
本发明涉及文字识别与处理,特别是涉及基于深度学习的藏文古籍多字体文字识别系统。
背景技术:
1、藏文是公元7世纪吐蕃时期创制的拼音文字,目前主要在我国藏族地区和不丹以及印度、尼泊尔和巴基斯坦部分地区使用。藏文古籍浩如烟海,其内容主要分为声明学、因明学、内明学、工巧明、医方明(大五明)和辞藻学、韵律学、修辞、戏剧、历算(小五明),其数量仅次于汉文典籍,位居全国第二。在众多典籍之中以宗教学、哲学著作居多,具有重要的人文科学研究及应用价值。
2、然后,大部分少数民族文字信息处理仍然处于以字形处理为主的阶段,古籍文献资源的数字化程度普遍不高,对古籍文献的扫描识别研究更是非常缺乏。没有将藏文语言结构及文字构成规律应用于识别技术研究,识别的精度不高,泛化能力薄弱,远远不能满足藏文文献数字化保护和利用的需求,亟待研发高精度、高识别率、高性能的数字化技术。
技术实现思路
1、为了实现上述目的,本发明提供了一种基于深度学习的藏文古籍多字体文字识别系统,以解决藏文识别的精度差,无法满足对藏文文献的数字化需求。
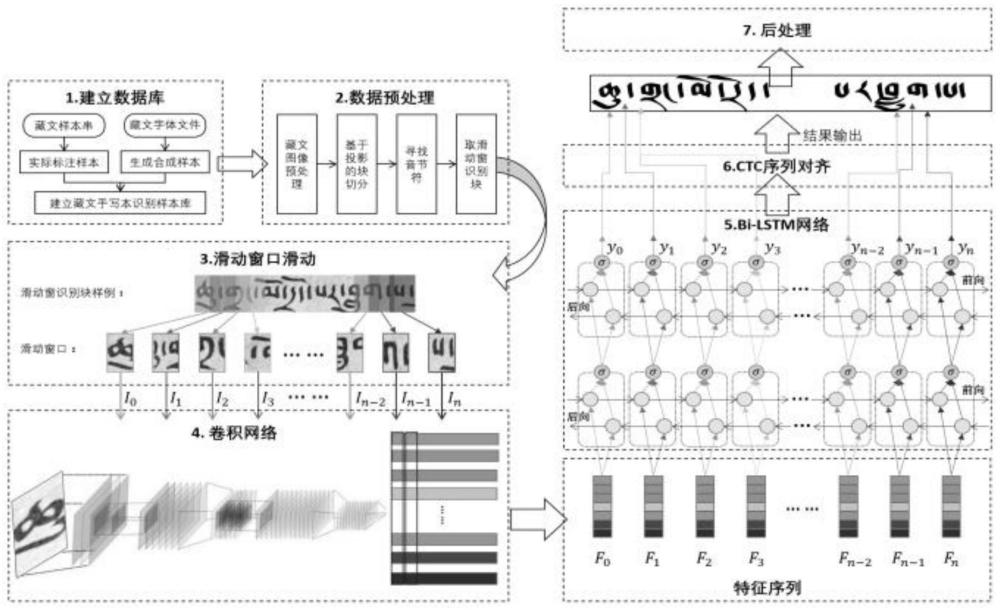
2、本发明提出了基于深度学习的藏文古籍多字体文字识别系统,包括:
3、用于数据集构建与数据预处理和对真实样本进行标注与生成合成样本的预处理模块、基于滑动窗的行识别模块与基于深度学习的串识别模块;
4、所述预处理模块对真实样本进行扫描后同比例缩放,归一化到相同的大小,图像做灰度与拉伸处理,对藏文古籍图像进行位置标注,根据所述位置标注的信息录入文本,以所述位置标注的编号对所述录入文本添加对应的编号,将框选内容与所述录入文本保持一致;
5、所述行识别模块将所述藏文古籍图像做二值化和去噪处理,并计算出所有的连通域,计算出所有连通域块的高度,取高度的中位数作为参考高度,基于参考高度,创建规则判断连通域的尺寸是否符合规则,若不符合,则当成噪声去除;对剩余的所述连通域,以水平方向投影进行切分,获取到若干投影块;
6、所述串识别模块中卷积层采用resnet进行特征提取,循环层采用bi-lstm学习关联序列并预测标签分布;转录层采用ctc做序列对齐,并输出预测结果。
7、进一步地,所述行识别模块包括:滑动窗参数的计算、滑动窗滑动与识别块边界调整。
8、进一步地,滑动窗的两个参数指标分别为宽高比k_window和重叠宽度overlap_width。
9、进一步地,其特征在于,宽高比k_window满足以下关系:
10、k_window=(height_input_layer)/(width_input_layer);
11、其中,height_input_layer和width_input_layer分别为串识别核心输入层对应的图像的高度和宽度。
12、进一步地,其特征在于,重叠宽度overlap_width满足以下关系:
13、overlap_width=k*refheight;
14、其中,k值按照经验取值预设为3,refheight为参考高度。
15、进一步地,其特征在于,所述串识别模块支持的最大字符长度为22。
16、进一步地,其特征在于,所述预处理模块同比例缩放后,归一化为350*48的大小。
17、进一步地,其特征在于,所述串识别模块包括:采用resnet进行藏文古籍文献图像特征提取,根据所述最大字符串长度,由原来的350*48压缩为44*6,送入lstm的timestep为44,经过lstm后,每一个timestep输出的数据维度为2013,所述数据表示timestep对应到2013个类别的概率,每一个timestep取一个最优的类别,将44个类别做合并,获取输入图像对应的串识别结果。
18、进一步地,若所述参考高度小于20,则所述参考高度设置为20。
19、本发明实施例基于深度学习的藏文古籍多字体文字识别系统与现有技术相比,其有益效果在于:
20、采用基于滑动窗口的藏文古籍文本行拆分技术,将超长文本行动态地拆分为多个子识别串,进行基于字符识别位置信息的相邻子串重叠字符处理,解决超长文本行古籍的识别难题;构建基于残差网络和双向长短时记忆循环神经网络的具有高泛化性和鲁棒性的藏文古籍串识别模型,解决图像质量差、相邻文字粘连严重、上下行重叠度大的古籍文字识别难题。
技术特征:
1.基于深度学习的藏文古籍多字体文字识别系统,其特征在于,包括:
2.根据权利要求1所述的基于深度学习的藏文古籍多字体文字识别系统,其特征在于,所述行识别模块包括:滑动窗参数的计算、滑动窗滑动与识别块边界调整。
3.根据权利要求2所述的基于深度学习的藏文古籍多字体文字识别系统,其特征在于,滑动窗的两个参数指标分别为宽高比k_window和重叠宽度overlap_width。
4.根据权利要求3所述的基于深度学习的藏文古籍多字体文字识别系统,其特征在于,宽高比k_window满足以下关系:
5.根据权利要求4所述的基于深度学习的藏文古籍多字体文字识别系统,其特征在于,重叠宽度overlap_width满足以下关系:
6.根据权利要求1所述的基于深度学习的藏文古籍多字体文字识别系统,其特征在于,所述串识别模块支持的最大字符长度为22。
7.根据权利要求2所述的基于深度学习的藏文古籍多字体文字识别系统,其特征在于,所述预处理模块同比例缩放后,归一化为350*48的大小。
8.根据权利要求3所述的基于深度学习的藏文古籍多字体文字识别系统,其特征在于,所述串识别模块包括:采用resnet进行藏文古籍文献图像特征提取,根据所述最大字符串长度,由原来的350*48压缩为44*6,送入lstm的timestep为44,经过lstm后,每一个timestep输出的数据维度为2013,所述数据表示timestep对应到2013个类别的概率,每一个timestep取一个最优的类别,将44个类别做合并,获取输入图像对应的串识别结果。
9.根据权利要求1所述的基于深度学习的藏文古籍多字体文字识别系统,其特征在于,若所述参考高度小于20,则所述参考高度设置为20。
技术总结
本发明涉及文字识别与处理技术领域,公开了基于深度学习的藏文古籍多字体文字识别系统,包括:用于数据集构建与数据预处理和对真实样本进行标注与生成合成样本的预处理模块、基于滑动窗的行识别模块与基于深度学习的串识别模块;本发明基于滑动窗的行识别技术和基于深度学习的串识别技术,解决了图像质量差、文本行较长且文字粘连的藏文古籍文字识别难题。经实验,该技术在现代藏文出版物印刷体识别上其宏平均准确率达到了97.27%,用于藏文古籍木刻本文字识别上宏平均准确率达到92.60%,用于藏文古籍手写本识别上宏平均准确率达到了85.47%,实现了国内外藏文古籍文字识别研究领域的重要突破。
技术研发人员:尼玛扎西,仁青东主,道吉扎西,刘珍正,拥措,韦秋华,仁增多杰,洛桑嘎登
受保护的技术使用者:西藏大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!