医疗语言模型训练方法、医疗问答方法及医疗对话系统与流程
本发明涉及人工智能,尤其涉及一种医疗语言模型训练方法、医疗问答方法及医疗对话系统。
背景技术:
1、在医疗领域,人们开始探索基于医疗语言模型的医疗对话系统。一些研究采用大规模生成式预训练语言模型(large language model meta al,llama)先在指令数据集上进行指令微调,然后在医疗数据上进行学习,使其既拥有遵循用户指令的能力,又熟悉医疗领域的专业知识和语言表述方式。训练后的医疗语言模型不仅能在多轮对话中理解病人的自然语言描述症状,还能根据病情提出检查建议或诊断推测。
2、然而,基于医疗语言模型的医疗对话系统可能输出误导性的医疗建议或误判病情,给病人带来不必要的焦虑,延误最佳治疗时机,甚至危及生命安全。同时,大语言模型也可能生成违背医疗道德或法律的内容,会给病人、医生乃至社会都带来巨大的危害。
技术实现思路
1、本发明提供一种医疗语言模型训练方法、医疗问答方法及医疗对话系统,用以解决现有技术中存在的缺陷。
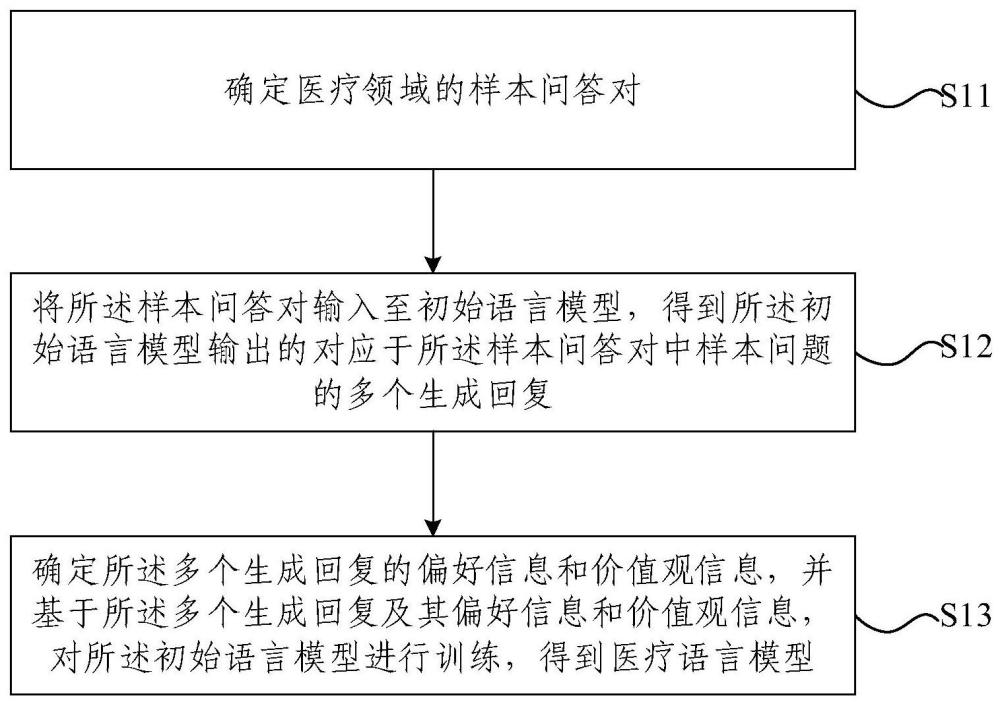
2、本发明提供一种医疗语言模型训练方法,包括:
3、确定医疗领域的样本问答对;
4、将所述样本问答对输入至初始语言模型,得到所述初始语言模型输出的对应于所述样本问答对中样本问题的多个生成回复;
5、确定所述多个生成回复的偏好信息和价值观信息,并基于所述多个生成回复及其偏好信息和价值观信息,对所述初始语言模型进行训练,得到医疗语言模型。
6、根据本发明提供的一种医疗语言模型训练方法,所述样本问题带有不同的提示信息,所述初始语言模型为预训练医疗语言模型;所述基于所述多个生成回复及其偏好信息和价值观信息,对所述初始语言模型进行训练,得到医疗语言模型,包括:
7、将目标提示信息下的目标样本问答对输入至基准模型,得到所述基准模型的多个输出结果,并计算所述目标样本问答对对应的多个生成回复的概率分布与所述多个输出结果的概率分布的kl散度;
8、基于所述目标样本问答对对应的多个生成回复的偏好信息与所述kl散度,计算所述初始语言模型获得的奖励信息;
9、基于所述目标样本问答对对应的多个生成回复的价值观信息,对所述目标样本问答对对应的多个生成回复进行标注;
10、基于不同提示信息下的奖励信息以及多个生成回复的标注信息,对所述初始语言模型进行迭代训练,得到所述医疗语言模型;
11、所述基准模型基于所述初始语言模型的结构参数初始化得到。
12、根据本发明提供的一种医疗语言模型训练方法,所述基于不同提示信息下的奖励信息以及多个生成回复的标注信息,对所述初始语言模型进行迭代训练,得到所述医疗语言模型,包括:
13、基于不同提示信息下的奖励信息,采用近端策略优化算法,对所述初始语言模型进行迭代优化,并在每次迭代过程中将对应的标注信息反馈至当前次迭代得到的模型。
14、根据本发明提供的一种医疗语言模型训练方法,所述样本问题携带有意图信息,所述样本问题的意图信息的确定步骤包括:
15、将所述样本问题输入至分类器,得到所述分类器输出的所述样本问题的意图信息;
16、其中,所述分类器基于携带有意图标签的医疗问题样本训练得到。
17、根据本发明提供的一种医疗语言模型训练方法,所述多个生成回复的偏好信息的确定步骤包括:
18、将所述样本问题的多个生成回复输入至偏好模型,得到所述偏好模型输出的所述样本问题的多个生成回复的偏好信息;
19、其中,所述偏好模型基于携带有偏好标签的医疗样本问答对训练得到,所述医疗样本问答对中的样本问题带有不同的提示信息。
20、根据本发明提供的一种医疗语言模型训练方法,所述多个生成回复的价值观信息的确定步骤包括:
21、将所述样本问题的多个生成回复输入至价值观模型,得到所述价值观模型输出的所述样本问题的多个生成回复的价值观信息;
22、其中,所述价值观模型基于医疗语料信息及其携带的价值观标签训练得到。
23、本发明还提供一种医疗问答方法,包括:
24、获取目标问题;
25、将所述目标问题输入至医疗语言模型,得到所述医疗语言模型输出的所述目标问题对应的目标回复;
26、其中,所述医疗语言模型基于上述的医疗语言模型训练方法训练得到。
27、根据本发明提供的一种医疗问答方法,所述将所述目标问题输入至医疗语言模型,得到所述医疗语言模型输出的所述目标问题对应的目标回复,之后包括:
28、将所述目标回复输入至价值观模型,由所述价值观模型确定所述目标回复的价值观信息,并在所述目标回复的价值观信息为不符合价值观时,向所述医疗语言模型发送目标信号,以使所述医疗语言模型重新输出所述目标问题对应的新回复;
29、将所述新回复输入至所述价值观模型,由所述价值观模型确定所述新回复的价值观信息,并在所述新回复的价值观信息为不符合价值观时,向所述医疗语言模型发送所述目标信号;
30、若由所述价值观模型确定所述医疗语言模型连续多次输出的回复均不符合价值观,则输出所述目标问题对应的模糊回复。
31、根据本发明提供的一种医疗问答方法,所述目标问题携带有意图信息,所述目标问题的意图信息的确定步骤包括:
32、将所述目标问题输入至分类器,得到所述分类器输出的所述目标问题的意图信息;
33、其中,所述分类器基于携带有意图标签的医疗问题样本训练得到。
34、本发明还提供一种医疗语言模型训练装置,包括:
35、确定模块,用于确定医疗领域的样本问答对;
36、第一生成模块,用于将所述样本问答对输入至初始语言模型,得到所述初始语言模型输出的对应于所述样本问答对中样本问题的多个生成回复;
37、训练模块,用于确定所述多个生成回复的偏好信息和价值观信息,并基于所述多个生成回复及其偏好信息和价值观信息,对所述初始语言模型进行训练,得到医疗语言模型。
38、本发明还提供一种医疗问答系统,包括:
39、获取模块,用于获取目标问题;
40、第二生成模块,用于将所述目标问题输入至医疗语言模型,得到所述医疗语言模型输出的所述目标问题对应的目标回复;
41、其中,所述医疗语言模型基于上述的医疗语言模型训练方法训练得到。
42、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述任一种所述的医疗语言模型训练方法或医疗问答方法。
43、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述的医疗语言模型训练方法或医疗问答方法。
44、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述的医疗语言模型训练方法或医疗问答方法。
45、本发明提供的医疗语言模型训练方法、医疗问答方法及医疗对话系统,该训练方法首先确定医疗领域的样本问答对;然后将样本问答对输入至初始语言模型,得到初始语言模型输出的对应于样本问答对中样本问题的多个生成回复;最后确定多个生成回复的偏好信息和价值观信息,并基于多个生成回复及其偏好信息和价值观信息,对初始语言模型进行训练,得到医疗语言模型。该训练方法引入生成回复的偏好信息和价值观信息,并借助于此对初始语言模型进行训练,使得到的医疗语言模型可以具有较好的排序性能及价值观分类性能,可以输出一个最符合语言习惯且较大概率符合价值观的回复内容。
- 还没有人留言评论。精彩留言会获得点赞!