摘要生成方法及其系统与流程
本公开涉及一种摘要生成方法及其系统,更具体而言,涉及一种利用抽象式(abstractive)或生成式(generative)摘要方式生成对原始文本的摘要的方法及其系统。
背景技术:
1、文本摘要方式大致分为抽取式摘要(extractive summarization)和抽象式摘要(abstractive summarization,或生成式摘要)。抽取式摘要方式是从原始文本中抽取关键词或核心句子来创建摘要的方式,抽象式摘要方式是以原始文本的核心上下文为基础生成新的关键词或句子来概况原始文本的方式。当然,据悉抽象式摘要方式的难度比抽取式摘要方式的难度高很多。
2、另外,随着与自然语言处理相关的深度学习技术飞速发展,最近已经提出了通过深度学习模型利用抽象式摘要方式生成摘要的方法。然而,所提出的方法存在无法保障对原始文本的摘要的事实一致性(factual consistency)的问题。即,深度学习模型改变表示原始文本的主要事实关系的关键词(或句子)或者生成表示新的事实关系的关键词(或句子),从而发生歪曲原始文本的重要信息或在原始文本中没有的信息包含在摘要中的问题,这对于精炼原始文本内的重要信息的摘要任务的特性而言认为是相当严重的问题。
3、【现有技术文献】
4、【专利文献】
5、韩国授权专利第10-2022-0043505号(2021.10.07授权)
技术实现思路
1、通过本公开的一些实施例所要解决的技术问题在于提供一种能够利用抽象式(abstractive)或生成式(generative)摘要方式准确地生成针对原始文本的摘要的方法以及执行该方法的系统。
2、通过本公开的一些实施例所要解决的另一技术问题在于提供一种能够准确地生成事实一致性(factual consistency)高的高质量的摘要的方法以及执行该方法的系统。
3、通过本公开的一些实施例所要解决的又一技术问题在于提供一种能够准确地评价摘要模型的与事实一致性相关的性能的方法和评价度量(metric)。
4、本公开的技术问题并不局限于以上所提及的技术问题,未提及的其他技术问题可以通过以下记载被本公开的技术领域中的普通的技术人员明确地理解。
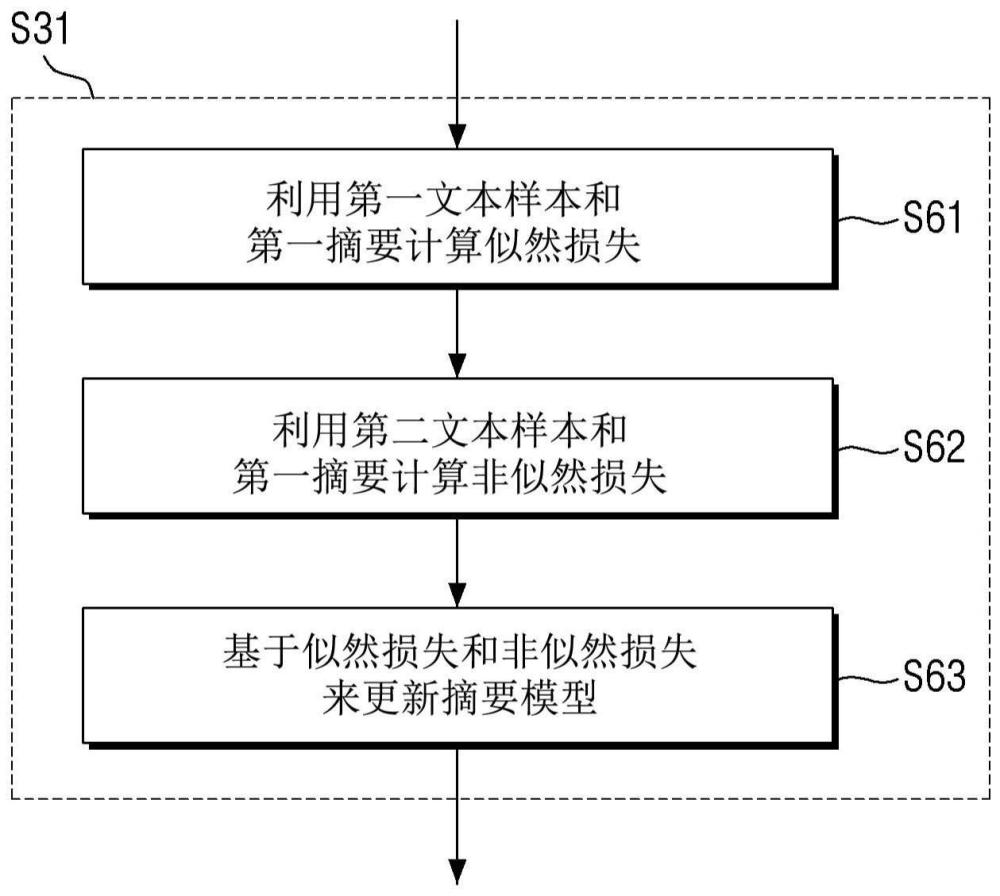
5、用于解决上述技术问题的根据本公开的一些实施例的摘要生成方法作为借由至少一个计算装置执行的方法,可以包括如下步骤:利用第一文本样本和与所述第一文本样本对应的第一摘要来计算针对摘要模型的似然损失(likelihood loss);利用第二文本样本和所述第一摘要来计算针对所述摘要模型的非似然损失(unlikelihood loss),其中,所述第二文本样本为从所述第一文本样本生成的负(negative)样本;以及基于所述似然损失和所述非似然损失来更新所述摘要模型。
6、在一些实施例中,可以基于通过所述摘要模型生成的所述第二文本样本的摘要与所述第一摘要的差异来计算所述非似然损失,并且所述差异越大,所述非似然损失可以计算为更小的值。
7、在一些实施例中,计算所述非似然损失的步骤可以包括如下步骤:从所述第一摘要中抽取主要关键词;以及通过在所述第一文本样本中掩蔽(masking)与所述主要关键词相关联的部分来生成所述第二文本样本。
8、在一些实施例中,所述非似然损失为第一非似然损失,所述摘要生成方法还可以包括如下步骤:通过在所述第一文本样本中去除与所述主要关键词相关联的部分来生成第三文本样本;以及利用所述第三文本样本来计算针对所述摘要模型的第二非似然损失。此时,可以基于所述似然损失、所述第一非似然损失以及所述第二非似然损失来更新所述摘要模型。
9、在一些实施例中,所述似然损失为第一似然损失,所述第二文本样本通过用掩码(mask)词元来替代所述第一文本样本的一部分而生成,并且所述摘要生成方法还可以包括如下步骤:在所述第一文本样本中追加所述掩码词元以生成第三文本样本;以及利用所述第三文本样本和所述第一摘要来计算对所述摘要模型的第二似然损失。此时,可以基于所述第一似然损失、所述第二似然损失以及所述非似然损失来更新所述摘要模型。
10、在一些实施例中,所述摘要模型是预测构成用自回归(auto-regressive)方式输入的文本样本的摘要的词元的模型,所述摘要生成方法还可以包括如下步骤:获取评价用文本样本和评价用摘要,其中,所述评价用文本样本的至少一部分与对应于所述评价用摘要的文本样本不同;将评价用文本样本输入到所述摘要模型以计算针对构成所述评价用摘要的词元的置信度分数(confidence score);以及基于所计算的所述置信度分数评价所述摘要模型的性能。
11、在一些实施例中,所述摘要模型是预测构成用自回归(auto-regressive)方式输入的文本样本的摘要的词元的模型,所述摘要生成方法还可以包括如下步骤:获取评价用文本样本和评价用摘要;通过将所述评价用文本样本输入到所述摘要模型,并通过教师强制(teacher forcing)方法进行解码来预测多个词元,其中,所述教师强制方法通过将所述评价用摘要提供给所述摘要模型的方式来执行;以及比较在预测所述多个词元的过程中出现的对所输入的所述评价用文本样本的所述摘要模型的第一关注度(saliency)和针对所提供的所述评价用摘要的第二关注度来评价所述摘要模型的性能。
12、在一些实施例中,所述摘要模型是预测构成用自回归(auto-regressive)方式输入的文本样本的摘要的词元的模型,所述摘要生成方法还可以包括如下步骤:获取评价用文本样本和评价用摘要,其中,所述评价用文本样本的至少一部分与对应于所述评价用摘要的文本样本不同;通过将所述评价用文本样本输入到所述摘要模型,并通过教师强制(teacher forcing)方法进行解码,从而按词元计算置信度分数(confidence score),其中,所述教师强制方法通过将所述评价用摘要提供给所述摘要模型的方式来执行;以及基于针对按所述词元的置信度分数的熵(entropy)值来评价所述摘要模型的性能。
13、用于解决上述技术问题的根据本公开的另一些实施例的摘要生成方法作为借由至少一个计算装置执行的方法,可以包括如下步骤:利用第一文本样本和第一摘要来计算针对摘要模型的似然损失(likelihood loss);利用第二文本样本和第二摘要来计算针对所述摘要模型的非似然损失(unlikelihood loss),其中,所述第二文本样本与所述第二摘要之间的相关性低于所述第一文本样本与所述第一摘要之间的相关性;以及基于所述似然损失和所述非似然损失来更新所述摘要模型。
14、用于解决上述技术问题的根据本公开的一些实施例的摘要生成系统可以包括一个以上的处理器以及存储有一个以上的指令的存储器,所述一个以上的处理器可以实施所述所存储的一个以上的指令,并且可以执行如下操作:利用第一文本样本和与所述第一文本样本对应的第一摘要来计算针对摘要模型的似然损失(likelihood loss);利用第二文本样本和所述第一摘要来计算针对所述摘要模型的非似然损失(unlikelihood loss),其中,所述第二本文样本是从所述第一文本样本生成的负(negative)样本;以及基于所述似然损失和所述非似然损失来更新所述摘要模型。
15、用于解决上述技术问题的根据本公开的另一些实施例的摘要生成系统可以包括一个以上的处理器以及存储有一个以上的指令的存储器,所述一个以上的处理器可以通过实施所存储的所述一个以上的指令来执行如下操作:利用第一文本样本和第一摘要来计算针对摘要模型的似然损失(likelihood loss);利用第二文本样本和第二摘要来计算针对所述摘要模型的非似然损失(unlikelihood loss),其中,所述第二文本样本与所述第二摘要之间的相关性低于所述第一文本样本与所述摘要之间的相关性;以及基于所述似然损失和所述非似然损失来更新所述摘要模型。
16、用于解决上述技术问题的根据本公开的一些实施例的计算机程序,与计算装置结合,为了实施以下步骤可以存储于计算机的可解读的记录介质,其中,所述步骤包括:利用第一文本样本和与所述第一文本样本对应的第一摘要来计算针对摘要模型的似然损失(likelihood loss);利用第二文本样本和所述第一摘要来计算针对所述摘要模型的非似然损失(unlikelihood loss),其中,所述第二文本样本是从所述第一文本样本生成的负(negative)样本;以及基于所述似然损失和所述非似然损失来更新所述摘要模型。
17、用于解决上述技术问题的根据本公开的另一些实施例的计算机程序,与计算装置结合,为了实施以下步骤可以存储于计算机的可解读的记录介质,其中,所述步骤包括:利用第一文本样本和第一摘要来计算针对摘要模型的似然损失(likelihood loss);利用第二文本样本和第二摘要计算针对所述摘要模型的非似然损失(unlikelihood loss),其中,所述第二文本样本与所述第二摘要之间的相关性低于所述第一文本样本与所述第一摘要之间的相关性;以及基于所述似然损失和所述非似然损失来更新所述摘要模型。
18、根据本公开的一些实施例,通过对摘要模型一起执行基于似然(likelihood)的学习和基于非似然(unlikelihood)的学习,从而可以构建能够准确地生成高质量的摘要的摘要模型。例如,基于似然的学习可以使摘要模型很好地生成被输入的原始文本的主要内容。并且,基于非似然的学习(例如,利用相关性低的文本样本和摘要,以降低似然的方向执行的学习)可以使摘要模型抑制变更被输入的原始文本的主要内容或附加新的内容。
19、并且,利用对事实关系的相关性高的(即,事实一致性高或彼此对应的)文本样本和摘要可以执行基于似然的学习,并且利用对事实关系的相关性低的文本样本和摘要可以执行基于非似然的学习。在这种情况下,可以以变更在被输入的原始文本中表示事实关系的关键词或抑制生成新的关键词的方式学习摘要模型,据此可以显著提高与事实一致性相关的摘要模型的性能。即,可以显著提高对原始文本的摘要的事实一致性。
20、并且,在给出彼此对应的(或相关性高的)第一文本样本和摘要的情况下,从摘要抽取主要关键词,并且从第一文本样本中掩蔽(masking)与主要关键词相关的部分(即,用掩码词元替代),从而可以容易地生成用于基于非似然的学习的负(negative)样本。进一步地,通过多样地设定(例如,词元、词元群、句子、段落级别)掩蔽范围,从而可以容易地生成多种形态的负样本。
21、并且,也可以利用从第一文本样本中去除与主要关键词相关的部分的方式生成负样本。这样生成的负样本可以防止摘要模型将掩码词元的出现与否作为学习基准,从而可以更加提高摘要模型的性能。
22、并且,可以利用在第一文本样本中附加掩码(mask)词元的方式生成正(positive)样本。这样生成的正样本也可以防止摘要模型将掩码词元的出现与否作为学习的基准,从而可以更加提高摘要模型的性能。
23、并且,可以利用基于条件似然、相对关注度(saliency)和/或按解码步骤(step-wise)的熵(entropy)值的度量来准确地评价与事实一致性相关的摘要模型的性能。
24、根据本公开的技术思想的效果并不局限于以上所提及的效果,未提及的其他效果可以通过以下记载被普通的技术人员明确地理解。
- 还没有人留言评论。精彩留言会获得点赞!