一种中文特定领域实体知识库快速构建方法与流程
本技术涉及计算机,尤其是涉及一种中文特定领域实体知识库快速构建方法。
背景技术:
1、中文社交文本命名实体识别(named entity recognition,ner)面临着以下困难:社交文本中含有大量的表情符、无意义链接或符号等强噪声,使实体边界更难区分;非正式文本语法结构不严谨,口语化表述严重,大量缩写词和网络语的出现导致语义的规则性逐渐淡化,进一步削弱了基于词典和规则的实体识别方法的可移植性。
2、早期,基于词典和规则的中文ner方法需要人工建立、设计、维护规则模板和实体词典,耗费大量人力,且词典只针对特定领域可迁移性差。随着统计学在ner中的应用,条件随机场(conditional random fields,crf)、马尔科夫模型(hidden markov model,hmm)、支持向量机(support vector machine,svm)等被广泛应用在ner中,并取得了不错的效果,然而该类方法依然需要人工设计特征模板。近年来,直接从数据中学习特征表示的深度学习方法在命名实体识别领域取得了显着的突破,虽然在一定程度上能够提高实体识别的精度和实用价值,但依然存在很大的局限性。基于深度学习的命名实体识别模型主要基于字符和词语表征特征实现。基于字符特征将字符作为输入进行特征提取,虽然其能够很好的提高实体识别效果,解决词语ovv问题,但忽略了词汇信息蕴含的丰富的语义信息;基于词语特征则将分词后的词语作为输入进行特征提取,但分词错误可能会导致实体边界和实体类别预测错误。词典中由多个汉字组成,除了蕴含丰富的语义信息,同时还能够为中文实体带来边界特征,在字符特征中引入词典特征在实体识别应用中取得了较好的效果。提出了lattice-lstm模型,将字符信息中融合词汇信息,免了分词错误的问题,极大的提升了识别效果。但lattice结构复杂,计算性能低下,不能对batch并行化,为解决这一问题,在中提出了wc-lstm(word-character lstm)模型,该模型取消了lattice结构,仅在词汇末尾的字符信息后面添加词典信息,而未使用词典信息的字符无法获取有效的语义信息,最终会导致wc-lstm模型无法将全部词典信息添加到模型中,缺失部分词汇信息。针对引入词汇信息是有损问题,flat模型设计了position encoding来融合lattice结构,建立字符与所有匹配的词汇信息间的交互,实现信息无损增强,加快了推断速度。
技术实现思路
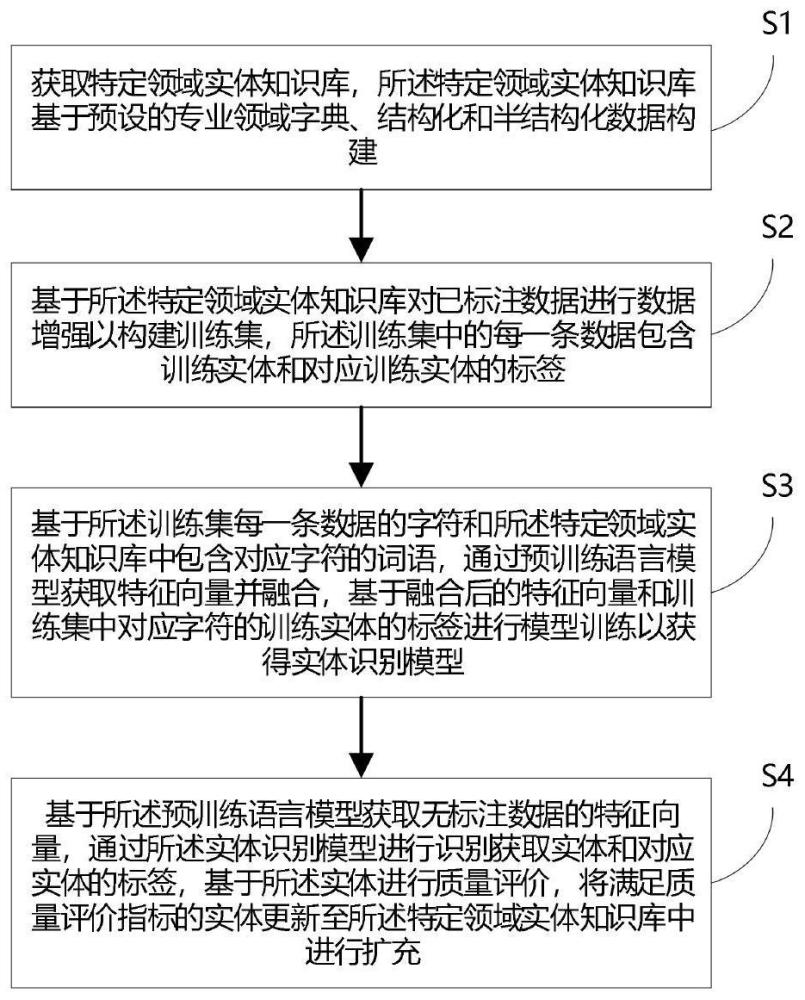
1、为了解决上述技术问题,本技术提供一种中文特定领域实体知识库快速构建方法,包括:
2、s1、获取特定领域实体知识库,所述特定领域实体知识库基于预设的专业领域字典、结构化和半结构化数据构建;
3、s2、基于所述特定领域实体知识库对已标注数据进行数据增强以构建训练集,所述训练集中的每一条数据包含训练实体和对应训练实体的标签;
4、s3、基于所述训练集每一条数据的字符和所述特定领域实体知识库中包含对应字符的词语,通过预训练语言模型获取特征向量并融合,基于融合后的特征向量和训练集中对应字符的训练实体的标签进行模型训练以获得实体识别模型;
5、s4、基于所述预训练语言模型获取无标注数据的特征向量,通过所述实体识别模型进行识别获取实体和对应实体的标签,基于所述实体进行质量评价,将满足质量评价指标的实体更新至所述特定领域实体知识库中进行扩充。
6、在一些具体的实施例中,步骤s2基于所述特定领域实体知识库对已标注的样本数据进行数据增强具体包括:
7、s21、针对已标注数据中的实体和指定标签,获取所述特定领域实体知识库中标注有所述指定标签且与所述已标注数据中的实体长度相同的数据进行替换;
8、s22、针对已标注数据中的每一条数据进行分词,对包含对应标签的实体周围的词语进行位置变换;
9、s23、针对已标注数据中的每一条数据,对数据中除实体数据以外的字符通过预设比例随机插入或删除字符;
10、s24、针对已标注数据中的每一条数据进行分词,对包含对应标签的实体周围的词语进行预设比例的插入和删除;
11、s25、针对已标注数据中的每一条数据进行分词,对不包含对应标签的词语进行词语替换,所述词语替换包括基于预训练词向量选取相似度高的词语进行替换。扩充了训练数据集,并且增强了数据多样性,解决特定领域实体知识库完整性和覆盖度问题。
12、在一些具体的实施例中,步骤s3所述预训练模型包括bert模型。
13、在一些具体的实施例中,步骤s3所述融合后的特征向量基于以下公式获取:
14、cencode=encode(c)
15、mencode=encode(m)
16、xinput=cencode+mencode
17、其中,cencode为所述训练集每一条数据的字符的特征向量,mencode为所述特定领域实体知识库中包含对应字符的词语的特征向量,xinput为融合后的特征向量,其中mencode只和对应的字符的cencode融合。
18、在一些具体的实施例中,步骤s3所述基于融合后的特征向量和训练集中对应字符的训练实体的标签进行模型训练以获得实体识别模型具体包括以下步骤:
19、s31、将所述融合后的特征向量通过卷积层获取特征,并通过结果映射层连接到crf层,表示为:
20、
21、其中,为包含多个标签的特征向量,ht为上一层t时刻融合后的特征向量的输出,w和b为t时刻线性映射参数;
22、s32、基于crf层的标签转义分数矩阵对训练集中所述字符对应数据包含的标签进行优化以获得实体识别模型,表示为:
23、
24、其中,s表示状态转移矩阵,si,j表示标签转义分数,表示该字符第yi个标签的分数,最大化目标函数f。将特定领域实体知识库中的实体也作为模型输入数据训练实体识别模型,增强了特定领域实体知识库中实体的语义信息。
25、在一些具体的实施例中,步骤s4所述通过所述实体识别模型进行识别获取实体和对应实体的标签,所述实体基于bioes编码进行标记。b_*表示实体的第一个位置,i_*表示实体的中间位置,b_loc表示实体的结尾。
26、在一些具体的实施例中,步骤s4基于所述实体进行质量评价具体包括以下步骤:
27、s41、判断所述实体包含b-i-e、b-e或b-i的完整标签,
28、响应于所述实体包含b-i-e、b-e的完整标签,获取所述实体的词性标注在所述特定领域实体知识库中与同类别实体同词性的占比;其中,当所述同类别实体同词性的占比大于第一预设值时,将所述实体更新至所述特定领域实体知识库;当所述同类别实体同词性的占比小于第一预设值时,继续步骤s42;
29、以及响应于所述实体包含b-i的完整标签,获取所述实体与所述特定领域实体知识库中词语的相似度,并基于以下公式计算相似度为前k个词语的平均相似度:
30、
31、其中,m为所述实体,f(m,k)为所述实体与所述特定领域实体知识库中第k个词的相似度,avg(m,k)为所述实体与所述特定领域实体知识库中总共k个词的平均相似度;其中,当所述实体与所述初始实体知识库中总共k个词的平均相似度小于第二预设值时,不更新所述特定领域实体知识库;当所述实体与所述初始实体知识库中总共k个词的平均相似度大于第二预设值时,获取所述实体的词性标注,并计算第k个词的词性与所述实体的词性的重合度:
32、
33、其中,pos(k)表示第k个相似词的词性,pos(m)表示所述实体的词性;当重合度小于第三预设值时不更新所述特定领域实体知识库,当重合度大于第三预设值时继续步骤s42;
34、s42、获取所述实体在非结构化文本中的词频-逆文本频率,当所述词频-逆文本频率小于第四预设值时,不更新所述特定领域实体知识库;当所述词频-逆文本频率大于第四预设值时,基于所述实体对应磁性和实体对应类别,将所述实体更新至所述特定领域实体知识库中。从实体完整性、相似度和信息量三个维度,对实体质量评价以获取高质量的实体更新特定领域实体知识库,为后续实体字典在实体识别中的应用,提升实体识别效果,提供更有效地支撑。
35、根据本发明的第二方面,提出了一种中文特定领域实体知识库快速构建系统,该系统包括:
36、实体知识库构建模块,被配置用于获取特定领域实体知识库,所述特定领域实体知识库基于预设的专业领域字典、结构化和半结构化数据构建;
37、训练集构建模块,被配置用于基于所述特定领域实体知识库对已标注数据进行数据增强以构建训练集,所述训练集中的每一条数据包含训练实体和对应训练实体的标签;
38、模型训练模块,被配置用于基于所述训练集每一条数据的字符和所述特定领域实体知识库中包含对应字符的词语,通过预训练语言模型获取特征向量并融合,基于融合后的特征向量和训练集中对应字符的训练实体的标签进行模型训练以获得实体识别模型;
39、实体知识库扩充模块,被配置用于基于所述预训练语言模型获取无标注数据的特征向量,通过所述实体识别模型进行识别获取实体和对应实体的标签,基于所述实体进行质量评价,将满足质量评价指标的实体更新至所述特定领域实体知识库中进行扩充。
40、根据本发明的第三方面,提出了一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现如第一方面中任一实现方式描述的方法。
41、根据本发明的第四方面,提出了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如第一方面中任一实现方式描述的方法。
42、本发明提出了一种中文特定领域实体知识库快速构建方法,其技术效果在于:
43、通过预设的专业领域字典、结构化和半结构化数据构建特定领域实体知识库即ebkb;同时通过已标注数据构建训练集以获取实体在实际场景应用中的上下文语义信息;ebkb含有实体边界的先验信息,基于ebkb中的实体对已标注数据进行数据增强,增强了数据多样性,解决ebkb完整性和覆盖度问题;为增强ebkb中实体的语义信息,将ebkb中的实体也作为模型输入数据训练实体识别模型,并在大量无标注数据中挖掘潜在实体;并针对挖掘的大量实体,从实体完整性、相似度和信息量三个维度,对实体质量评价以获取高质量的实体更新ebkb,为后续实体字典在实体识别中的应用,提升实体识别效果,提供更有效地支撑。
- 还没有人留言评论。精彩留言会获得点赞!