基于语义理解与自身感知的视频目标分割方法及装置
本发明属于计算机视觉的,具体涉及一种基于语义理解与自身感知的视频目标分割方法及装置。
背景技术:
1、随着计算机视觉和图像处理领域的不断发展,视频对象分割作为一项重要任务得到了广泛研究和应用,旨在从视频序列中准确地分割出感兴趣的对象,这对于视频编辑、计算机视觉应用和人工智能领域具有重要价值。然而,由于视频中的对象可能存在运动、形态和外观上的变化,以及复杂的背景情况,传统的视频目标分割方法在应对这些挑战时表现不佳。目前,现有的视频目标分割方法主要分为两大类:基于检测的方法和基于匹配的方法。基于检测的方法试图通过训练对象检测器来实现分割,但其性能受限于对象检测器的准确度,对于外观变化较大的对象,分割效果不佳。基于匹配的方法则通过匹配当前帧和历史帧的特征来实现分割,这种方法对对象的运动具有较好的鲁棒性,但在处理复杂背景和语义理解方面存在挑战,分割精度有待提高。总结上述讨论,现有的视频目标分割方法在处理快速运动、形态和外观变化较大的对象以及复杂的背景情况时存在一定的局限性。
技术实现思路
1、本发明的主要目的在于克服现有技术的缺点与不足,提供一种基于语义理解与自身感知的视频目标分割方法及装置,提升复杂场景特别是外观变化较大场景下的目标分割表现,同时能够真实地还原出目标的边缘细节,提升分割掩码边界的精确度。
2、为了达到上述目的,本发明采用以下技术方案:
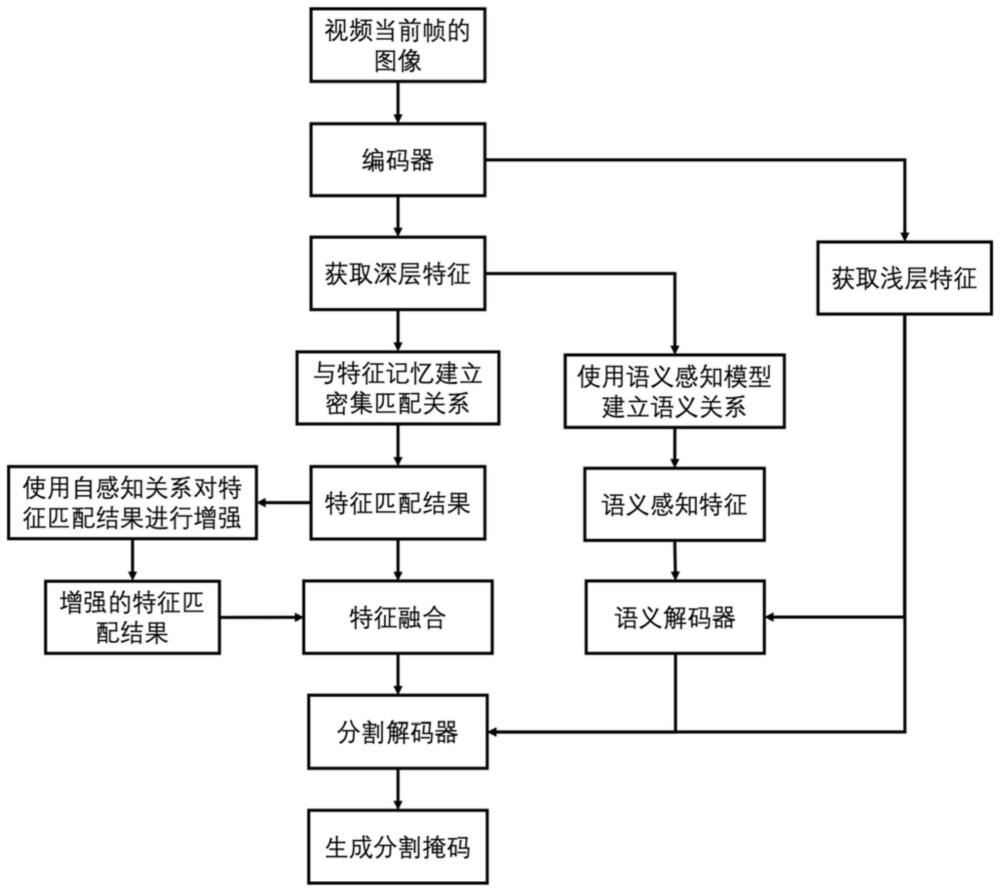
3、第一方面,本发明提供了一种基于语义理解与自身感知的视频目标分割方法,包括下述步骤:
4、采用预设的编码器提取视频当前帧的图像,获取浅层特征与深层特征;
5、对深层特征进行特征嵌入并提取出特征图形成特征序列,然后将特征序列与特征记忆建立密集匹配关系,得到特征匹配结果;接着使用自感知关系对特征匹配结果进行强化,获得增强的特征匹配结果;将特征匹配结果和增强的特征匹配结果进行特征融合,获得融合的特征匹配结果;
6、对深层特征使用语义感知模型提取语义感知特征;所述语义感知模型包括transformer encoder和语义解码器,所述transformer encoder用于建立视频当前帧图像的深层特征中元素之间的语义联系,多次增强后得到语义感知特征;使用语义解码器对语义感知特征和浅层特征进行融合并解码,获取多尺度语义特征;
7、将融合的特征匹配结果、多尺度语义特征和浅层特征输入到分割解码器,获取目标掩码。
8、作为优选的技术方案,所述对深层特征进行特征嵌入并提取出特征图形成特征序列,具体为:
9、使用3×3的滑动窗口在卷积获取的特征图的全局范围内捕获局部特征,并将滑动窗口内的特征展开为1×9的标量作为序列的元素,使得该序列的不同元素代表了不同的局部特征,形成特征序列。
10、作为优选的技术方案,所述将特征序列与特征记忆建立密集匹配关系,具体为:
11、利用交叉注意力机制构建特征序列内的每个元素与特征记忆中所有元素之间的密集匹配,构建当前帧图像与历史帧图像之间的稠密关系;所述交叉注意力机制,如下式:
12、
13、其中,qt表示的是视频序列的第t帧的图像的深度特征,kmem和vmem分别表示来自特征记忆的键值集合keys和特征记忆的数值集合values,dk表示键值的维度,keyproj表示的是将获取的特征图处理为特征序列实现特征嵌入的卷积操作,(keyproj(qt),eys)表示获取视频第t帧图像的查询值与特征记忆中的键值keys之间的相似度。
14、作为优选的技术方案,所述特征记忆包括键值集合keys和数值集合values;所述键值集合keys和数值集合valies通过对视频历史帧的多帧采样获得,具体为:
15、keys={keyproj(qt),=0,5,…}
16、values={valueencoder(keyproj(qt),t),t=0,5,…}
17、其中,qt表示的是视频序列的第t帧的图像的深度特征,keyproj表示的是将获取的特征图处理为特征序列实现特征嵌入的卷积操作,mt表示的是视频序列的第t帧对应的分割掩码,valueencoder表示的是将分割掩码与特征嵌入序列进行融合的编码器。
18、作为优选的技术方案,所述使用自感知关系对特征匹配结果进行强化,具体为:
19、使用全局注意力机制构建特征序列中特征之间的稠密关系,将特征匹配结果作为数值输入到全局注意力机制中,得到增强的特征匹配结果,如下式:
20、
21、其中,qt表示的是视频序列的第t帧的图像的深度特征,dk代表键值的维度,keyproj()表示的是将获取的特征图处理为特征序列实现特征嵌入的卷积操作,rmem表示的是交叉注意力机制输出的特征匹配结果,similarity()表示的是计算视频第t帧图像的查询值与特征记忆中的键值之间的相似度计算。
22、作为优选的技术方案,采用特征融合模块将特征匹配结果和增强的特征匹配结果进行特征融合,融合模块基于卷积注意力模块和resblock模块设计得到。
23、作为优选的技术方案,所述transformer encoder为多层,通过多层transformerencoder的堆叠使用,将语义感知特征和深层语义输出序列转换成隐藏表示,提高捕捉语义感知特征和所述的深层语义输出序列中的复杂关系和语义信息的能力。
24、作为优选的技术方案,所述分割解码器的结构如下:
25、oi=concat(unsample(oi-1)+bi,pi),o0=rself
26、其中,oi表示的是第i层解码模块输出的分割特征,bi表示的编码器输出的浅层特征,pi表示的是第i个尺度的语义特征。
27、第二方面,本发明还提供了一种基于语义理解与自身感知的视频目标分割系统,应用于所述的基于语义理解与自身感知的视频目标分割方法,包括编码模块、第一特征处理模块、第二特征处理模块和解码模块;
28、编码模块,用于采用预设的编码器提取视频当前帧的图像,获取浅层特征与深层特征;
29、第一特征处理模块,用于对深层特征进行特征嵌入并提取出特征图形成第一特征序列,然后将第一特征序列与特征记忆建立密集匹配关系,得到特征匹配结果;接着使用自感知关系对特征匹配结果进行强化,获得增强的特征匹配结果;将特征匹配结果和增强的特征匹配结果进行特征融合,获得融合的特征匹配结果;
30、第二特征处理模块,用于对深层特征使用语义感知模型提取语义感知特征;所述语义感知模型包括transformer encoder和语义解码器,所述transformer encoder用于建立视频当前帧图像的深层特征中元素之间的语义联系,多次增强后得到语义感知特征;使用语义解码器对语义感知特征和浅层特征进行融合并解码,获取多尺度语义特征;
31、解码模块,用于将融合的特征匹配结果、多尺度语义特征和浅层特征输入到分割解码器,获取目标掩码。
32、第三方面,本发明提供了一种电子设备,所述电子设备包括:
33、至少一个处理器;以及,
34、与所述至少一个处理器通信连接的存储器;其中,
35、所述存储器存储有可被所述至少一个处理器执行的计算机程序指令,所述计算机程序指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行所述的基于语义理解与自身感知的视频目标分割方法。
36、本发明与现有技术相比,具有如下优点和有益效果:
37、(1)本发明使用自感知关系对特征匹配结果进行强化,定义了一个自感知匹配机制,利用目标自身特征的相似性,可以增强特征记忆匹配模块,使该模块从特征内存中提取更有效的掩模特征,从而提升分割的效果。
38、(2)本发明利用语义感知模型对深层特征建立语义关系,生成语义感知特征,定义了个语义分支来从查询帧中提取语义理解,为读出解码提供精确的语义指导,大大地增强了语义对象的表达,消除了非语义噪声的干扰,提高了分割器的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!