一种基于上下文学习和大语言模型的Solidity注释生成方法
本发明涉及软件工程,尤其涉及基于上下文学习和大语言模型在注释生成领域的应用。
背景技术:
1、智能合约是运行在区块链技术上的自动执行的数字合约。它们在没有中介机构的情况下自动化、验证和执行协议条款,从而提供了透明度和安全性。然而,研究发现,大多数智能合约代码注释都不可用,这使得开发人员很难理解代码的逻辑、目的和预期功能。此外,智能合约也很容易受到漏洞的影响,因为智能合约代码中使用到大量的代码克隆,而在之前的一项研究中发现10%的漏洞是由代码克隆引起的。如果智能合约代码缺乏解释潜在风险的注释,那么就很难识别和解决安全漏洞,这可能会增加黑客攻击的机会。
2、基于以上分析,为智能合约代码自动生成简洁流畅的注释变得极为重要。目前在智能合约领域,深度学习方法和信息检索方法都有很好的表现。然而,对于基于微调范式的深度学习方法,性能可能会受到下游任务收集的数据集质量的限制,存在知识遗忘问题,这会降低训练模型的泛化性。而对于基于信息检索的方法,如果在历史存储库中不存在类似的智能合同代码,它们就很难生成高质量的注释。因此,急需一种不依赖于微调范式,并且可以自主生成新注释的方法来解决上述问题。
3、在期刊计算机系统应用中的论文《基于神经网络和信息检索的源代码注释生成》也提出信息检索方法的弊端,为了生成高质量的注释,他们将信息检索作为信息增强使用,以此提高深度学习方法的性能。然而这种混合方法仍然依赖于数据集的质量,且知识遗忘和泛化能力差的问题没有得到根本解决。
4、本发明希望利用大型语言模型的新兴能力(如零样本学习和上下文学习)来解决这些问题。大语言模型已经经过了大量数据预训练,并拥有丰富的隐藏领域知识,可以自动生成智能合约注释。然而,仅仅利用大语言模型而不有效地利用其相关的领域知识可能不会产生最佳的结果。
5、如何挖掘出大语言模型在特定领域的潜在知识成为了本发明需要克服的问题。
技术实现思路
1、本发明的目的在于提供基于上下文学习和大语言模型的solidity注释生成方法,该方法克服了信息检索方法不能生成新注释的缺陷,解决了深度学习方法知识遗忘和泛化能力不足的问题,本发明通过检索策略,提供高质量示范构成上下文学习,帮助大语言模型挖掘潜在领域知识,无需训练自动生成更为高质量的solidity代码注释。
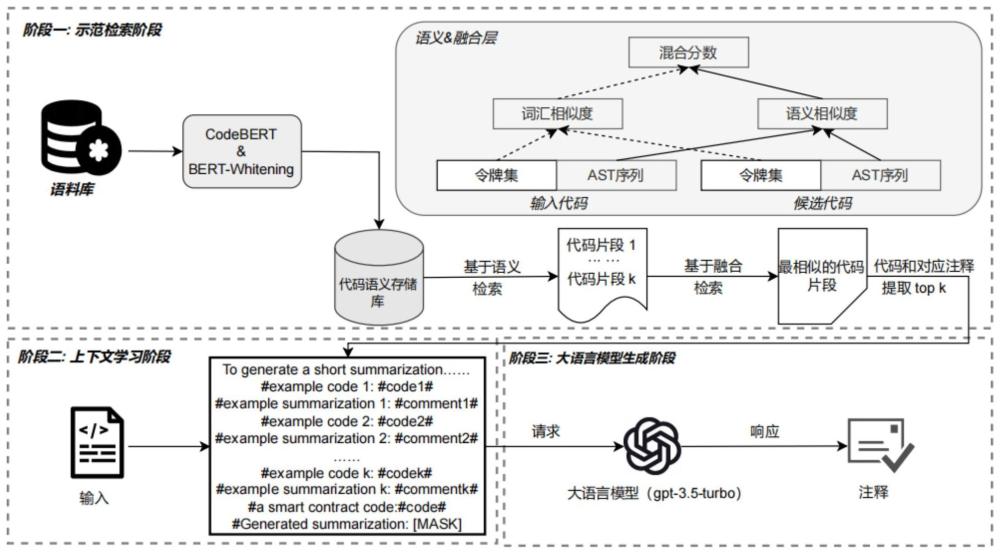
2、本发明包含三个阶段:在第一阶段演示选择阶段采用了一个定制的两阶段检索策略。该策略允许我们从一个历史语料库中检索前k个高质量的演示示例,并考虑到代码片段的语义、词汇和语法信息。随后,在上下文学习阶段,我们利用这些检索到的k个演示来构建一个定制的提示模板。通过整合这些演示,构成上下文学习,有效地利用大语言模型中与智能合约注释生成相关的知识。一旦构建了提示模板,我们就会继续进入大语言模型推理阶段。在这里,我们直接利用大语言模型的接口,提供自定义的提示模板和目标代码片段作为输入。然后,无需任何训练由大语言模型直接生成给定代码片段的相应注释。
3、本发明是通过如下措施实现的:基于上下文学习和大语言模型的solidity注释生成方法,其中,包括以下步骤:
4、(1)在etherscan.io社区收集数据,构成原始语料库。由于语料库中存在大量重复和模板数据导致其质量下降,因此采取预处理操作删除低质量的数据对,使用<代码,摘要>对的形式来标识数据。最后筛选出29,720个<代码,摘要>对作为实验对象。具体预处理操作包括如下步骤:
5、(1-1)首先根据以往研究,删除过短的代码函数,例如函数部分少于4个单词的代码;
6、(1-2)为防止语料库存在过拟合情况,删除代码完全相同的代码对;
7、(1-3)发现拥有不同语义的代码片段,却对应重复的注释,这会导致数据集在检索时出现低质量的示范。使用drop_duplicates函数完成注释去重;
8、(1-4)发现存在模板数据,即由智能合约开发工具自动生成,或开发人员直接进行代码克隆得到的。因此直接删除语料库中严重的模板数据;
9、(2)为大语言模型提供有效的演示示范,可以有效提高其在特定问题上的性能。选择一种结合代码语义、词汇和语法的示范选择策略,从语料库中检索出与目标智能合约solidity代码最相似的前k个代码及其对应注释作为示范,具体包括如下步骤:
10、(2-1)针对目标代码,首先根据camelcase命名约定进行数据处理,将得到的序列用代码预训练模型codebert进行语义信息学习,从而生成对应的语义向量表示。
11、(2-2)使用白化操作进一步处理得到的语义向量,通过提取其中的关键特征,使其空间维度降低。接着计算目标solidity代码与语料库训练集中所有其他语义向量之间的l2距离,推导出语义相似度;最后检索出语义相似度最高的前n个solidity代码片段和其对应注释。
12、(2-3)额外考虑目标solidity代码的词汇和语法信息,从而实现更为准确的检索。首先借助集合表示目标solidity代码和示范solidity代码的令牌。接着基于代码序列,我们去除重复的令牌,得到两个令牌集。最后根据令牌集之间的jaccard相似度得到solidity代码的词汇相似度。
13、(2-4)将目标solidity代码和示范solidity代码转化为抽象语法树序列。为了更好的表示抽象语法树的结构,使用simsbt方法为每个抽象语法树生成新序列。计算新序列之间的编辑距离,得到solidity代码的语法相似度。
14、(2-5)通过融合比例,将solidity代码的词汇相似度和solidity代码的语法相似度融合计算,从前n个示范中,进一步选取出更为相似的前k个示范,完成示范的选取。
15、(3)将检索出的前k个最相似示范与特定的提示词结合,形成提示模板。提示模板中的演示示范和提示构成上下文学习,可以有效挖掘出大语言模型在solidity智能合约领域的潜在知识,具体包括如下步骤:
16、(3-1)首先进行自然语言提示词的构造,告知大语言模型的任务目标为solidity代码注释生成。利用“short”,“in one sentence”等单词限制生成的注释长度,并通过“toalleviate the difficulty of this task,we will give you top-k examples.pleaselearn from them”帮助大语言模型捕获上下文中的示范。
17、(3-2)接着进行代码示范,这部分使用“#”分隔每个示范solidity代码和示范注释,易于大语言模型捕获对应的信息。
18、(3-3)最后进行目标solidity代码的输入,使用“the length should not exceed<comment>”在提示的末尾进一步限制生成注释长度,以避免生成过于冗长的代码注释,其中<comment>是检索到的最相似代码的对应注释。
19、(4)直接调用大语言模型api,将调用代码与提示模板结合,无需任何训练,就可以利用大语言模型api接口直接生成solidity代码注释;本发明选用openai提供的api接口gpt-3.5-turbo版本,其是chatgpt当前的主流版本,该版本使用了更多的训练数据进行大语言模型的训练,因此具有生成效果好和使用成本低的优点。
20、与现有技术相比,本发明的有益效果为:本发明提出了基于上下文学习和大语言模型的solidity注释生成方法,利用定制的演示选择策略来提供高质量的示范,通过上下文学习有效地利用大语言模型中的相关知识进行solidity代码注释生成;实验结果表明,本发明在自动评价和人工评价方面可以显著优于基线;本发明与之前的两种注释生成方法相比,克服了信息检索方法依赖数据集,不能生成新注释的问题,弥补了微调范式存在遗忘先前知识,泛化能力不足的缺陷;本发明首次探索大语言模型在solidity代码注释生成领域的能力,通过上下文学习生成了更加有效,高质量的注释,可以帮助智能合约代码开发人员更加方便,有效的阅读solidity代码。
- 还没有人留言评论。精彩留言会获得点赞!