基于半监督训练提升YOLO检测模型精度方法及系统与流程
本发明涉及计算机,具体而言,涉及一种基于半监督训练提升yolo检测模型精度方法及系统。
背景技术:
1、目前,由于当前的数据标注困难,且浪费大量的人力物力,在具有一些大量无标注数据的场景或特定领域标注数据不足的场景,可以在线学习新出现的未标注样本,使系统在部署后持续改进,适合需要频繁升级的产品,硬件性能受限的移动或边缘设备:能够利用大量无标注数据提升模型性能,适合图像/视频数据量大但标注成本高的应用。需要增量学习的系统:可实现遗忘旧数据、适应新数据分布的增量学习,适合数据集变化较快的应用场景,难以应用。
2、并且现有的检测模型yolov5系列都是采用全监督学习,所有数据都需要人工筛选标记,这就造成了巨大的标注成本,同时限制了数据的数量,面对大型复杂的场景,其标注成本将会指数级上升,而且如果新增种类,又要对所有的数据再次标注,费时费力。速度相对来说在一些计算资源比较缺乏的环境速度会比较慢。标注耗时长,需要大量手工标注数据进行训练,费时费力。数据都是人工筛选,浪费了大量的可使用数据,特别是视频类数据。
技术实现思路
1、本发明的目的在于提供了一种基于半监督训练提升yolo检测模型精度方法及系统,用以解决现有技术中存在的上述问题。
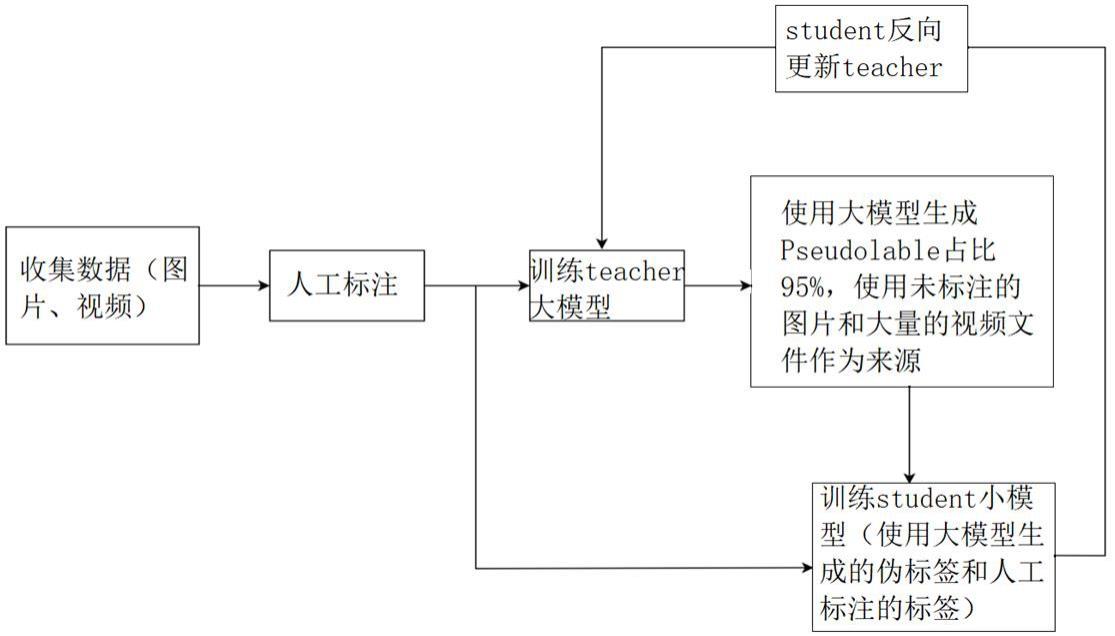
2、第一方面,本发明实施例提供了一种基于半监督训练提升yolo检测模型精度方法,包括:
3、获得无标注数据集和已标注数据集;所述无标注数据集包括多个未标注的数据;所述已标注数据集包括多个已标注的数据;
4、获得教师模型和学生模型;所述教师模型和学生模型的结构相同;
5、根据所述已标注数据集训练教师模型;
6、将所述无标注数据集输入训练好的教师模型,生成伪标签;所述伪标签包括分类分数、回归坐标、置信度分数;
7、基于伪标签,通过伪标签分配机制,得到可靠伪标签和不确定伪标签;
8、基于伪标签、无标注数据集和已标注数据集,训练学生模型,得到训练好的学生模型;
9、基于训练好的学生模型,通过指数移动平均方法,更新教师模型的参数,得到更新的教师模型。
10、可选的,所述基于伪标签,通过伪标签分配机制,得到可靠伪标签和不确定伪标签,包括:
11、若所述伪标签的置信度分数大于阈值,将所述伪标签设为可靠伪标签;
12、若所述伪标签的置信度分数小于或等于阈值,将所述伪标签设为不确定伪标签。
13、可选的,所述基于伪标签、无标注数据集和已标注数据集,训练学生模型,得到训练好的学生模型,包括:
14、基于已标注数据集,进行监督学习,训练学生模型;
15、基于无标注数据集和对应的伪标签,训练已标注数据集训练过的学生模型,得到训练好的学生模型。
16、可选的,所述基于无标注数据集和对应的伪标签,训练已标注数据集训练过的学生模型,得到训练好的学生模型,包括:
17、获得可靠数据集;所述可靠数据集包括多个可靠伪标签对应的数据;
18、将可靠数据集作为正样本输入学生模型,得到可靠输出值;
19、将可靠输出值与对应的可靠伪标签计算损失,进行监督学习,训练学生模型;
20、获得不确定数据集;所述不确定数据集包括多个不确定伪标签对应的数据;
21、将不确定数据集输入学生模型,得到不确定输出值;
22、将输出值与对应的不确定伪标签进行置信度分支的软损失训练学生模型。
23、可选的,所述基于训练好的学生模型,通过指数移动平均方法,更新教师模型的参数,得到更新的教师模型,包括:
24、所述教师模型的参数的更新公式如下述所示:
25、θt2 =α*θt1+ (1 - α)*θs,
26、其中,θt2为更新后的教师模型的参数,θt1为更新前的教师模型的参数,θs为学生模型的参数,α为平滑系数。
27、可选的,根据更新的教师模型生成新的伪标签,重复训练学生模型和教师模型。
28、可选的,所述无标注数据集中的数据的数量除以已标注数据集与无标注数据集中的数据的总数为0.95;
29、所述已标注数据集中的数据的数量除以已标注数据集与无标注数据集中的数据的总数为0.05。
30、可选的,通过端到端训练策略,将所述无标注数据集和已标注数据集进行域自适应和分布自适应,训练教师模型和学生模型。
31、可选的,结束更新的教师模型为能够进行部署的教师模型。
32、第二方面,本发明实施例提供了一种基于半监督训练提升yolo检测模型精度系统,包括:
33、标注模块:获得无标注数据集和已标注数据集;所述无标注数据集包括多个未标注的数据;所述已标注数据集包括多个已标注的数据;
34、获得教师模型和学生模型;所述教师模型和学生模型的结构相同;
35、教师模型训练模块:根据所述已标注数据集训练教师模型;
36、伪标签生成模块:将所述无标注数据集输入训练好的教师模型,生成伪标签;所述伪标签包括分类分数、回归坐标、置信度分数;基于伪标签,通过伪标签分配机制,得到可靠伪标签和不确定伪标签;
37、学生模型训练模块:基于伪标签、无标注数据集和已标注数据集,训练学生模型,得到训练好的学生模型;
38、学生模型反向更新教师模型:基于训练好的学生模型,通过指数移动平均方法,更新教师模型的参数,得到更新的教师模型。
39、相较于现有技术,本发明实施例达到了以下有益效果:
40、本发明实施例还提供了一种基于半监督训练提升yolo检测模型精度方法和系统,所述方法包括:获得无标注数据集和已标注数据集。所述无标注数据集包括多个未标注的数据。所述已标注数据集包括多个已标注的数据。获得教师模型和学生模型。所述教师模型和学生模型的结构相同。根据所述已标注数据集训练教师模型。将所述无标注数据集输入训练好的教师模型,生成伪标签。所述伪标签包括分类分数、回归坐标、置信度分数。基于伪标签,通过伪标签分配机制,得到可靠伪标签和不确定伪标签。基于伪标签、无标注数据集和已标注数据集,训练学生模型,得到训练好的学生模型。基于训练好的学生模型,通过指数移动平均方法,更新教师模型的参数,得到更新的教师模型。
41、本发明提出了使用teacher-student策略,先用大模型大量生成伪标签,再用小模型去学习伪标签,可以显著减少人工标注量,降低标注耗时,同时大大提高了训练数据数量和质量。使用知识蒸馏,让小模型去模仿大模型的预测结果(软标签),从而获得较好的检测性能。小模型和大模型相互学习相互促进。总体来说,本技术主要从降低计算成本、减少人工标注、提高小目标检测几个维度对yolov5进行改进,使其成为一个高效且实用的检测框架。
42、本发明提出的一个新的伪标签分配机制(pseudo label assigner),使yolov5一阶段基于anchor的半监督目标检测训练更稳定高效。它能防止大量低质量伪标签的偏差,充分利用大量未标注的数据,使模型在师生互学习中学习到全局一致的特征,使训练过程不依赖标签数据的比例。区分伪标签的可靠性,减少不一致的负面影响。objectness分支用于评估伪标签质量。ema使教师相对稳定,伪标签质量更好。实验结果显示该技术在voc、coco标准集和额外数据上都取得了不错的性能提升。
- 还没有人留言评论。精彩留言会获得点赞!