一种基于稀疏向量技术的隐私数据蒸馏方法及装置
本发明属于数据处理,具体涉及一种基于稀疏向量技术的隐私数据蒸馏方法及装置。
背景技术:
1、数据蒸馏旨在将原始真实数据集压缩成一个微小的合成数据集,同时尽可能多的保留原始数据集的数据效用以训练高性能的下游深度学习模型。数据蒸馏能够以较低的计算开销、有限的存储资源、较少的硬件需求保持卓越的数据质量。常见的数据蒸馏方法包括:梯度匹配、训练轨迹匹配和分布匹配等。通过梯度匹配学习的合成数据集存在极度偏向大梯度样本的可能性,从而降低了合成数据集的泛化能力,训练轨迹匹配过程极度耗时,而利用分布匹配蒸馏合成数据集的过程能够以较低的计算开销有效捕获完整的数据分布特征。
2、现有技术方案及其缺陷如下:
3、现有技术1提出了一种蒸馏数据的方法、介质及视觉任务处理方法(专利号:cn116541763a):该发明首先从第一数据集、第二数据集中分别采样,得到第一样本数据、第二样本数据,然后通过n次迭代,对第一数据集进行更新。其中初始的第一数据集由第二数据集随机采样得到。每次迭代则首先通过特征提取模块分别提取第一样本数据及第二样本数据的特征,得到第一特征、第二特征,然后计算第一特征与第二特征的差异,并将其作为监督信号进行反向传播,更新第一数据集。尽管现有技术1能够通过仅优化少量样本数据而非模型本身的方式有效缓解传统数据生成方法面临的模型训练复杂的问题,但是在优化数据的过程中,一方面,蒸馏出的第一数据集可能记住关于第二数据集的某些敏感信息,从而带来无意识的隐私泄露风险。另一方面,攻击者可能直接对数据蒸馏过程发起攻击,重构或推断第二数据集,直接为第二数据集带来隐私威胁。
4、现有技术2提出了一种数据集蒸馏方法、装置、电子设备及存储介质(专利号:cn11860572a):该发明针对待处理的原始数据集,随机初始化n个蒸馏数据,n为大于一的正整数。然后利用原始数据集及n个蒸馏数据训练数据真实性判别模型,根据数据真实性判别模型对n个蒸馏数据进行更新;利用n个蒸馏数据训练分类模型,分类模型为对应于原始数据集对应的分类任务的分类模型,根据原始数据集及分类模型对n个蒸馏数据进行更新;若确定符合终止条件,则将最新得到的n个蒸馏数据作为所需的数据集蒸馏结果,否则,重复执行所述预定处理。该发明致力于使用某一特定模型优化原始数据集和蒸馏数据之间的差异,其在为数据蒸馏过程提供充分的、有关原始数据的信息方面存在局限性。此外,蒸馏出的数据的质量高度依赖于训练模型的选择,基于不同训练模型优化的蒸馏数据质量差异较大,甚至影响下游任务的分类准确性。
技术实现思路
1、为了解决现有技术中存在的上述问题,本发明提供了一种基于稀疏向量技术的隐私数据蒸馏方法及装置。本发明要解决的技术问题通过以下技术方案实现:
2、第一方面,本发明提供了一种基于稀疏向量技术的隐私数据蒸馏方法包括:
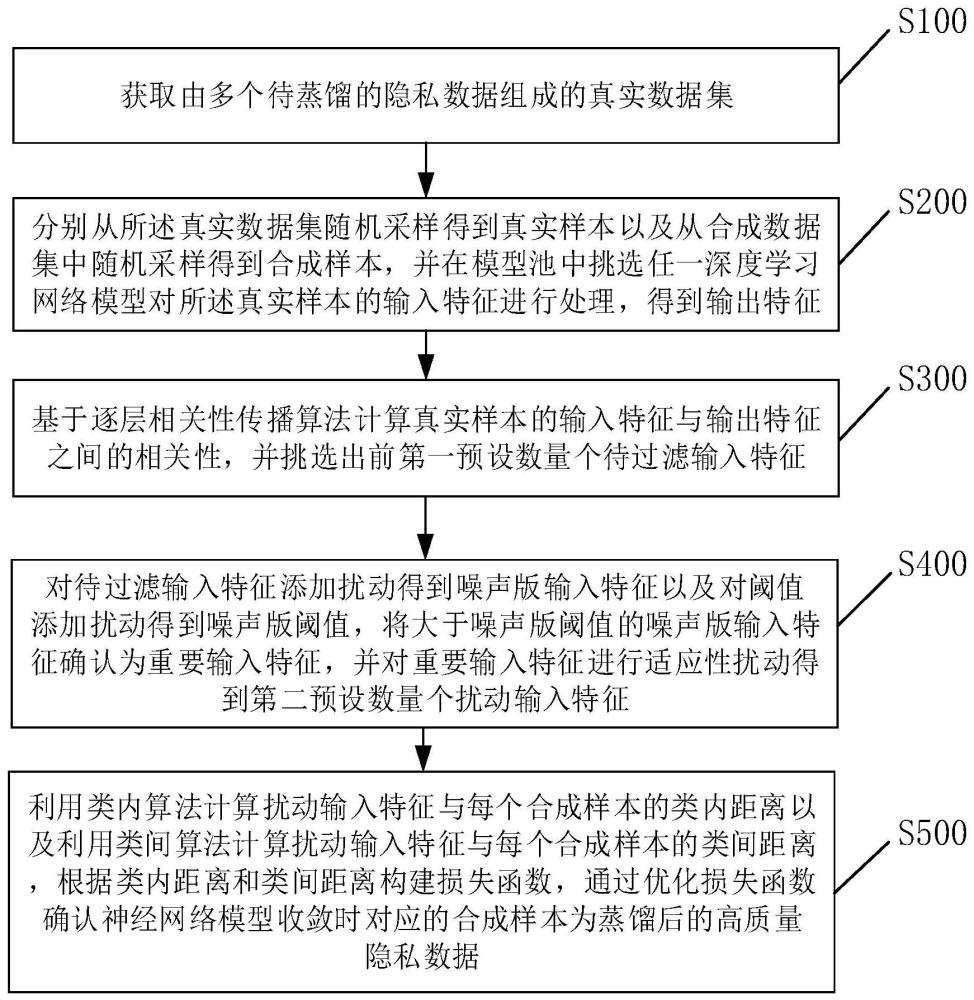
3、s100,获取由多个待蒸馏的隐私数据组成的真实数据集;
4、s200,分别从所述真实数据集随机采样得到真实样本以及从合成数据集中随机采样得到合成样本,并在模型池中挑选任一深度学习网络模型对所述真实样本的输入特征进行处理,得到输出特征;
5、s300,基于逐层相关性传播算法计算所述真实样本的输入特征与输出特征之间的相关性,并挑选出前第一预设数量个待过滤输入特征;
6、s400,对所述待过滤输入特征添加扰动得到噪声版输入特征以及对阈值添加扰动得到噪声版阈值,将大于所述噪声版阈值的噪声版输入特征确认为重要输入特征,并对所述重要输入特征进行适应性扰动得到第二预设数量个扰动输入特征;
7、s500,利用类内算法计算扰动输入特征与每个所述合成样本的类内距离以及利用类间算法计算扰动输入特征与每个所述合成样本的类间距离,根据所述类内距离和所述类间距离构建损失函数,通过优化损失函数确认神经网络模型收敛时对应的合成样本为蒸馏后的高质量隐私数据。
8、第二方面,本发明提供了一种基于稀疏向量技术的隐私数据蒸馏装置包括:
9、获取模块,被配置为获取由多个待蒸馏的隐私数据组成的真实数据集;
10、采样模块,被配置为分别从所述真实数据集随机采样得到真实样本以及从合成数据集中随机采样得到合成样本,并在模型池中挑选任一深度学习网络模型对所述真实样本的输入特征进行处理,得到输出特征;
11、选择模块,被配置为基于逐层相关性传播算法计算所述真实样本的输入特征与输出特征之间的相关性,并挑选出前第一预设数量个待过滤输入特征;
12、扰动模块,被配置为对所述待过滤输入特征添加扰动得到噪声版输入特征以及对噪声添加扰动得到噪声版阈值,将大于所述噪声版阈值的噪声版输入特征确认为重要输入特征,并对所述重要输入特征进行适应性扰动得到第二预设数量个扰动输入特征;
13、蒸馏模块,被配置为利用类内算法计算扰动输入特征与每个所述合成样本的类内距离以及利用类间算法计算扰动输入特征与每个所述合成样本的类间距离,根据所述类内距离和所述类间距离构建损失函数,通过优化损失函数确认神经网络模型收敛时对应的合成样本为蒸馏后的高质量隐私数据。
14、有益效果:
15、本发明提供了一种基于稀疏向量技术的隐私数据蒸馏方法及装置,通过构建由多个已初始化神经网络模型组成的模型池,在每次神经网络模型迭代过程中,通过从模型池中随机挑选训练模型进行数据蒸馏,以从原始数据中蒸馏出更加丰富的信息,提高合成数据质量,并增强蒸馏数据在下游任务中的泛化能力。然后构建双层特征分布匹配,同时基于小批量类内样本和小批量类间样本优化真实数据和合成数据特征分布之间的损失,进一步提升合成数据的质量。针对蕴含敏感信息的隐私原始数据,本发明基于逐层相关性传播算法计算每个隐私数据的输入特征对神经网络模型输出结果的贡献度,依据贡献度的高低,识别重要输入特征。然后基于稀疏向量技术有选择地扰动部分对模型输出结果贡献度大的输入特征,在保护原始真实数据中蕴含的敏感信息的同时,以较低的隐私开销提升数据蒸馏模型的准确性。
16、以下将结合附图及实施例对本发明做进一步详细说明。
技术特征:
1.一种基于稀疏向量技术的隐私数据蒸馏方法,其特征在于,包括:
2.根据权利要求1所述的基于稀疏向量技术的隐私数据蒸馏方法,其特征在于,所述模型池中包含多个已初始化的深度神经网络模型;每次模型迭代过程中,从所述模型池中随机挑选一个深度神经网络模型展开训练。
3.根据权利要求2所述的基于稀疏向量技术的隐私数据蒸馏方法,其特征在于,s200包括:
4.根据权利要求1所述的基于稀疏向量技术的隐私数据蒸馏方法,其特征在于,s300包括:
5.根据权利要求4所述的基于稀疏向量技术的隐私数据蒸馏方法,其特征在于,s310中所述深度学习网络模型由输入层、l个隐藏层和输出层构成,l取值从1起始,神经元p在神经网络的第l层,p∈hl,h表示神经网络的隐藏层,所述深度学习网络模型输出层的输出变量为o,最后一个隐藏层的神经元p与输出特征fx的相关性表示神经元q在神经网络的第l-1层,神经元p传递给第l-1层神经元q的消息表示为前一层中每个神经元的相关性等于所有后续层的总体相关性,所以神经元q的相关性表示为其中消息x表示真实样本,参数μ用来克服相关性的无界性,zqp(x)=qxωqp,表示神经元p的仿射变换,ωqp为连接神经元p和q的权重,bp为偏差项;
6.根据权利要求5所述的基于稀疏向量技术的隐私数据蒸馏方法,其特征在于,所述真实样本的输入特征的平均相关性表示为:
7.根据权利要求4所述的基于稀疏向量技术的隐私数据蒸馏方法,其特征在于,在所述s330之后,所述隐私数据蒸馏方法还包括:
8.根据权利要求7所述的基于稀疏向量技术的隐私数据蒸馏方法,其特征在于,s400包括:
9.根据权利要求1所述的基于稀疏向量技术的隐私数据蒸馏方法,其特征在于,s500包括:
10.一种基于稀疏向量技术的隐私数据蒸馏装置,其特征在于,包括:
技术总结
本发明提供了一种基于稀疏向量技术的隐私数据蒸馏方法及装置,通过构建模型池,在迭代过程中通过从模型池中随机挑选训练模型进行数据蒸馏,以从隐私数据中蒸馏出更加丰富的信息,提高合成数据质量,并增强蒸馏数据在下游任务中的泛化能力。然后利用类间和类内算法优化真实数据和合成数据特征分布之间的损失,进一步提升合成数据的质量。此外,本发明基于逐层相关性传播算法计算每个隐私数据的输入特征对神经网络模型输出结果的贡献度,依据贡献度的高低,识别重要输入特征。然后基于稀疏向量技术有选择地扰动部分对模型输出结果贡献度大的输入特征,在保护原始真实数据中蕴含的敏感信息的同时,以较低的隐私开销提升数据蒸馏模型的准确性。
技术研发人员:潘珂,公茂果,李晖,王善峰
受保护的技术使用者:西安电子科技大学
技术研发日:
技术公布日:2024/2/1
- 还没有人留言评论。精彩留言会获得点赞!