一种基于用户行为序列的异常检测方法及装置与流程
本发明涉及异常检测,尤其涉及一种基于用户行为序列的异常检测方法及装置。
背景技术:
1、近些年,伴随着计算机技术的发展,各行各业的业务系统、操作系统等也在飞速增长,伴随而来的攻击手段也呈现出多元化发展趋势,一些传统的安全措施仅适用于传统的安全需求,在当前日益复杂的网络环境中,它们的有效性逐渐减弱。如何能快速准确的挖掘出攻击威胁、恶意用户、恶意行为等也逐渐变得越来越困难。网站攻击、窃取企业内部数据等恶意行为通过各种伪装手段,隐匿在大量日常正常的行为操作中,对个人、企业、社会都造成了较为严重的不良影响和极大的危害。
2、目前用户行为序列异常检测主要通过对用户的操作行为进行一些统计特征的构建,利用聚类算法对用户进行分类,进而根据业务经验,归并异常用户所在的簇;或者通过训练历史行为模式构建markov(马尔可夫)模型,利用模型计算用户的行为异常分值;或者通过序列间的关系,利用关联规则计算用户行为序列的异常情况。现有的用户行为序列异常检测方法存在些许不足,具体如下:
3、通过构建用户操作行为的统计特征,建立聚类模型,利用业务经验,识别异常用户。这类方法一般只能捕捉到用户行为统计特征上的信息如操作次数过高、波动较大等,很难捕捉到行为序列中存在的异常,其次对业务经验依赖较高。通过训练历史行为模式构建马尔可夫模型,计算用户的行为序列的概率,把该概率值作为判断用户行为是否异常的标准。通过该种方式虽然在一定程度上能捕捉到部分行为序列异常的用户,这种方法对序列中子序列是否异常并不敏感,同时可能会受到序列长度的影响,从而造成误报、漏报的问题。通过计算用户间的相似度或者关联规则,计算量比较大,效率比较低。
4、公开号为cn112738088a的中国发明专利申请《一种基于无监督算法的行为序列异常检测方法及系统》基于企业web系统操作数据,通过用户操作的先后顺序,计算两次操作的时间间隔,根据两次操作的时间间隔是否大于预设阈值,对用户行为序列进行分割,进而训练概率后缀树模型,根据概率后缀树模型输出用户行为序列对应的概率值,将用户对应的概率值作为特征即孤立森林模型的输入,根据模型输出结果判断用户行为是否异常。但是该方法是通过预设阈值分割用户的操作行为,不管是pst还是孤立森林对参数都有一定的要求,如pst要求预设阶数,阶数的设置对准确率有一定的影响。
技术实现思路
1、本发明所要解决的技术问题在于如何解决异常用户检测时准确率低、误报率高、漏报率高、效率低等问题。
2、本发明是通过以下技术方案解决上述技术问题的:一种基于用户行为序列的异常检测方法,包括以下步骤:
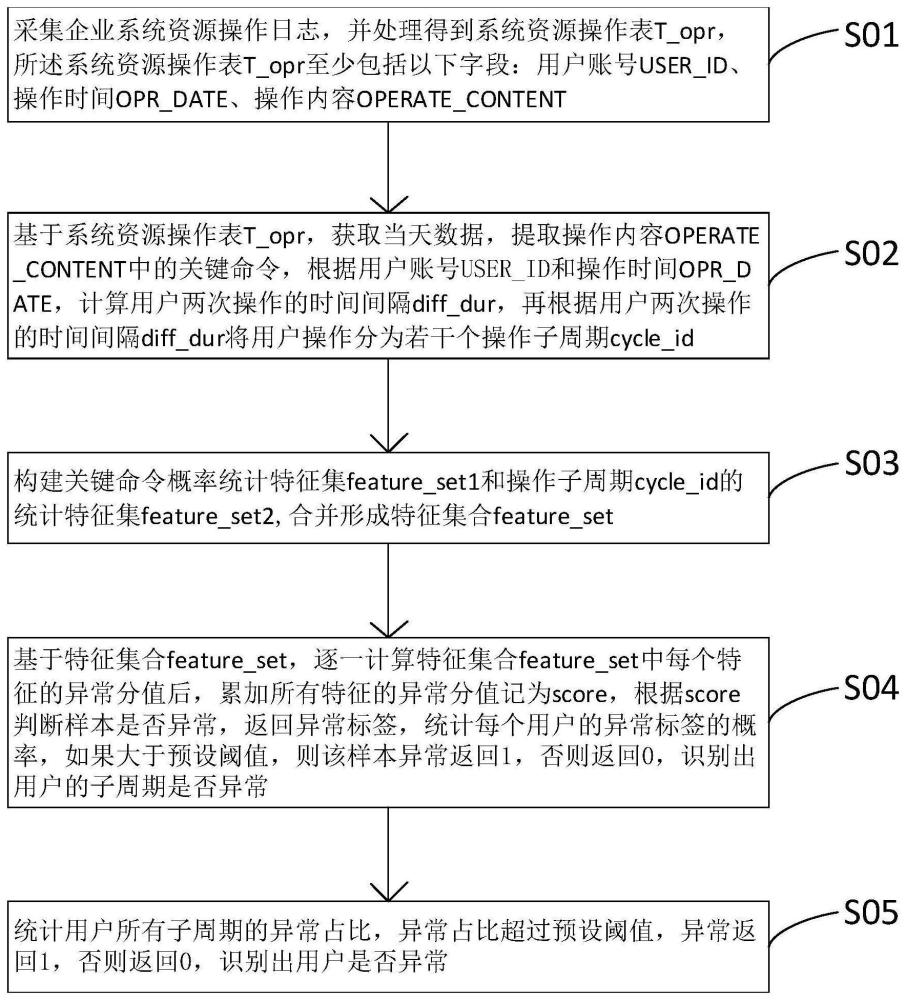
3、s01.采集企业系统资源操作日志,并处理得到系统资源操作表t_opr,所述系统资源操作表t_opr至少包括以下字段:用户账号user_id、操作时间opr_date、操作内容operate_content;
4、s02.基于系统资源操作表t_opr,获取当天数据,提取操作内容operate_content中的关键命令,根据用户账号user_id和操作时间opr_date,计算用户两次操作的时间间隔diff_dur,再根据用户两次操作的时间间隔diff_dur将用户操作分为若干个操作子周期cycle_id;
5、s03.构建关键命令概率统计特征集feature_set1和操作子周期cycle_id的统计特征集feature_set2,合并形成特征集合feature_set;
6、s04.基于特征集合feature_set,逐一计算特征集合feature_set中每个特征的异常分值后,累加所有特征的异常分值记为score,根据score判断样本是否异常,返回异常标签,统计每个用户的异常标签的概率,如果大于预设阈值,则该样本异常返回1,否则返回0,识别出用户的子周期是否异常;
7、s05.统计用户所有子周期的异常占比,异常占比超过预设阈值,异常返回1,否则返回0,识别出用户是否异常。
8、本发明基于系统资源操作日志,通过提取用户的操作命令,构建子周期,从操作指令间的转移概率以及子周期的时间两个维度构建特征,基于概率分布建立无监督异常检测模型,识别用户是否存在异常、子周期是否异常、维度(特征)是否异常,相较于只考虑行为或者只考虑时间维度的方法,准确率得到了提升。
9、优选的,所述步骤s01中系统资源操作表t_opr至少还包括以下字段:日志唯一标识uuid、客户端client_ip、服务端serv_ip。
10、优选的,所述步骤s02中提取操作内容operate_content中的关键命令的方法为:
11、利用正则表达式提取操作内容operate_content中含有的大小写字母,计算大小写字母的长度,如果小于2,则操作内容operate_content不包含关键命令,返回-1,如果大于等于2,则利用正则表达式判断操作内容operate_content是否以大小写字母以及“#”开头,如果不是,则返回-1,如果是,则利用正则表达式提取第一个非汉字、数字的连续字母串作为返回值即操作内容operate_content的关键命令。
12、优选的,所述步骤s02中计算用户两次操作的时间间隔的方法为:
13、根据用户账号user_id和操作时间opr_date,以每个用户的操作时间升序排序,计算同一用户相邻两次操作时间间隔diff_dur。
14、优选的,所述步骤s02中将用户操作分为若干个操作子周期cycle_id的方法为:
15、将所有用户的操作时间间隔diff_dur作为输入,计算每个操作时间间隔diff_dur处于所有操作时间间隔数据分布尾部的概率,概率较大的操作时间间隔diff_dur返回1,即作为操作周期的周期间隔,概率较小的操作时间间隔diff_dur返回0,将返回值记为flag,以用户账号user_id作为分组,以操作时间opr_date升序排序,对flag自上二小累加求和,将用户一天的操作记录分为若干个操作子周期记为cycle_id。
16、优选的,所述计算每个操作时间间隔diff_dur处于所有操作时间间隔数据分布尾部的概率的方法包括:
17、s0231.计算操作时间间隔diff_dur的经验分布概率p(t):其中i为0到n的正整数,n为样本数量,t为操作时间间隔的样本值,ti为第i个操作时间间隔值;
18、s0232.计算所有p(t)值的95分位数记为threshold;
19、s0233.比对操作时间间隔的经验分布概率p(t)对应的对数值是否大于95分位数threshold,大于threshold则记为1,否则记为0。
20、优选的,步骤s03中构建关键命令概率统计特征集feature_set1的方法包括:
21、s0311.统计关键命令operate_command中每一个命令的频次,选取频次top150的命令,形成命令集command_set;
22、s0312.基于系统资源操作表t_opr,筛选出关键命令在命令集中的记录,形成新的操作表t_opr1,按用户账号user_id、操作子周期cycle_id、操作时间opr_date升序排序后,以“,”为分隔符,拼接每个用户账号user_id、子周期的操作命令,形成命令子序列command_seq,进而生成命令子序列集合command_seq_set;
23、s0313.基于命令子序列集合command_seq_set,计算命令间的转移概率,形成转移概率矩阵;
24、s0314.基于转移概率矩阵,计算每个用户的每个子周期的以下特征:最大转移概率max_prob、最小转移概率min_prob、平均转移概率mean_prob、转移概率的偏度skew_prob、转移概率的中位数median_prob、转移概率的宽度range_prob,形成关键命令概率统计特征集feature_set1。
25、优选的,步骤s03中构建操作子周期cycle_id的统计特征集feature_set2的方法为:基于系统资源操作表t_opr,计算每个用户的每个子周期的特征时间跨度cycle_range、每个子周期内操作时间间隔的最大值cycle_max_diff_dur、每个子周期内操作时间间隔的最小值cycle_min_diff_dur、每个子周期内操作时间间隔的平均值cycle_mean_diff_dur、每个子周期内操作时间间隔的峰度cycle_kurt_diff_dur、每个子周期内操作时间间隔的偏度cycle_skew_diff_dur、每个子周期内操作时间间隔的90分位数cycle_90_diff_dur、每个子周期内操作时间间隔的10分位数cycle_25_diff_dur、每个子周期内操作时间间隔的90分位数与10分位数的间隔cycle_percentile_range_diff_dur、每个子周期内操作命令数cycle_command_nums,形成操作子周期cycle_id的统计特征集feature_set2。
26、优选的,所述异常分值的计算过程包括:
27、s0411.计算异常分值样本的偏度值γ:
28、其中i为0到n的正整数,n为样本数量,xi为第i个异常分值样本值,是异常分值样本的平均值;
29、s0412.计算样本的左尾部概率pleft(x)以及右尾部概率pleft(x):
30、
31、其中i为0到n的正整数,n为样本数量,xi为第i个异常分值样本值,x为异常分值的样本值;
32、s0413.根据样本的偏度值加权得到尾部概率pa(x):
33、其中x为异常分值的样本值,pleft(x)为样本的左尾部概率,pleft(x)为样本的右尾部概率,γ为异常分值样本的偏度值;
34、s0414.根据样本的异常评分,计算所有特征的异常分值score:
35、score=max{-loge pleft(x),-loge pright(x),-loge pa(x)*(1+|γ|)},其中x为异常分值的样本值,pleft(x)为样本的左尾部概率,pleft(x)为样本的右尾部概率,pa(x)为样本的尾部概率,γ为异常分值样本的偏度值;
36、s0415.计算异常分值score的90分位数记为score_threshold,比对异常分值score是否大于90分位数score_threshold,大于90分位数score_threshold则记为1,否则记为0。
37、本发明还提供一种基于用户行为序列的异常检测装置,包括:
38、数据采集模块,采集企业系统资源操作日志,并处理得到系统资源操作表t_opr,所述系统资源操作表t_opr至少包括以下字段:用户账号user_id、操作时间opr_date、操作内容operate_content;
39、数据预处理模块,基于系统资源操作表t_opr,获取当天数据,提取操作内容operate_content中的关键命令,根据用户账号user_id和操作时间opr_date,计算用户两次操作的时间间隔diff_dur,再根据用户两次操作的时间间隔diff_dur将用户操作分为若干个操作子周期cycle_id;
40、特征构建模块,构建关键命令概率统计特征集feature_set1和操作子周期cycle_id的统计特征集feature_set2,合并形成特征集合feature_set;
41、第一异常检测模块,基于特征集合feature_set,逐一计算特征集合feature_set中每个特征的异常分值后,累加所有特征的异常分值记为score,根据score判断样本是否异常,返回异常标签,统计每个用户的异常标签的概率,如果大于预设阈值,则该样本异常返回1,否则返回0,识别出用户的子周期是否异常;
42、第二异常检测模块,统计用户所有子周期的异常占比,异常占比超过预设阈值,异常返回1,否则返回0,识别出用户是否异常。
43、本发明提供的的优点在于:本发明基于经验概率分布,通过构建用户操作指令的相关特征以及用户子周期的统计特征,利用经验概率分布,建立无监督模型,判断用户是否存在异常,其中通过概率分布计算异常,提高了运行效率,同时在特征加工时,考虑到用户的操作命令以及子周期的时间两个维度的特征,相较于只考虑行为或者只考虑时间维度的方法,准确率得到了提升。本发明通过提取用户的操作指令,根据业务逻辑构建子周期,从操作指令间的转移概率以及子周期的时间两个维度构建特征,基于概率分布建立无监督异常检测模型,识别用户是否存在异常,不仅能够识别出异常的用户,同样能够定位到用户具体异常的原因,因此具有一定的业务可解释性。
- 还没有人留言评论。精彩留言会获得点赞!