人脸姿态生成方法与流程
本技术涉及计算机视觉,尤其涉及一种人脸姿态生成方法。
背景技术:
1、随着人工智能的发展,合成的人物说话视频得到了越来越多的应用,例如应用于新闻播报、人机交互、培训等场景中模拟真人。
2、目前,通过语音驱动生成人物说话的视频是比较常用的手段,可以实现较为准确的唇形同步,但基于语音驱动生成的人物说话视频中人脸姿态、表情等不够生动,使生成的人物说话视频的真实度较低。
3、因此,如何提高生成的人物说话视频中人脸姿态的丰富性和生动性,以提高人物说话视频的真实度是亟待解决的问题。
技术实现思路
1、为了提高生成的人脸姿态的丰富性和生动性,进而提高生成的人物说话视频的真实度,本技术提供了一种人脸姿态生成方法、装置、电子设备及计算机可读存储介质。
2、第一方面,本技术提供了一种人脸姿态生成方法,包括:
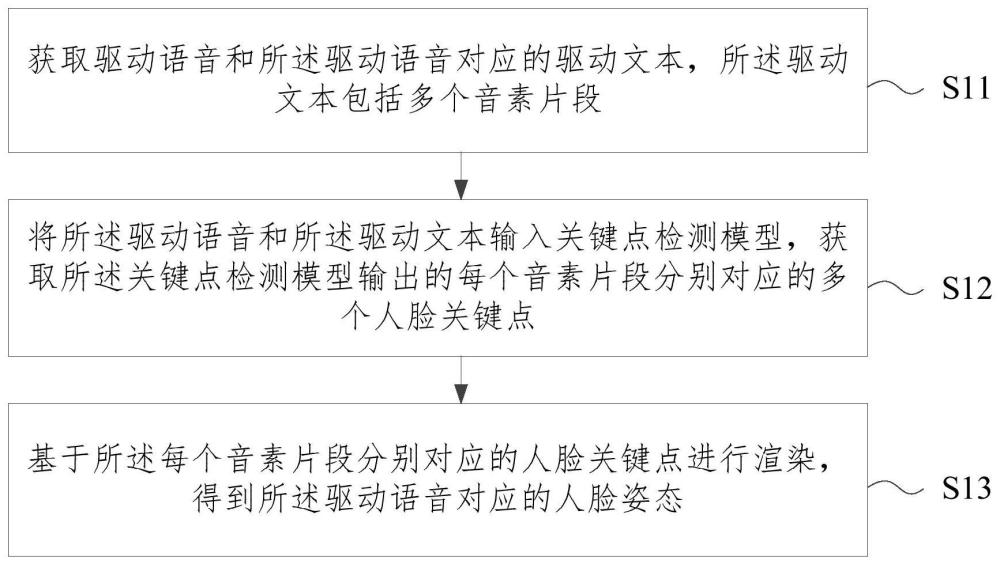
3、获取驱动语音和所述驱动语音对应的驱动文本,所述驱动文本包括多个音素片段;
4、将所述驱动语音和所述驱动文本输入关键点检测模型,获取所述关键点检测模型输出的每个音素片段分别对应的多个人脸关键点;其中,所述关键点检测模型为基于训练样本集对预设模型训练得到的模型,所述训练样本集包括:多帧训练图像、多帧训练图像对应的语音、以及多帧训练图像对应的音素;
5、基于所述每个音素片段分别对应的人脸关键点进行渲染,得到所述驱动语音对应的人脸姿态。
6、作为本技术实施例一种可选的实施方式,所述方法还包括:基于所述训练样本集对预设模型进行训练,得到所述关键点检测模型;
7、所述基于所述训练样本集对预设模型进行训练,包括:
8、基于多帧训练图像、多帧训练图像对应的语音、以及多帧训练图像对应的音素,获取每个训练音素片段分别对应的人脸特征、语音特征、以及文本特征;
9、将所述每个训练音素片段分别对应的人脸特征、语音特征、以及文本特征输入所述预设模型进行训练,以得到所述关键点检测模型。
10、作为本技术实施例一种可选的实施方式,所述预设模型包括编码层和解码层;
11、所述将所述每个训练音素片段分别对应的人脸特征、语音特征、以及文本特征输入所述预设模型进行训练,包括:
12、将所述每个训练音素片段分别对应的人脸特征、语音特征、以及文本特征输入所述编码层进行编码,得到编码向量;
13、将所述编码向量、所述语音特征、以及所述文本特征输入所述解码层,生成所述每个训练音素片段分别对应的预测人脸关键点;
14、根据所述预测人脸关键点的损失调整所述预设模型的参数,对所述预设模型进行训练。
15、作为本技术实施例一种可选的实施方式,所述预设模型还包括:判别器;
16、所述根据所述预测人脸关键点的损失调整所述预设模型的参数,对所述预设模型进行训练,包括:
17、基于所述预测人脸关键点和目标人脸关键点获取均方误差损失;
18、将所述预测人脸关键点输入所述判别器,获取判别损失和交叉熵损失;
19、根据所述均方误差损失、所述判别损失和所述交叉熵损失调整所述预设模型的参数,对所述预设模型进行训练。
20、作为本技术实施例一种可选的实施方式,所述基于多帧训练图像、多帧训练图像对应的语音、以及多帧训练图像对应的音素获取每个训练音素片段分别对应的人脸特征、语音特征、以及文本特征,包括:
21、将所述多帧训练图像输入人脸3d形变统计模型进行特征提取,得到每帧训练图像分别对应的人脸特征;
22、将所述多帧训练图像对应的语音输入hubert预训练模型进行特征提取,得到所述语音对应的语音特征;
23、通过梅尔频谱倒谱对所述多帧训练图像对应的音素进行音素对齐,获取所述音素对应的文本特征;
24、根据对所述多帧训练图像、所述语音、以及所述音素的划分确定每个训练音素片段分别对应的人脸特征、语音特征、以及文本特征。
25、作为本技术实施例一种可选的实施方式,所述根据对所述多帧训练图像、所述语音、以及所述音素的划分确定每个训练音素片段分别对应的人脸特征、语音特征、以及文本特征,包括:
26、以预设步长为单位,对所述多帧训练图像、所述语音、以及所述音素分别进行截取,得到多个训练图像集合、多个语音片段、以及多个训练音素片段;
27、根据所述音素对应的文本特征确定每个训练音素片段分别对应的文本特征,将每个训练音素片段分别对应的训练图像集合的人脸特征确定为该训练音素片段对应的人脸特征,以及将每个训练音素片段分别对应的语音片段对应的语音特征确定为该训练音素片段对应的语音特征。
28、作为本技术实施例一种可选的实施方式,所述方法还包括:
29、获取原始说话视频和所述原始说话视频对应的说话文本;
30、基于所述原始说话视频提取多帧训练图像以及所述多帧训练图像对应的语音,并将所述说话文本转化为音素;
31、将所述多帧训练图像、所述多帧训练图像对应的语音、以及所述多帧训练图像对应的音素作为训练样本集。
32、第二方面,本技术提供一种人脸姿态生成装置,包括:
33、获取模块,用于获取驱动语音和所述驱动语音对应的驱动文本,所述驱动文本包括多个音素片段;
34、检测模块,用于将所述驱动语音和所述驱动文本输入关键点检测模型,获取所述关键点检测模型输出的每个音素片段分别对应的多个人脸关键点;其中,所述关键点检测模型为基于训练样本集对预设模型训练得到的模型,所述训练样本集包括:多帧训练图像、多帧训练图像对应的语音、以及多帧训练图像对应的音素;
35、生成模块,用于基于所述每个音素片段分别对应的人脸关键点进行渲染,得到所述驱动语音对应的人脸姿态。
36、作为本技术实施例一种可选的实施方式,所述装置还包括:
37、训练模块,用于基于所述训练样本集对预设模型进行训练,得到所述关键点检测模型;
38、提取模块,用于基于多帧训练图像、多帧训练图像对应的语音、以及多帧训练图像对应的音素,获取每个训练音素片段分别对应的人脸特征、语音特征、以及文本特征;
39、输入模块,用于将所述每个训练音素片段分别对应的人脸特征、语音特征、以及文本特征输入所述预设模型进行训练,以得到所述关键点检测模型。
40、作为本技术实施例一种可选的实施方式,所述预设模型包括编码层和解码层;
41、所述输入模块,具体用于将所述每个训练音素片段分别对应的人脸特征、语音特征、以及文本特征输入所述编码层进行编码,得到编码向量;
42、将所述编码向量、所述语音特征、以及所述文本特征输入所述解码层,生成所述每个训练音素片段分别对应的预测人脸关键点;
43、所述训练模块,具体用于根据所述预测人脸关键点的损失调整所述预设模型的参数,对所述预设模型进行训练。
44、作为本技术实施例一种可选的实施方式,所述预设模型还包括:判别器;所述训练模块,具体用于基于所述预测人脸关键点和目标人脸关键点获取均方误差损失;
45、将所述预测人脸关键点输入所述判别器,获取判别损失和交叉熵损失;
46、根据所述均方误差损失、所述判别损失和所述交叉熵损失调整所述预设模型的参数,对所述预设模型进行训练。
47、作为本技术实施例一种可选的实施方式,所述提取模块,具体用于将所述多帧训练图像输入人脸3d形变统计模型进行特征提取,得到每帧训练图像分别对应的人脸特征;
48、将所述多帧训练图像对应的语音输入hubert预训练模型进行特征提取,得到所述语音对应的语音特征;
49、通过梅尔频谱倒谱对所述多帧训练图像对应的音素进行音素对齐,获取所述音素对应的文本特征;
50、根据对所述多帧训练图像、所述语音、以及所述音素的划分确定每个训练音素片段分别对应的人脸特征、语音特征、以及文本特征。
51、作为本技术实施例一种可选的实施方式,所述提取模块,具体用于以预设步长为单位,对所述多帧训练图像、所述语音、以及所述音素分别进行截取,得到多个训练图像集合、多个语音片段、以及多个训练音素片段;
52、根据所述音素对应的文本特征确定每个训练音素片段分别对应的文本特征,将每个训练音素片段分别对应的训练图像集合的人脸特征确定为该训练音素片段对应的人脸特征,以及将每个训练音素片段分别对应的语音片段对应的语音特征确定为该训练音素片段对应的语音特征。
53、作为本技术实施例一种可选的实施方式,所述装置还包括:
54、处理模块,用于获取原始说话视频和所述原始说话视频对应的说话文本;
55、基于所述原始说话视频提取多帧训练图像以及所述多帧训练图像对应的语音,并将所述说话文本转化为音素;
56、将所述多帧训练图像、所述多帧训练图像对应的语音、以及所述多帧训练图像对应的音素作为训练样本集。
57、第三方面,本技术实施例提供一种电子设备,包括:存储器和处理器,所述存储器用于存储计算机程序,所述处理器用于在调用计算机程序时执行第一方面或第一方面任一种可选的实施方式所述的人脸姿态生成方法。
58、第四方面,本技术实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面或第一方面任一种可选的实施方式所述的人脸姿态生成方法。
59、本技术实施例提供的技术方案与现有技术相比具有如下优点:
60、本技术实施例提供的人脸姿态生成方法包括:获取驱动语音和所述驱动语音对应的驱动文本,所述驱动文本包括多个音素片段;将所述驱动语音和所述驱动文本输入关键点检测模型,获取所述关键点检测模型输出的每个音素片段分别对应的多个人脸关键点;其中,所述关键点检测模型为基于训练样本集对预设模型训练得到的模型,所述训练样本集包括:多帧训练图像、多帧训练图像对应的语音、以及多帧训练图像对应的音素;基于所述每个音素片段分别对应的人脸关键点进行渲染,得到所述驱动语音对应的人脸姿态。由于每个音素片段对应的人脸姿态为基于该音素片段对应的人脸关键点渲染得到的,因此人脸姿态会随音素片段的变化而变化,与对应的音素片段相适应,进而使在生成的人物说话视频中,人脸姿态跟随驱动语音变化,与驱动语音相适应,提高人脸姿态和表情的生动性,进而提高生成的人物说话视频的真实度。
- 还没有人留言评论。精彩留言会获得点赞!