一种跨模态时域视频定位方法及系统
本发明属于视频定位领域,尤其涉及一种跨模态时域视频定位方法及系统。
背景技术:
1、跨模态时域视频定位旨在给定一段未剪辑视频(模态一)中定位与一条查询文本(模态二)的语义相关的视频片段,定位的视频片段由起始帧和终止帧确定。为保障精准定位效果,需要对视频和文本特征进行深度融合和语义对齐,准确区分相邻视频帧的语义差别。由于其在信息检索、人机交互等领域的巨大应用前景,跨模态时域视频定位任务近年来引起了研究界的重点关注。
2、现有的跨模态时域视频定位方法都遵循了一个固定的模式:首先分别提取视频与文本数据的特征,再对二者进行特征融合,最后利用融合特征进行起止时间的预测。由于用于训练的视频通常过长,现有的方法都固定使用了视频稀疏下采样的预处理流程,按相同间隔将原视频采样处理成长度固定的较短视频作为实际的训练样本,再进行相应的训练。然而,稀疏下采样可能会将原视频中真实的事件开始/结束帧过滤掉,而将与查询事件不相关的视频帧认定为事件的开始/结束位置,这会为定位模型的训练引入偏差,导致视频定位准确度不高。
技术实现思路
1、有鉴于此,本发明实施例提供了一种跨模态时域视频定位方法及系统,用于消除时域视频定位中由视频稀疏下采样引入的偏差,提高视频定位准确度。
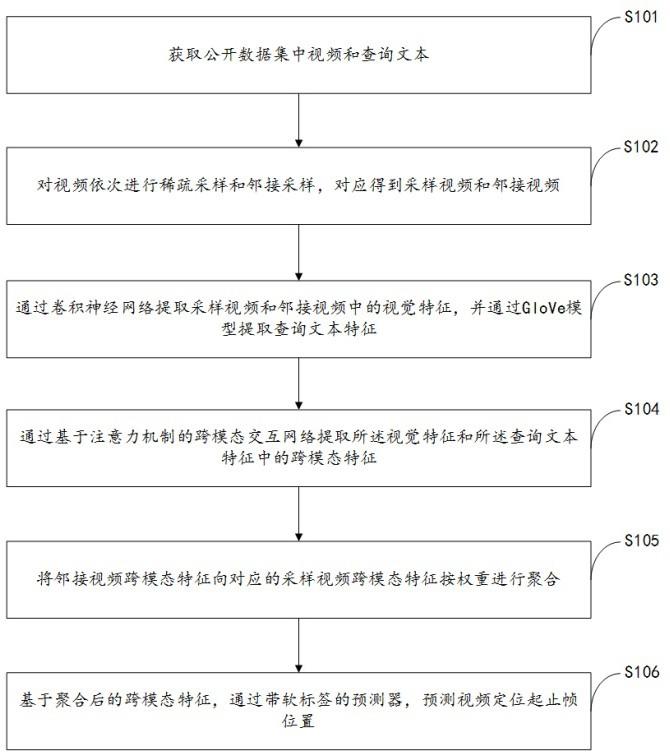
2、在本发明实施例的第一方面,提供了一种跨模态时域视频定位方法,包括:
3、获取公开数据集中视频和查询文本;
4、对视频依次进行稀疏采样和邻接采样,对应得到采样视频和邻接视频;
5、通过卷积神经网络提取采样视频和邻接视频中的视觉特征,并通过glove模型提取查询文本特征;
6、通过基于注意力机制的跨模态交互网络提取所述视觉特征和所述查询文本特征中的跨模态特征;
7、将邻接视频跨模态特征向对应的采样视频跨模态特征按权重进行聚合;
8、基于聚合后的跨模态特征,通过带软标签的预测器,预测视频定位起止帧位置。
9、在本发明实施例的第二方面,提供了一种用于跨模态时域视频定位的系统,包括:
10、数据获取模块,用于获取公开数据集中视频和查询文本;
11、采样模块,用于对视频依次进行稀疏采样和邻接采样,对应得到采样视频和邻接视频;
12、特征提取模块,用于通过卷积神经网络提取采样视频和邻接视频中的视觉特征,并通过glove模型提取查询文本特征;
13、跨模态特征提取模块,用于通过基于注意力机制的跨模态交互网络提取所述视觉特征和所述查询文本特征中的跨模态特征;
14、聚合模块,用于将邻接视频跨模态特征向对应的采样视频跨模态特征按权重进行聚合;
15、预测模块,用于基于聚合后的跨模态特征,通过带软标签的预测器,预测视频定位起止帧位置。
16、在本发明实施例的第三方面,提供了一种电子设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器运行的计算机程序,所述处理器执行所述计算机程序时实现如本发明实施例第一方面所述方法的步骤。
17、在本发明实施例的第四方面,提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现本发明实施例第一方面提供的所述方法的步骤。
18、本发明实施例中,通过对视频进行稀疏采样和邻接采样,并提取采样视频的视觉特征,结合查询文本特征,提取视觉特征和查询特征中的跨模态特征,将邻接采样跨模态特征按权重聚合后,通过带软标签的预测器来预测起止帧位置,从而能消除传统固定稀疏下采样将原视频中真实的事件起止帧过滤而引入的偏差,基于邻接采样及特征聚合可以提高时域视频定位精度,便于准确获取视频中起止帧位置。
技术特征:
1.一种跨模态时域视频定位方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述对视频依次进行稀疏采样和邻接采样,对应得到采样视频和邻接视频包括:
3.根据权利要求1所述的方法,其特征在于,所述通过卷积神经网络提取采样视频和邻接视频中的视觉特征,并通过glove模型提取查询文本特征包括:
4.根据权利要求1所述的方法,其特征在于,所述通过基于注意力机制的跨模态交互网络提取所述视觉特征和所述查询文本特征中的跨模态特征包括:
5.根据权利要求1所述的方法,其特征在于,所述将邻接视频跨模态特征向对应的采样视频跨模态特征按权重进行聚合前包括:
6.根据权利要求1所述的方法,其特征在于,所述将邻接视频跨模态特征向对应的采样视频跨模态特征按权重进行聚合包括:
7.根据权利要求1所述的方法,其特征在于,所述基于聚合后的跨模态特征,通过带软标签的预测器,预测视频定位起止帧位置包括:
8.一种用于跨模态时域视频定位的系统,其特征在于,包括:
9.一种电子设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7任一项所述的一种跨模态时域视频定位方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被执行时实现如权利要求1至7任一项所述的一种跨模态时域视频定位方法的步骤。
技术总结
本发明提供一种跨模态时域视频定位方法及系统,该方法包括:获取公开数据集中视频和查询文本;对视频依次进行稀疏采样和邻接采样,对应得到采样视频和邻接视频;通过卷积神经网络提取采样视频和邻接视频中的视觉特征,并通过GloVe模型提取查询文本特征;通过基于注意力机制的跨模态交互网络提取所述视觉特征和所述查询文本特征中的跨模态特征;将邻接视频跨模态特征向对应的采样视频跨模态特征按权重进行聚合;基于聚合后的跨模态特征,通过带软标签的预测器,预测视频定位起止帧位置。通过该方案可以消除由于视频稀疏采样中过滤掉真实起止帧而引入的采样偏差,有效提高时域视频定位精度。
技术研发人员:周潘,朱佳昊,熊泽雨,徐子川,施嘉雯
受保护的技术使用者:华中科技大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!