一种基于多教师多模态模型的知识蒸馏方法及系统
本发明属于自然语言处理领域,具体是一种基于多教师多模态模型的知识蒸馏方法及系统。
背景技术:
1、受益于transformer架构的成功,最近的视觉语言模型在很多多模态下游任务取得了优异的性能提升。视觉语言模型通常采取单塔和双塔结构,在单塔结构中,图像和文本信息共享一个神经网络塔。这意味着图像编码器和文本编码器的输出共享相同的模型参数,然后通过注意力机制或其他方式将它们融合在一起。在双塔结构中,图像和文本信息分别通过独立的神经网络塔进行编码。这意味着图像编码器和文本编码器具有不同的模型参数,它们在模型中是相对独立的,然后再通过一个目标函数对两种模态信息进行约束,以将两种不同模态的特征信息在一个共享空间表示对齐。
2、但这些优秀的性能多是以高昂的计算代价和较大的参数规模换取的,这同时也带来了高延迟和存储消耗,给现实应用中的部署带来挑战和阻碍。而且这些多模态模型在经过初始化后预训练的过程,在单模态的任务场景存在性能下降。
3、知识蒸馏(knowledge distillation)是一种机器学习技术,旨在将一个复杂的模型的知识转移到一个更小、更简单的模型中,从而减小模型的体积和计算需求,同时保持或提高模型的性能。通过让一个大型的、性能优越的模型(通常称为教师模型)教导一个小型的模型(通常称为学生模型),来实现模型的压缩和加速。这个过程可以被看作是一种迁移学习,其中教师模型的知识被传递给学生模型。
技术实现思路
1、针对现有技术中存在的技术问题,本发明提供了基于多个不同模态的多个教师模型的知识蒸馏方法及系统,可以较好地缓解多模态模型参数规模大,且在单模态任务场景性能下降的问题。本发明能够在大幅降低模型的参数量的情况下,使学生模型尽可能保持与教师模型接近的性能表现,满足在图文检索、图文问答中,纯文本理解、纯视觉理解任务上的需要。
2、本发明采用的技术方案如下:
3、一种基于多教师多模态模型的知识蒸馏方法,其步骤包括:
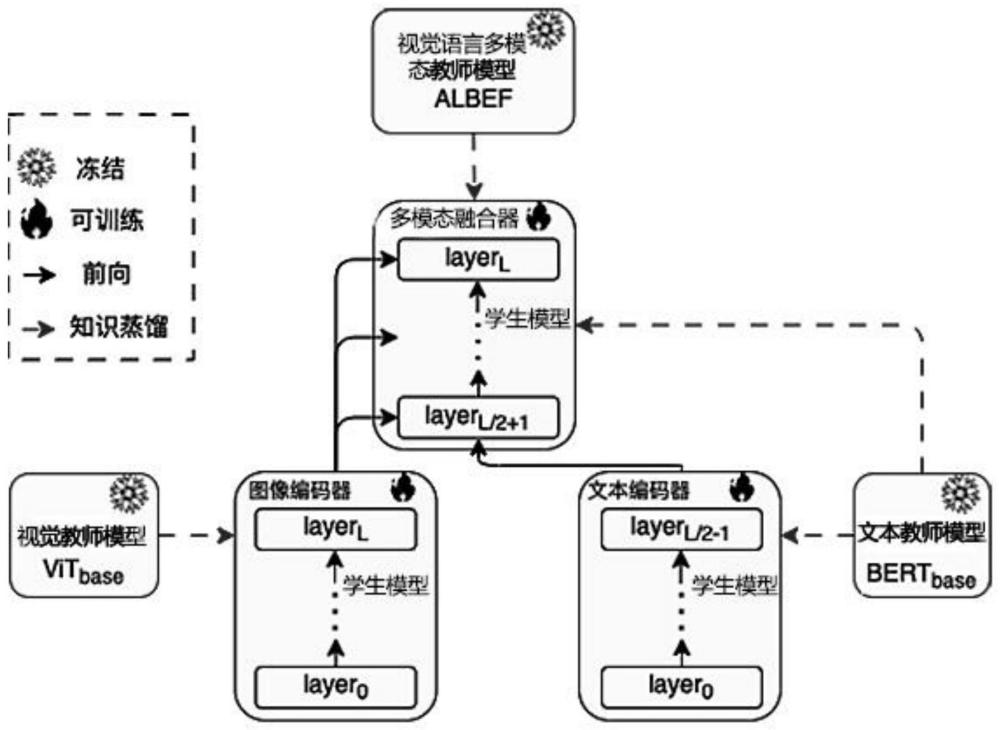
4、1)构建教师模型和学生模型,该教师模型包括视觉语言多模态教师模型、视觉教师模型和文本教师模型;该视觉语言多模态教师模型与该学生模型的模型结构一致,均包含图像编码器、文本编码器和多模态融合器;
5、2)使用视觉语言多模态模型的部分参数对学生模型的参数进行初始化;
6、3)在联合知识蒸馏阶段,基于图像-文本对训练数据的训练学习将觉语言多模态教师模型知识蒸馏到学生模型的多模态融合器,基于图片训练数据的训练学习将视觉教师模型知识蒸馏到学生模型的图像编码器,基于纯文本训练数据的训练学习将文本教师模型知识蒸馏到学生模型的文本编码器,约束学生模型在每次训练的输入、输出和教师模型的输入、输出保持一致;
7、4)在下游任务上通过训练和监督学习,对学生模型进行微调。
8、进一步地,图像编码器采用l层的transformer模型,文本编码器和多模态融合器共同采用同一个l层transformer模型,其中前l/2层作为文本编码器,后l/2层作为多模态融合器;视觉教师模型采用l层的vision transformer模型;文本教师模型采用l层的transformer模型。
9、进一步地,将觉语言多模态教师模型知识蒸馏到学生模型的多模态融合器时,最终的目标函数为四个目标函数即隐层状态表示对齐和注意力矩阵表示对齐分类输出logits输出对齐llogits以及图像-文本对比表示学习litc的总和,即
10、将视觉教师模型知识蒸馏到学生模型的图像编码器时,总的目标函数为两个目标函数即对齐学生模型的图像编码器与视觉教师模型的隐层状态表示和对齐学生模型的图像编码器与视觉教师模型的注意力权重矩阵的总合,即
11、将文本教师模型知识蒸馏到学生模型的文本编码器时,总的目标函数为两个目标函数即对齐学生模型的文本编码器与文本教师模型的隐层状态表示和对齐学生模型的图像编码器与视觉教师模型的注意力权重矩阵的总合,即
12、最终的三种教师模型的联合知识蒸馏的训练目标函数为以上三个总的目标函数的加权之和:
13、
14、其中,0≤λ1,λ2≤1。
15、进一步地,隐层状态表示对齐的目标函数分别表示为:
16、
17、其中,为学生模型的多模态融合器最后一层的输出表示,为视觉语言多模态教师模型的多模态融合器最后一层的输出表示,mse为均方误差函数,通过最小化均方误差来约束学生模型与教师模型的输出保持一致。
18、进一步地,注意力矩阵对齐的目标函数分别表示为:
19、
20、其中,为学生模型的多模态融合器的注意力权重矩阵的输出,为视觉语言多模态教师模型的多模态融合器的注意力权重矩阵的输出,mse为均方误差函数,通过最小化均方误差来约束学生模型与教师模型的输出保持一致。
21、进一步地,logits输出对齐的目标函数表示为:
22、llogits=ce(zs,zt)
23、其中,zs,zt分别为学生模型和教师模型用于分类的输出概率,ce为交叉熵损失函数,通过最小化交叉熵损失来约束学生模型与教师模型的输出保持一致。
24、进一步地,图像-文本对比表示学习的目标函数表示为:
25、
26、其中,τ是温度,s(·)为余弦相似度,n为训练样本数量,为图像编码器的[cls]编码作为的图像特征,为文本编码器的[cls]特征作为的整个文本特征,log的底数为e。
27、进一步地,对齐学生模型的图像编码器与视觉教师模型的隐层状态表示的目标函数为:
28、
29、其中,为学生模型的图像编码器的隐层状态表示,为视觉教师模型的隐层状态表示,mse为均方误差函数,通过最小化均方误差来约束学生模型与教师模型的输出保持一致。
30、进一步地,对齐学生模型的图像编码器与视觉教师模型的注意力权重矩阵的目标函数为:
31、
32、其中,学生模型的图像编码器的注意力权重矩阵,为视觉教师模型的注意力权重矩阵,mse为均方误差函数,通过最小化均方误差来约束学生模型与教师模型的输出保持一致。
33、进一步地,对齐学生模型的文本编码器与文本教师模型的隐层状态表示的目标函数为:
34、
35、其中,为学生模型的文本编码器的隐层状态表示,为文本教师模型的隐层状态表示,mse为均方误差函数,通过最小化均方误差来约束学生模型与教师模型的输出保持一致。
36、进一步地,对齐学生模型的文本编码器与文本教师模型的注意力权重矩阵的目标函数为:
37、
38、其中,学生模型的文本编码器的注意力权重矩阵,为文本教师模型的注意力权重矩阵,mse为均方误差函数,通过最小化均方误差来约束学生模型与教师模型的输出保持一致。
39、一种基于多教师多模态模型的知识蒸馏系统,包括:
40、教师模型,包括视觉语言多模态教师模型、视觉教师模型和文本教师模型,视觉语言多模态教师模型包括图像编码器、文本编码器和多模态融合器,用于在学生模型训练学习时将图像和文本多模态知识蒸馏到学生模型,使学生模型具备与教师模型同等的图文理解能力;
41、学生模型,包括图像编码器、文本编码器和多模态融合器,用于对图文进行理解和处理。
42、本发明的技术方案的优点如下:
43、传统的知识蒸馏方法通常只有一个教师模型,本发明与之不同之处在于,通过多个教师模型联合进行多模态知识蒸馏,这些教师模型具有不同的架构、初始化、训练数据或任务,这种多样性有助于提取不同角度和类型的知识,从而提高了学生模型的鲁棒性,以及对图像、文本和图文多模态的理解能力,提升图像识别的准确性、文本理解的准确性和多模态检索的召回率和准确性。
- 还没有人留言评论。精彩留言会获得点赞!